Оглавление
- Общая информация о GeForce RTX 5080
- Особенности архитектуры Blackwell
- Новый тип видеопамяти — GDDR7
- Трассировка лучей и улучшенная геометрия
- Улучшенная технология увеличения производительности DLSS 4
- Новый тип шейдеров — нейронные шейдеры
- Другие изменения и улучшения
- Предварительная оценка производительности
- Особенности карты Palit GeForce RTX 5080 GameRock (16 ГБ)
- Память
- Особенности карты и сравнение с Palit GeForce RTX 4080 Super GamingPro (16 ГБ)
- Нагрев и охлаждение
- Шум
- Подсветка
- Комплект поставки и упаковка
- Тестирование: синтетические тесты
- Тестирование: игровые тесты
- Конфигурация тестового стенда
- Список инструментов тестирования
- Кратко о производительности в 3D-играх
- Результаты тестирования в 3D-играх
- Рейтинг iXBT.com
- Рейтинг полезности
- Выводы и сравнение энергоэффективности

Общая информация о GeForce RTX 5080
Появление графической архитектуры Nvidia Turing несколько лет назад открыло новую эру графики реального времени, принеся аппаратную трассировку лучей и ускорение искусственного интеллекта в игровую графику и профессиональное ПО. В следующих архитектурах Ampere и Ada Lovelace эти продвинутые возможности обновились, улучшились тензорные и RT-ядра, возможности DLSS и был обеспечен прирост производительности, а в Ada добавилась генерация кадров DLSS и реконструкция лучей на основе нейросети. Со временем трассировка лучей и применение нейросетей в графике стали обычным делом и появились в том числе и на игровых консолях. Применение нейросетей позволило продолжить рост качества изображения, так как традиционные методы ускорения начали ограничиваться естественными пределами, а рендеринг при помощи ИИ прогрессирует куда быстрее. Технология DLSS кратно увеличила частоту кадров, генерируя большинство пикселей при меньших затратах производительности, а реконструкция лучей позволила улучшить освещение при помощи трассировки пути, значительно сократив необходимые расчеты.
Неудивительно, что Nvidia продолжила движение в эту сторону и в новой архитектуре Blackwell, первого представителя которой мы рассмотрим сегодня. В новой архитектуре была еще раз улучшена технология DLSS, появилась многокадровая генерация, обеспечивающая еще бо́льшую частоту кадров и лучшее качество картинки за счет более эффективных ИИ-моделей. Но еще интереснее предлагаемые Nvidia методы нейронного рендеринга для отрисовки разных материалов и объектов. Компания утверждает, что «эра нейронного рендеринга» уже наступила, и хотя они по понятным причинам немного забегают вперед, отрицать всё большее влияние нейросетей на нашу жизнь невозможно. Хотя в мире остается достаточно много адептов всего «настоящего», применение нейросетей при дорисовке картинки позволяет улучшить ее итоговое качество и повысить производительность одновременно. А когда Microsoft добавит возможность применения нейросетей в шейдерах DirectX, разработчики ПО начнут пользоваться этими возможностями еще шире.
Но давайте обо всем по порядку, материал будет большим и покажет немало новых возможностей, открывающихся с новыми GPU. Архитектура Blackwell, включающая игровые и вычислительные графические процессоры, была названа в честь Дэвида Гарольда Блэквелла — американского математика и статистика, известного в качестве одного из авторов теоремы Рао—Блэквелла—Колмогорова, а также другими достижениями в области теории вероятностей, теории игр, статистики и динамического программирования. Первыми видеокартами Nvidia на основе новой архитектуры Blackwell стали модели GeForce RTX 5090, RTX 5080, RTX 5070 Ti и RTX 5070. В основе флагманской модели GeForce RTX 5090 лежит графический процессор GB202, который является самым мощным графическим процессором компании, GeForce RTX 5080 и RTX 5070 Ti основаны на графическом процессоре GB203, ну а GeForce RTX 5070 использует чип GB205.

Мы временно пропускаем топовую модель новой линейки и обязательно вернемся к ней позже, а с возможностями новой архитектуры Nvidia будем знакомиться по GeForce RTX 5080. Это вторая сверху по мощности видеокарта нового поколения, которая способна на всё то же самое, что и флагман, но по вдвое более низкой цене. Она имеет половину объема памяти от GeForce RTX 5090 — 16 ГБ, и шина памяти у нее ровно вдвое меньше — 256 бит, но этого вполне достаточно, чтобы Nvidia рекомендовала использование GeForce RTX 5080 для самых высоких разрешений рендеринга при максимальных графических настройках, включая трассировку лучей и вообще всё, что только можно представить.
По характеристикам GeForce RTX 5080 не слишком сильно отличается от предшествующей GeForce RTX 4080 (Super), в поколении Blackwell компания Nvidia столкнулась с проблемами сложности повышения чистой производительности. Если семейство GeForce RTX 40 сделало большой скачок по техпроцессам и это дало приличный прирост производительности, то у GeForce RTX 50 всё заметно сложнее — даже при том, что серия использует преимущества некоторых передовых технологий, вроде памяти GDDR7 и шины PCI Express 5.0. Но все графические процессоры нового поколения используют тот же самый 5-нанометровый техпроцесс TSMC 4N, что и предыдущее поколение, а без усовершенствований в технологии производства добиться значительного прироста производительности в реальных условиях очень непросто.
Можно повысить производительность при помощи изменения архитектуры, но она и так достаточно продвинута, а просто увеличивать количество блоков тоже не выход. Хотя чисто математическая производительность простых и хорошо распараллеленных задач и растет с увеличением количества блоков ALU, ускорение общей графической производительности при этом не будет линейным, нужно повышать и частоту GPU (что во многом ограничивается возможностями техпроцесса, который не изменился) и производительность остальных частей конвейера. Nvidia сделала шаг в сторону и предлагает прирост производительности не за счет тупой мощности, а при помощи технологий искусственного интеллекта — объединения в кадре объектов, отрисованных традиционным образом при помощи растеризации или трассировки лучей, с дополнениями при помощи генеративного ИИ. Новая графическая архитектура Blackwell как раз оптимизирована для того, чтобы запускать нейросети и рендеринг 3D-графики на GPU одновременно, в том числе благодаря новому аппаратному планировщику.
Нейронный рендеринг в Nvidia называют следующей эрой компьютерной графики. При помощи интеграции нейросетей в процесс рендеринга, можно получить значительный прирост как производительности, так и качества картинки. Применение DLSS — это лишь самое начало большого процесса, когда картинка изначально рендерится в низком разрешении и затем дорисовывается в большее нейросетью, а кадры размножаются при помощи умной ИИ-интерполяции. Даже DLSS уже выросла до того, что пытается имитировать сцену со всеми тенями, отражениями и преломлениями и в некоторых случаях справляется с работой даже лучше традиционного рендеринга, так как имеет информацию еще и из предыдущих кадров. Потенциальные возможности нейросетей очень широки, их внедрение в программируемые шейдеры может изменить процесс еще сильнее — станет возможно эффективнее сжимать текстуры, использовать более реалистичные материалы и сложное освещение, да и многое другое. А некоторые детали, вроде человеческих лиц, можно полностью рисовать при помощи нейросетей на основе очень простых растеризованных изображений.
Мы обязательно поговорим сегодня обо всем этом подробно, но сначала рассмотрим видеокарту GeForce RTX 5080. Она предназначена для тех энтузиастов, которые хотят получить функциональность новой архитектуры и достаточно высокую производительность, но заплатив за это вдвое меньше, чем за флагманскую GeForce RTX 5090. Рассматриваемая сегодня видеокарта предназначена для самых высоких разрешений и максимальных графических настроек, включая самую сложную трассировку лучей. Новинка обеспечит высокую производительность в любых играх, включая проекты с самой продвинутой графикой и применением трассировки пути, лишь в редких играх для этого придется включить технологию DLSS, которая получила значительное улучшение в этом поколении.
Аппаратно графическая архитектура Blackwell не слишком сильно отличается от предыдущей Ada Lovelace, которая, в свою очередь, во многом схожа с архитектурой Ampere, и все эти архитектуры имеют между собой достаточно много общего, так что перед прочтением материала будет полезно ознакомиться и с нашими предыдущими статьями по теме:
- [16.11.22] Обзор видеоускорителя Nvidia GeForce RTX 4080 (16 ГБ)
- [26.10.22] Обзор видеоускорителя Nvidia GeForce RTX 4090 (24 ГБ)
- [10.10.22] Теоретический обзор Nvidia GeForce RTX 4090 и RTX 4080
- [30.09.20] Nvidia GeForce RTX 3090: самое производительное, но не чисто игровое решение
- [16.09.20] Nvidia GeForce RTX 3080, часть 1: теория, архитектура, синтетические тесты

| Графический ускоритель GeForce RTX 5080 | |
|---|---|
| Кодовое имя чипа | GB203 |
| Технология производства | 5 нм (TSMC 4N) |
| Количество транзисторов | 45,6 млрд |
| Площадь ядра | 378 мм² |
| Архитектура | унифицированная, с массивом процессоров для потоковой обработки любых видов данных: вершин, пикселей и др. |
| Аппаратная поддержка DirectX | DirectX 12 Ultimate, с поддержкой уровня возможностей Feature Level 12_2 |
| Шина памяти | 256-битная: 8 независимых 32-битных контроллеров памяти с поддержкой памяти типа GDDR7 |
| Частота графического процессора | до 2617 МГц |
| Вычислительные блоки | 84 потоковых мультипроцессора, включающих 10752 CUDA-ядра для целочисленных расчетов INT32 и вычислений с плавающей запятой FP16/FP32/FP64 |
| Тензорные блоки | 336 тензорных ядер для матричных вычислений INT4/INT8/FP4/FP8/FP16/FP32/BF16/TF32 |
| Блоки трассировки лучей | 84 RT-ядра для расчета пересечения лучей с треугольниками и ограничивающими объемами BVH |
| Блоки текстурирования | 336 блоков текстурной адресации и фильтрации с поддержкой FP16/FP32-компонент и поддержкой трилинейной и анизотропной фильтрации для всех текстурных форматов |
| Блоки растровых операций (ROP) | 14 широких блоков ROP на 112 пикселей с поддержкой различных режимов сглаживания, в том числе программируемых и при FP16/FP32-форматах буфера кадра |
| Поддержка мониторов | HDMI 2.1b и DisplayPort 2.1b |
| Спецификации видеокарты GeForce RTX 5080 | |
|---|---|
| Частота ядра | до 2617 МГц |
| Количество универсальных процессоров | 10752 |
| Количество текстурных блоков | 336 |
| Количество блоков блендинга | 112 |
| Эффективная частота памяти | 30 ГГц |
| Тип памяти | GDDR7 |
| Шина памяти | 256 бит |
| Объем памяти | 16 ГБ |
| Пропускная способность памяти | 960 ГБ/с |
| Вычислительная производительность (FP32) | до 56,3 терафлопс |
| Теоретическая максимальная скорость закраски | 293 гигапикселей/с |
| Теоретическая скорость выборки текстур | 879 гигатекселей/с |
| Шина | PCI Express 5.0 x16 |
| Разъемы | по выбору производителя |
| Энергопотребление | до 360 Вт |
| Дополнительное питание | один 16-контактный разъем |
| Число слотов, занимаемых в системном корпусе | по выбору производителя |
| Рекомендуемая цена | $999 |
Название рассматриваемой новинки соответствует принципу наименования решений компании — GeForce RTX 5080 является последователем дела GeForce RTX 4080 и справедливо получила это цифровое наименование, будучи вторым сверху решением нового поколения. Выше нее только GeForce RTX 5090, а снизу — GeForce RTX 5070 Ti и RTX 5070. Применяемый в модели графический процессор GB203 физически вдвое меньше топового GB202, на котором основан флагман, но при этом в RTX 5080 используется полная версия чипа со всеми доступными в нем исполнительными блоками, в отличие от RTX 5090, так что если RTX 5080 Super или 5080 Ti и выйдет позднее, то Nvidia придется использовать в ней урезанную версию GB202, выжимать из GB203 уже нечего.
Соперников для новой GeForce RTX 5080 на рынке пока что нет, AMD хоть и анонсировала новое поколение видеокарт, но отложило их выпуск по каким-то причинам минимум до марта. Так что чисто номинально пока что условным конкурентом новинки является топовая модель нынешнего семейства — Radeon RX 7900 XTX, близкая к рассматриваемой видеокарте Nvidia и по цене. С учетом того, что RTX 5080 быстрее RTX 4080 Super, особой конкуренции от RX 7900 XTX можно не ждать, особенно при активном применении трассировки лучей.
Выбор видеопамяти для GeForce RTX 5080 в объеме 16 ГБ — это вполне логичное решение. 8 ГБ было бы уже откровенно мало, а еще больший объем с быстрой GDDR7-памятью пока что обошелся бы слишком дорого, поэтому Nvidia выбрала оптимальный вариант с 16 ГБ. Конечно, мы все хотели бы получить 24 ГБ или вроде того, но сделать так не позволяет шина памяти, да и 24 ГБ памяти не слишком помогают тому же Radeon RX 7900 XTX в борьбе даже с RTX 4080 Super, как известно. Так что вариант в 16 ГБ можно считать оптимальным в сложившихся обстоятельствах, этого объема будет вполне достаточно для любых вменяемых применений в ближайшие несколько лет. Наличие большего объема видеопамяти способно принести некоторое преимущество лишь в крайне редких условиях.
Традиционно для Nvidia на западные рынки также было выпущено решение в виде GeForce RTX 5080 Founders Edition производства самой компании. Эта видеокарта имеет один дизайн с топовой моделью GeForce RTX 5090 Founders Edition, не отличаясь от нее ни длиной, ни высотой, ни даже толщиной в два слота. Внешне они отличаются друг от друга разве что наклейками на задней стороне. Система охлаждения RTX 5080 FE также использует двойное сквозное продувание, когда печатная плата уменьшена до минимального размера и размещена в центре, чтобы не мешать вентиляторам, а для вывода на дисплей и слот PCIe применяются отдельные печатные платы маленького размера. Такая конструкция позволяет потокам воздуха от вентиляторов беспрепятственно проходить сквозь ребра радиатора, выводя воздух через заднюю часть. Кулер использует пять тепловых трубок и охлаждает не только сам GPU, но и чипы памяти с элементами цепи питания. Используется более простая система охлаждения по сравнению с жидким металлом и испарительной камерой в RTX 5090, но это и неудивительно — от этого GPU нужно отвести не 575 Вт, а всего 360 Вт.
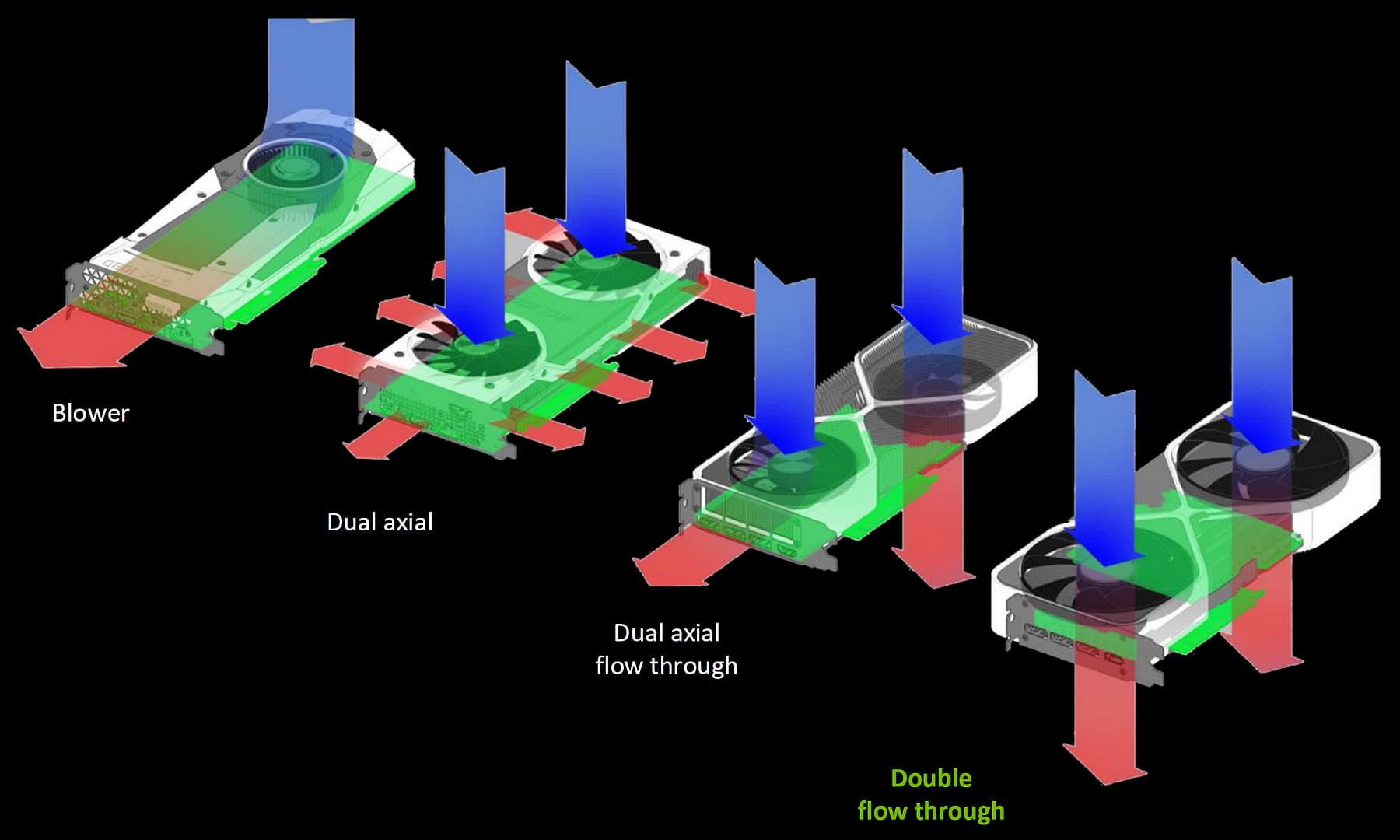
Дополнительное питание видеокарты обеспечивается по привычному 16-контактному разъему в единственном числе, и в комплекте Founders Edition есть переходник с 8-контактных разъемов на 16-контактный — более новой модификации, которая выполнена гораздо качественнее, имеет мягкие кабели и более качественные разъемы. А сам 16-контактный разъем размещен под углом в 45 градусов — как в RTX 3090 FE когда-то. Видеокарта Founders Edition имеет освещенный логотип GeForce RTX и области вокруг воздуховодов по обоим сторонам, и свечение этих светодиодов статично, изменить цвет или яркость невозможно, как и отключить его.
Для подключения дисплеев на карте есть три стандартных разъема DisplayPort 2.1b и один HDMI 2.1b. Пожалуй, единственный напрягающий момент заключается в компактности всей конструкции. RTX 5090 FE все тестеры считают громкой, а RTX 5080 FE хоть и тише флагмана, но всё равно не является достаточно тихой — по причине малого размера системы охлаждения. Впрочем, у пользователя всегда есть выбор: если для него важен небольшой размер видеокарты, то FE будет неплохим выбором, но если нужна по-настоящему тихая система охлаждения, то лучше выбрать трех-четырехслотовые карты партнеров. Одну из таких мы сегодня и тестируем, к слову.

Партнеры компании Nvidia выпустили на рынок множество вариантов GeForce RTX 5080 собственного дизайна, включая разогнанные варианты, имеющие различные системы питания и охлаждения. Модели с обновленным графическим процессором уже доступны в разных модификациях таких компаний, как Asus, Colorful, Gainward, Galaxy, Gigabyte, Innovision 3D, MSI, Palit, PNY, Zotac и многих других.
Особенности архитектуры Blackwell
В линейке видеокарт GeForce RTX 50 применяются графические процессоры GB20x, основанные на новой графической архитектуре Blackwell. Графический процессор GB203, который лежит в основе рассматриваемой модели GeForce RTX 5080, включает в себя все возможности и особенности флагманского GB202, который стал рекордсменом по сложности и размеру для игровых GPU.

К топовому GPU мы еще вернемся, а GB203 очень похож по размеру и количеству транзисторов на AD103 из предыдущего поколения, который используется в GeForce RTX 4080, и это неудивительно, так как чипы имеют схожее количество исполнительных блоков и производятся при помощи одного и того же техпроцесса TSMC — 4N. GB203 имеет площадь кристалла 378 мм² и содержит 45,6 млрд транзисторов — у AD103 площадь кристалла 378,6 мм² и состоит он из 45,9 млрд транзисторов. Применяемый техпроцесс является уже вторым по очереди специализированным вариантом 5-нанометрового EUV-техпроцесса, разработанного тайваньской компанией вместе с Nvidia, и он не слишком отличается от предыдущего, судя по всему. Хотя Apple и Intel уже применяют кристаллы, выполненные по 3-нанометровому техпроцессу на той же TSMC, но у них не такие большие чипы. Использование относительно старого техпроцесса не могло не сказаться на том, какой получилась линейка видеокарт GeForce RTX 50 и насколько сильно она отличается от предыдущей.
Высокоуровневое строение графических процессоров компании Nvidia не изменяется с Ampere. Как и все графические процессоры компании, чип GB203 состоит из укрупненных кластеров Graphics Processing Cluster (GPC), которые включают несколько кластеров текстурной обработки Texture Processing Cluster (TPC), содержащих потоковые процессоры Streaming Multiprocessor (SM), блоки растеризации ROP и контроллеры памяти. Кластер GPC самостоятельно производит основные вычисления внутри кластера, и включает свой движок растеризации Raster Engine, несколько кластеров TPC, состоящих из вдвое большего количества мультипроцессоров SM. Рассмотрим блок-схему графического процессора в его полной конфигурации, и так как Nvidia не предоставила публике диаграмму чипа GB203, нам пришлось перерисовывать имеющуюся схему GB202, убрав всё лишнее и немного переформатировав ее.
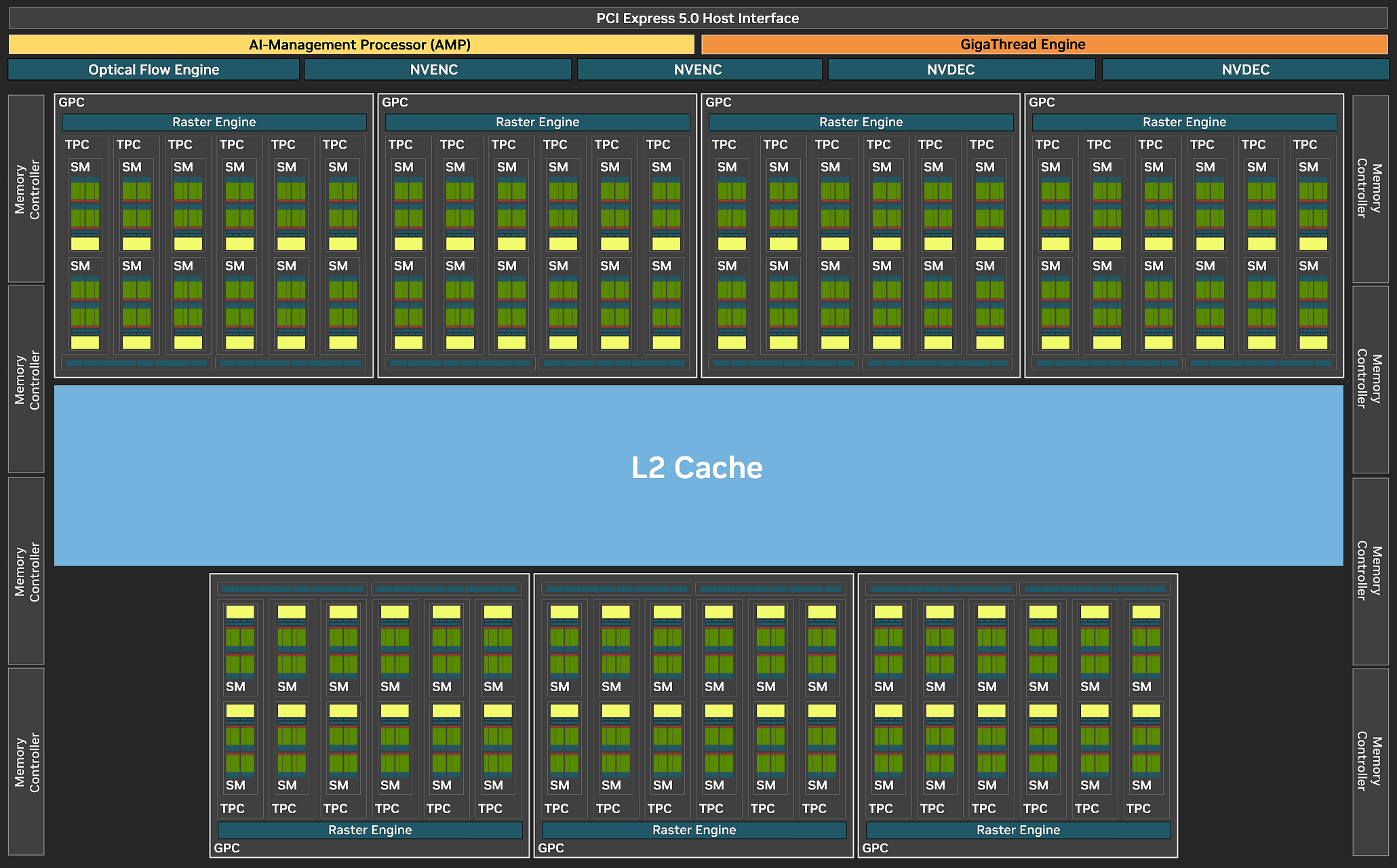
Модель видеокарты GeForce RTX 5080 использует полную версию графического процессора GB203, который содержит семь вычислительных кластеров GPC на 42 кластера TPC, и всего 84 мультипроцессоров SM, и в RTX 5080 активны они все. Так как каждый SM содержит 128 CUDA-ядер, полная версия чипа состоит из 10752 CUDA-ядер, что незначительно больше 10240 в RTX 4080 Super (всего +5% прироста), 84 RT-ядер, 336 тензорных ядер, 336 текстурных блоков TMU и 112 блоков ROP. Даже общий объем L2-кэша не изменился по сравнению с предыдущим поколением и составляет всё те же 64 МБ. Также подсистема памяти содержит L1-кэш объемом 10752 КБ и регистровый файл объемом 21504 КБ, это чуть-чуть больше, чем у AD103.
А вот пропускная способность памяти новинки сильно выросла по сравнению с GeForce RTX 4080. Хотя ширина шины тут та же — восемь 32-битных каналов в сумме на 256 бит, но используется новая GDDR7-память с эффективной частотой в 30 ГГц, и всё это вместе дает аж 960 ГБ/с пропускной способности памяти — на треть больше, чем у RTX 4080 и почти как у RTX 4090. О памяти мы еще поговорим, а пока что рассмотрим внутреннее устройство решений Blackwell. Новые GPU не сильно отличаются от Ada Lovelace по пиковым показателям, если не брать топовый GB202, но в них внедрили большое количество изменений и улучшений, хотя практически все они направлены на будущее.
Каждый кластер GPC в составе графического процессора включает выделенный движок растеризации Raster Engine, по два раздела ROP, каждый из которых содержит по восемь отдельных блоков, а также шесть или восемь кластеров TPC — в зависимости от GPU: в топовом GB202 их восемь, а в рассматриваемом GB203 — шесть. Каждый кластер TPC содержит один движок PolyMorph Engine и два мультипроцессора SM.

Потоковые мультипроцессоры SM являются основными компонентами графических процессоров Nvidia, они обеспечивают параллельное исполнение на различных ядрах (CUDA, Tensor, RT), управляют планированием исполнения варпа и разделены на четыре раздела — каждый с собственным регистровым файлом, планировщиком и диспетчером. Четыре раздела также делят между собой 128 КБ L1-кэша и четыре текстурных модуля TMU.
Разделы мультипроцессора имеют несколько разных вычислительных блоков, включая тензорное ядро и по два набора из 16 блоков ALU — SIMD16. Нового в Blackwell то, что если в Ada Lovelace лишь один из двух блоков SIMD16 умел выполнять целочисленные расчеты, а не только операции с плавающей запятой, теперь оба SIMD стали одинаковыми и умеют исполнять как FP32-операции, так и INT32. Хотя на схемах Nvidia все ALU в разделах SM объединены в один SIMD, на деле их два. Так что строение мультипроцессоров SM изменилось не сильно, это та же схема из двух SIMD, просто они оба теперь состоят из 16 FP32/INT32 блоков. Унифицированные FP32/INT32 ядра могут работать только как FP32- или INT32-ядра каждый цикл. Увеличение целочисленной вычислительной производительности может ускорить некоторые задачи, вроде расчета аргументов, адресов и указателей.

Что касается тензорных ядер, то четыре таких ядра в каждом SM могут исполнять 1024 инструкций FMA с точностью FP16 за такт, и единственное нововведение тут — ускорение вдвое операций над данными с точностью FP4. Других изменений в мультипроцессорах SM не произошло, они всё так же содержат по четыре блока для выполнения специальных функций типа тригонометрических операций, L1-кэш и регистровый файл остались прежними. Так что пиковая производительность Blackwell на такт по сравнению с Ada изменилась лишь для INT32-вычислений — она стала вдвое выше, ну и с матричными FP4-вычислениями произошло то же самое.
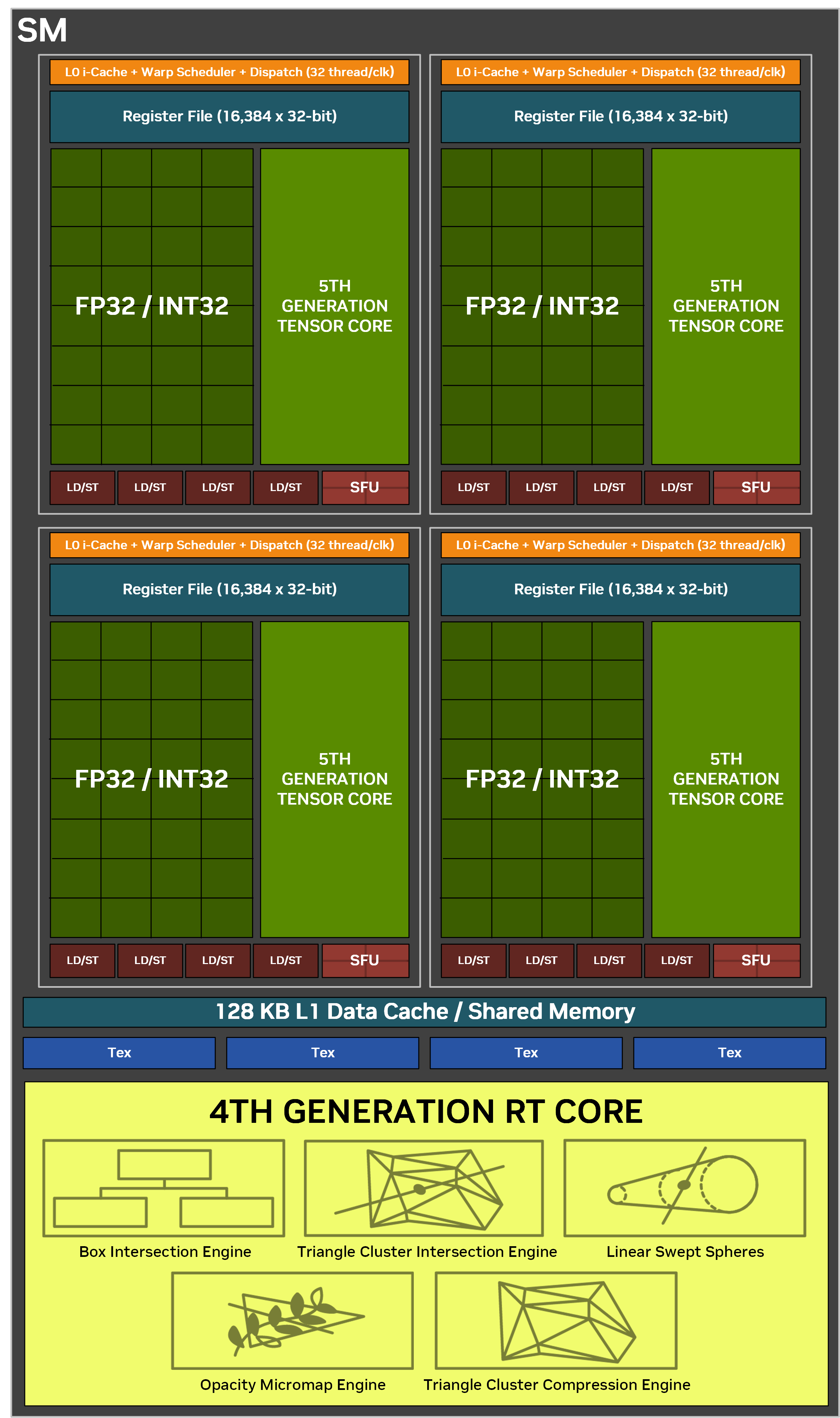
Если мультипроцессор в Ada и предыдущих архитектурах был разработан и оптимизирован для стандартных шейдеров, то в Blackwell дополнительно сделали оптимизации, необходимые для эффективного применения нейронных шейдеров, о которых мы поговорим далее. Мультипроцессоры Blackwell имеют удвоенную производительность точечных выборок из текстур за такт по сравнению с Ada, это помогает ускорить некоторые операции доступа к текстурам в таких алгоритмах, как стохастическая фильтрация текстур, используемая в новых методах нейронного текстурного сжатия.
Тензорные ядра в составе мультипроцессоров специализируются на математических операциях умножения и накопления матриц, используемых в приложениях ИИ и высокопроизводительных вычислениях. Они имеют важное значение для обучения и применения нейросетей. Как и в предыдущих GPU, тензорные ядра Blackwell поддерживают FP16, BF16, TF32, INT8, INT4 и FP8 операции, но впервые была добавлена поддержка операций FP4 меньшей точности.

Генеративные модели ИИ, вроде Stable Diffusion, позволяют создавать изображения на основе текстового описания, и с ростом сложности и масштаба моделей они предъявляют всё более высокие требования к скорости вычислений. В тензорные ядра семейства Blackwell была добавлена родная поддержка FP4-вычислений. При этом используется менее точное квантование, уменьшающее размеры моделей, и по сравнению с FP16 (точность по умолчанию), поддерживаемой большинством моделей, использование FP4 позволяет вдвое снизить требования к объему памяти, что позволяет графическим процессорам RTX 50 обеспечить вдвое более высокую производительность по сравнению с GPU предыдущего поколения при использовании сниженной точности.
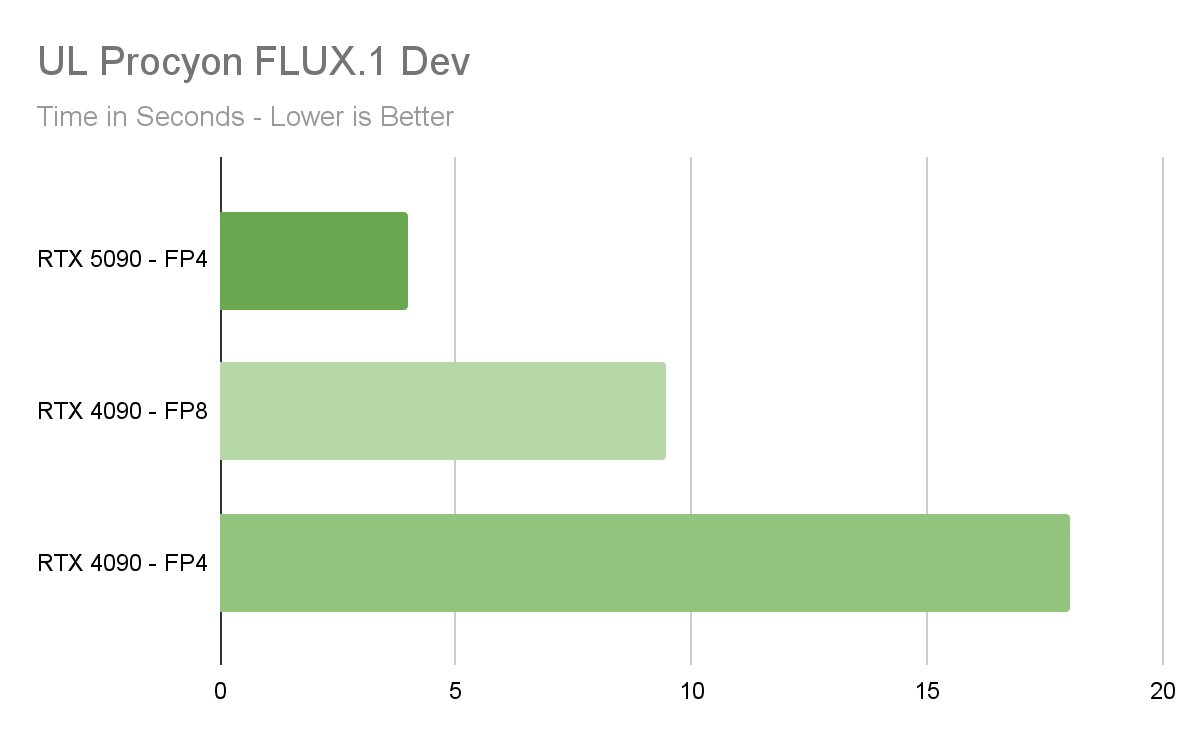
Вариант подойдет не для всех случаев, но из-за использования качественного квантования в TensorRT Model Optimizer, по заявлению Nvidia это не приносит большой потери качества итогового вывода, а скорость увеличивает при меньших требованиях к памяти. Например, модель FLUX.dev (Black Forest Labs) при использовании FP16 требует более 23 ГБ видеопамяти, и ее могут запустить лишь обладатели GeForce RTX 4090 и профессиональных графических процессоров с равным или большим объемом видеопамяти. С FP4 же для запуска FLUX.dev потребуется менее 10 ГБ, и ее можно запустить локально на куда большем количестве видеокарт GeForce RTX, имеющих от 12 ГБ видеопамяти.

И если на GeForce RTX 4090 с точностью FP16 модель FLUX.dev генерирует изображения с определенными параметрами за 15 секунд, то GeForce RTX 5090 с FP4 точностью генерирует такое же изображение уже за пять секунд — неплохое ускорение, особенно когда речь зайдет о минутах или даже часах работы. И хотя запуск моделей ИИ с точностью FP4 поддерживается и на старых графических процессорах Nvidia, только на решениях Blackwell это имеет смысл, так как они имеют встроенную поддержку операций FP4, а на более старших GPU исполняются в режиме эмуляции даже с более низкой скоростью по сравнению с FP8.
Новый тип видеопамяти — GDDR7
Одним из важных нововведений GeForce RTX 50 стала поддержка видеопамяти GDDR7, обеспечивающая более высокую пропускную способность. Nvidia уже много лет сотрудничает с компанией Micron для разработки передовых технологий графической памяти. Для GPU архитектуры Ampere, Nvidia и Micron выпустили память GDDR6X и работали в дальнейшем, чтобы обеспечить еще более высокую скорость для решений Ada. В результате была достигнута эффективная скорость GDDR6X-памяти до 22,4 Гбит/с, а флагманская видеокарта GeForce RTX 4090 имела пропускную способность памяти до 1 ТБ/с. Решения архитектуры Blackwell получили поддержку нового стандарта памяти GDDR7, использующей технологию передачи сигналов PAM3 (Pulse Amplitude Modulation) — компромиссного решения между технологиями передачи сигнала PAM4 и PAM2.
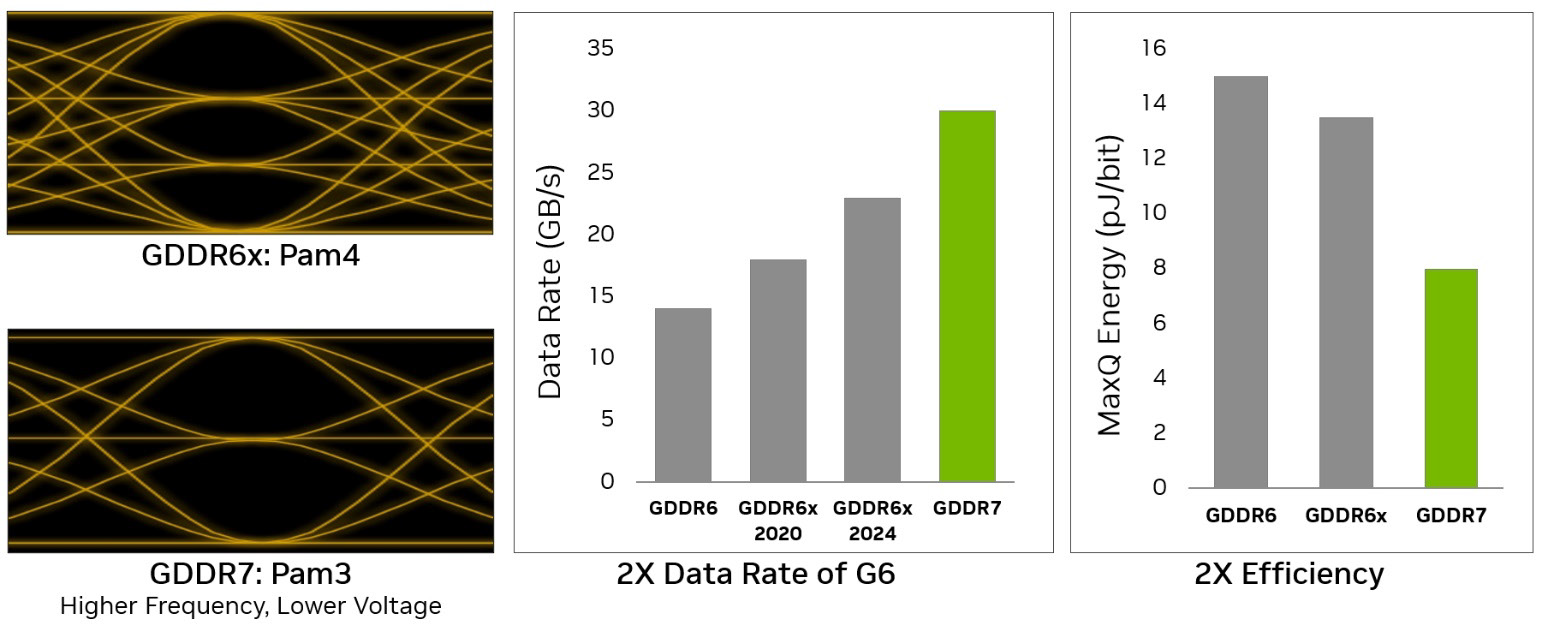
Новый стандарт памяти отличается от GDDR6 и GDDR6X, которая применялась только Nvidia. Интерфейс памяти GDDR до шестой версии кодирует сигнал амплитудно-импульсной модуляцией с двумя уровнями сигнала — PAM2, а видеопамять GDDR6X различает уже четыре уровня сигнала, передавая два бита за цикл при помощи кодирования PAM4. Этот стандарт не может работать на такой высокой скорости, как GDDR6, и на практике память двух стандартов по скорости передачи данных была близкой. Так как GDDR6X в целом сложнее и отличается повышенным энергопотреблением, то потребовалась разработка совершенно нового стандарта — GDDR7. Эта память стандартизирована JEDEC, и ее выпускают уже сразу несколько компаний, а не одна Micron. Новый интерфейс использует что-то среднее между кодированием PAM2 и PAM4 с тремя уровнями сигнала, передавая три бита данных за два цикла. Но главное, что новая память не такая требовательная к отношению сигнал/шум как GDDR6X, поддерживает коррекцию ошибок и использует пониженное напряжение.
Из-за этих изменений, GDDR7 обеспечивает существенно более высокую пропускную способность по сравнению с предыдущими технологиями, усовершенствования также обеспечивают и заметное повышение энергоэффективности, предлагая отличную производительность при относительно невысоком потреблении энергии, чем не могла похвастать GDDR6X. В итоге видеокарты семейства GeForce RTX 50 имеют GDDR7-память со скоростью до 30 Гбит/с, а новый флагман обеспечивает пиковую пропускную способность памяти в 1,792 ТБ/с. Рассматриваемая сегодня GeForce RTX 5080 комплектуется 30 Гбит/с памятью GDDR7, которая обеспечивает пиковую пропускную способность памяти 960 ГБ/с — почти как у предыдущего флагмана.
Трассировка лучей и улучшенная геометрия
Nvidia постоянно работает для увеличения производительности аппаратной трассировки лучей, как по сырой производительности, так и предлагая новую функциональность, расширяющую возможности этих блоков. RT-ядра в графических процессорах Nvidia включают выделенные аппаратные блоки для ускорения обхода структур данных Bounding Volume Hierarchy (BVH) и выполнения проверки пересечения луча с треугольником и пересечения луча и ограничивающего прямоугольника. Из-за того, что основные функции трассировки лучей выполняются выделенными аппаратными блоками, от этой работы высвобождаются мультипроцессоры SM, выполняющие другие задачи — пиксельные, вершинные и вычислительные шейдеры.

Проверка пересечения луча и треугольника — это вычислительно затратная операция, которая очень часто выполняется при рендеринге сцены с трассировкой лучей. По заявлению Nvidia, уже четвертое поколение RT-ядер в архитектуре Blackwell обеспечивает вдвое большую производительность при проверке пересечений луча и треугольника по сравнению с Ada Lovelace, а количество тестов пересечения с ограничивающими боксами Nvidia не разглашает. RT-ядра Ada и Blackwell включают и специальный блок Opacity Micromap Engine, который ускоряет проверку пересечений для полупрозрачных объектов, значительно сокращая необходимые шейдерные вычисления. Также новые RT-ядра в Blackwell содержат новый блок Triangle Cluster Intersection Engine, ускоряющий трассировку лучей при использовании Mega Geometry, и блок Linear Swept Spheres для аппаратно-ускоренной трассировки тонкой геометрии, такой как волосы.
Mega Geometry — это новая технология компании, состоящая из новых расширений API RTX и возможностей аппаратных блоков Blackwell, направленная на значительное увеличение геометрической детализации для приложениях с применением трассировки лучей. Технология позволяет игровым движкам, использующим современные системы уровня детализации, такие как Nanite в Unreal Engine 5, трассировать лучи для всей геометрии с полной точностью без необходимости отката к упрощенному варианту геометрии. Количество треугольников в игровых сценах постоянно растет, а с появлением системы рендеринга геометрии Nanite, разработчики начали создавать большие открытые миры, заполненные сотнями миллионов треугольников. И при росте сложности игровых сцен в геометрической прогрессии, стоимость построения иерархии структур BVH для различных уровней детализации растет слишком сильно, что делает практически невозможным достижение достаточно высокой частоты кадров при трассировке лучей. Каждый скачок уровня детализации усложняет генерацию ускоряющих структур BVH, используемых при трассировке, поэтому обычно используется упрощенную геометрию.
Технология Mega Geometry ускоряет построение BVH и позволяет использовать сотни миллионов анимированных треугольников, она позволяет обновлять определенные кластеры треугольников на GPU по несколько партий, снижая нагрузку на CPU. Mega Geometry скоро появится в специальной Nvidia RTX версии Unreal Engine (NvRTX), и игровые разработчики смогут использовать Nanite с полной трассировкой лучей для каждого треугольника. В существующих играх поддержка мегагеометрии ожидается в будущем в Alan Wake 2.
Есть две главных проблемы, мешающих интеграции трассировки лучей в системы типа Nanite, и Mega Geometry способна решить их обе. Первая — обновления уровней детализации (Level of Detail — LOD) на основе кластеров. Игровые движки обычно изменяют уровень детализации объектов в зависимости от их расстояния до камеры, и в динамике количество треугольников в объекте меняется. Традиционные методы используют ограниченное количество уровней разной геометрической сложности, но системы вроде Nanite обновляют уровень детализации, постепенно заменяя геометрию небольшими партиями примерно по 128 треугольников — кластерами. Конфигурация кластеров, составляющих геометрическое представление объекта, может меняться каждый кадр, что нужно для плавного изменения детализации, но для трассировки лучей нужно построить еще и отдельную структуру данных — иерархию ограничивающих объемов (BVH). И многочисленные сборки BVH, которые Nanite запускает при большом количестве объектов с большим количеством полигонов, способны перегрузить все возможные реализации аппаратной трассировки лучей — производительность нынешнего оборудования для этого явно недостаточна.
Технология Mega Geometry дает новые возможности при построении структур BVH, принимающие кластеры из треугольников в качестве примитивов — новые структуры ускорения на уровне кластера (Cluster-level Acceleration Structures — CLAS), которые могут быть сгенерированы из партий до 256 треугольников. Набор CLAS используется в качестве входных данных для построения BVH и может быть сгенерирован по требованию при загрузке объекта в память, а затем он кэшируется для использования в будущих кадрах. Так как каждый CLAS состоит из одной-двух сотен треугольников, то требуемое для обработки время по сравнению с классическими методами на основе треугольников снижается на порядки. Игровой движок может обрабатывать переключения уровней детализации, реконструируя структуры BVH из CLAS.
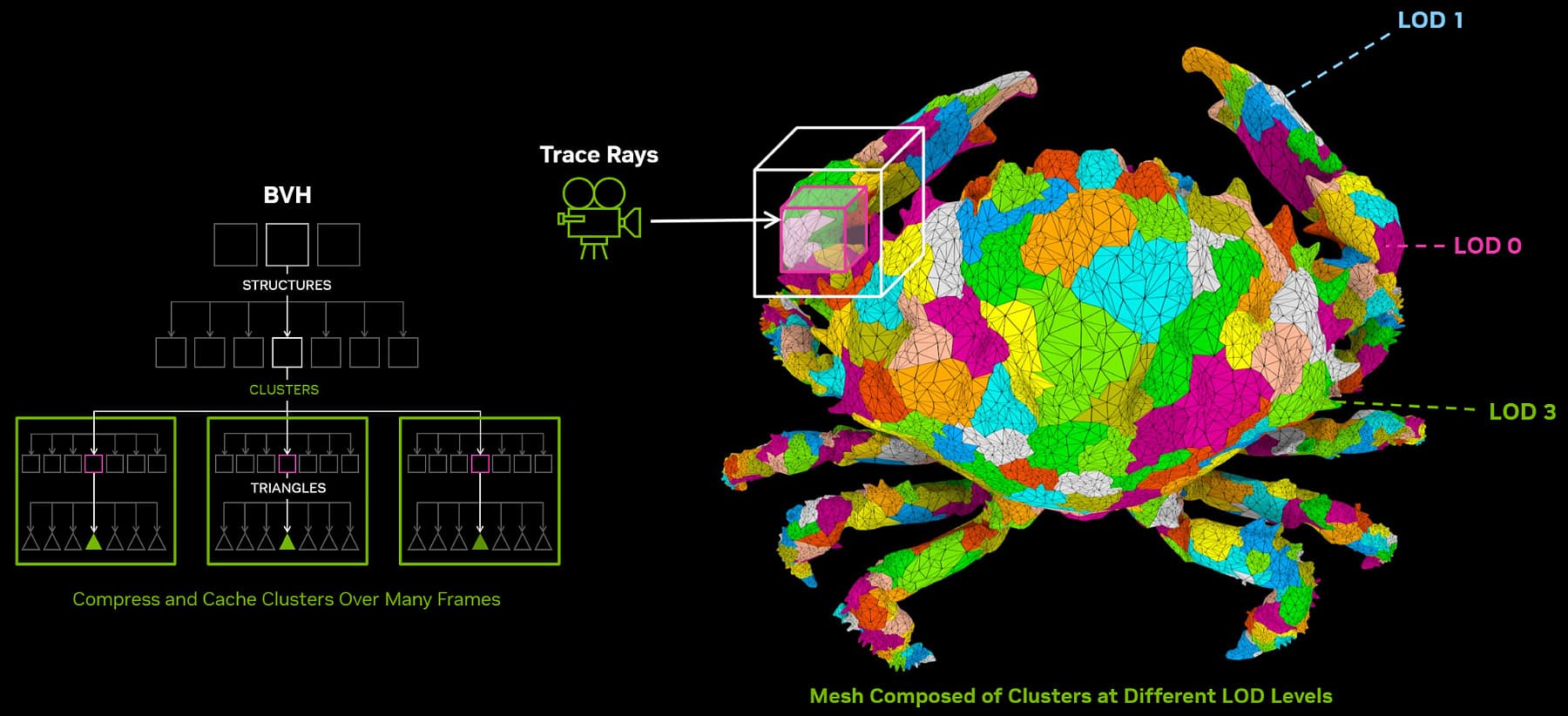
Все API технологии Mega Geometry разработаны с учетом пакетной обработки, все их входные параметры находятся в памяти GPU, что позволяет игровому движку эффективно выполнять подбор уровня детализации, делать анимацию, отбрасывание невидимых объектов и т.п. прямо на GPU, минимизируя расчеты на CPU. Таким образом Mega Geometry может почти исключить использование ресурсов CPU, связанное с управлением структурами BVH. Заодно сокращается и требуемый объем видеопамяти — например, при использовании Nanite из Unreal Engine 5 сразу на несколько сотен мегабайт, по оценке Nvidia.
Гибкая генерация кластеров в GPU вместе с быстрым построением структур BVH, открывает и другие новые возможности, вроде применения других типов представления геометрии — например, разбиваемых поверхностей Subdivision Surfaces, давно применяемых в приложениях серьезного рендеринга, зачастую с применением карт смещения, которые отличаются высоким качеством поверхностей при сохранении высокой эффективности моделирования и анимации. В профессиональной 3D графике давно используется алгоритм разбиения поверхностей, который воссоздает криволинейные поверхности при помощи рекурсивного усложнения сетки из полигонов. При аппаратной трассировке поверхности Subdivision Surfaces придется разбить кривые поверхности на треугольники (тесселяция), что повлечет усложнение структур BVH и их перестроение каждый кадр, что можно ускорить при помощи тех же полигональных кластеров CLAS, кэшированных в памяти.
Трассировка лучей таких поверхностей обычно предваряется их тесселяцией в треугольники — для аппаратного ускорения на GPU в более привычном представлении. И при анимации или смене точки обзора требуется тесселировать объект еще и еще, что приводит к большому количеству обновлений BVH, что снижает производительность. Возможности Mega Geometry позволяют приложению прямо сопоставлять тесселяцию с генерацией кластеров и быстро строить BVH из структур CLAS, что повышает производительность и открывает возможность применения такого представления геометрии в приложениях реального времени с использованием аппаратной трассировки лучей.
Мешает эффективному использованию трассировки лучей и большое количество объектов в сцене. Игровые движки, использующие высокую геометрическую детализацию, обычно применяют и большое количество различных объектов, и приходится строить ускоряющие структуры верхнего уровня TLAS из всех объектов в сцене в каждом кадре, что неплохо работает с количеством объектов до нескольких тысяч, но не более. Для решения проблемы Mega Geometry представляет новый тип структуры верхнего уровня — Partitioned Top-Level Acceleration Structure (PTLAS). Вместо того, чтобы строить новый TLAS с нуля каждый кадр, PTLAS использует то, что большинство объектов в сцене могут быть статичными. Это позволяет упростить генерацию структур BVH — приложению дается прямой доступ к BVH, и графический процессор выполняет некоторую работу над ней, пользуясь этими изменениями в дальнейшем. Неизменные объекты в сцене можно вынести в разделы BVH и не перестраивать их без необходимости.
Также в новых RT-ядрах появилась возможность проверки пересечения луча с геометрическим примитивом Linear Swept Spheres (LSS), предназначенным для моделирования волос, меха, травы и т.п. Для изображения подобных объектов из прядей рендерерами обычно используются различные разновидности примитивов из кривых. При трассировке лучей они обычно реализуются программно с использованием пользовательских шейдеров, что требует больших вычислительных затрат, ограничивающих применение таких деталей. Можно использовать и приблизительные варианты, вроде текстурированных карт, но это ухудшает качество изображения. Лучший метод состоит в моделировании отдельных прядей при помощи треугольников, тогда качество выше, но есть свои недостатки и там. В предлагаемой Nvidia схеме используются сферы в линейных сегментах, эти примитивы поддерживаются Blackwell аппаратно, и такой рендеринг волос осуществляется до двух раз быстрее, а для хранения геометрии требуется в несколько раз меньше видеопамяти.
Применение Mega Geometry выводит возможности трассировки на новый уровень, позволяя использовать куда более эффективный геометрический конвейер по сравнению с традиционным. Технология Mega Geometry уже доступна во всех API трассировки лучей, поддерживаемых Nvidia: DirectX 12 — через NVAPI с поддержкой кластеров и PTLAS, Vulkan — через расширения Nvidia для кластеров и PTLAS, OptiX 9.0 с родной поддержкой кластеров. Пока что всё это собственные API компании, а в стандартных Direct3D и Vulkan этих возможностей нет, но Nvidia наверняка работает над этим.
А напоследок самое главное и приятное — технологии Mega Geometry поддерживаются всеми графическими процессорами RTX, начиная с Turing, пусть и с различной производительностью и эффективностью. Но естественно, что RT-ядра четвертого поколения в Blackwell специально созданы для более эффективной работы Mega Geometry, они имеют специальные кластерные движки для реализации новых схем сжатия геометрии и обработки BVH, хотя и предыдущие GPU справятся с работой.
Улучшенная технология увеличения производительности DLSS 4
Неудивительно, что с новым поколением графической архитектуры улучшилась и технология DLSS, получившая уже четвертую версию. Если в Ada Lovelace появилась генерация промежуточного кадра, то в новом поколении таких кадров нейросеть способна вставить уже нескольких — на данный момент до трех. Алгоритм генерации кадров также изменился и выполняется быстрее, расходуя меньше видеопамяти по данным Nvidia. DLSS 4 при помощи многокадровой генерации позволяет добиться в несколько раз большей частоты кадров по сравнению с традиционным рендерингом, и обеспечить максимальное качество трассированной картинки для 4K-разрешения при 240 FPS.

Генерация дополнительного кадра в DLSS 3 использует данные из игры, такие как векторы движения и глубина пикселей, а также оптический ускоритель потока для генерации одного дополнительного кадра. Многокадровая генерация MFG в DLSS 4 объединяет новые аппаратные возможности Blackwell и новую программную модель, которая работает на 40% быстрее и использует на 30% меньше видеопамяти. Она запускается только один раз на каждый отрисованный кадр для генерации сразу нескольких дополнительных кадров, а в реализации DLSS 3 FG потребовалось бы запускать ее многократно. Но и при генерации одного кадра у новой модели есть преимущество — она обеспечивает чуть более высокую частоту кадров при использовании меньшего объема памяти.
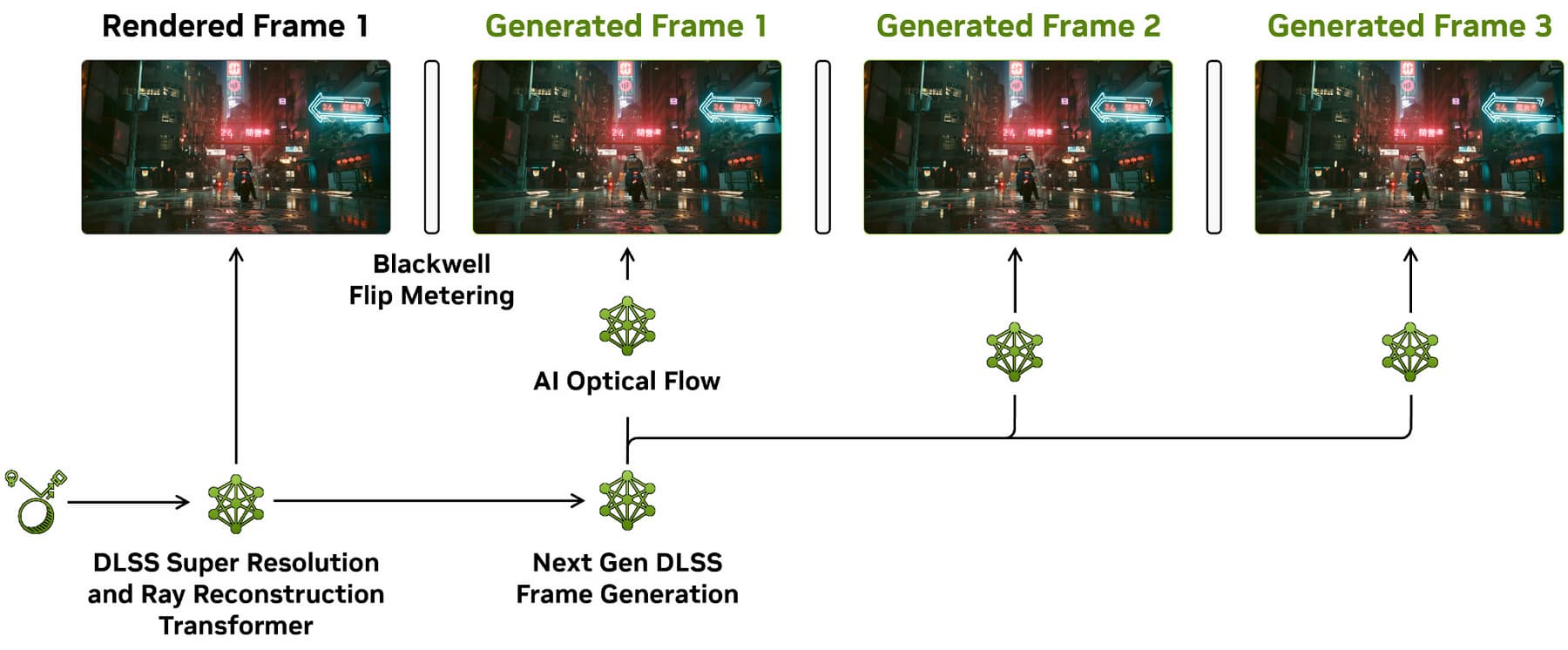
Для эффективной работы многокадрового генератора нужны блоки, появившиеся в Blackwell — это и улучшенные тензорные ядра с увеличенной производительностью, и AI Management Processor для эффективного распределения нагрузок ИИ и рендеринга по исполнительным ядрам GPU. Графическому процессору необходимы пять моделей ИИ для суперразрешения, реконструкции лучей и генерации нескольких кадров для каждого отрисованного кадра, и всё это нужно сделать за несколько миллисекунд. Генерация кадров в DLSS 3 использовала синхронизацию вывода кадров на экран при помощи CPU, что приводило иногда к нестабильной частоте кадров и неплавному выводу, для улучшения этого при генерации сразу нескольких кадров в Blackwell внедрили аппаратный блок Flip Metering, позволяющий более точно управлять синхронизацией дисплея.
Мы уже неоднократно писали, что генерация кадров хотя и действительно заметно уплавняет видеоряд (кадров в секунду становится больше), но не снижает задержки ввода, которые зависят от времени между полноценными кадрами, полностью отрисованными игровым движком. Так что FG и MFG действительно делает все более плавным и комфортным на взгляд, но отзывчивость не улучшается, если настоящая частота кадров ниже определенной величины комфорта. Конечно, это зависит от игры, иногда достаточно 30-40 FPS, а иногда нужны 60 FPS. Генерация же кадров даже немного увеличивает время этой реакции, так как требует работы GPU над этими сгенерированными кадрами, так что задержки могут даже незначительно возрасти. Для решения проблемы используется обновленная технология Reflex, получившая вторую версию — в ней может использоваться смещение кадра в зависимости от действий игрока перед его отправкой на дисплей.

Reflex — это технология для снижения задержки в соревновательных играх, которая была выпущена еще в 2020 году. Технология использует синхронизацию работы CPU и GPU, и действия игрока выводятся на дисплей быстрее, давая преимущество в многопользовательских играх — эта технология за четыре года была интегрирована в более чем сотню игр. Скоро в популярных играх появится вторая версия технологии — Reflex 2, которая может сократить задержку вывода еще сильнее. В Reflex 2 сочетается уже известный режим Reflex Low Latency с новой технологией Frame Warp, известной по VR, где также нужны минимальные задержки, которая еще больше сокращает задержку при помощи обновления кадра на основе информации о действиях игрока прямо перед отправкой кадра на дисплей.
Также в DLSS 4 было сделано крупное обновление во всех технологиях: Ray Reconstruction, Super Resolution и DLAA. Если ранее DLSS использовала сверточные нейронные сети (CNN) для генерации новых пикселей при помощи анализа локализованного контекста и отслеживания изменений в последовательных кадрах, то новая модель трансформер точнее оценивает важность каждого пикселя и в кадре и в нескольких кадрах. Модели, используемые в DLSS 4, принимают на входе вдвое больше параметров для более глубокого понимания сцены и используют большую вычислительную мощность тензорных ядер при реконструкции изображений с лучшим качеством в статике и динамике. Новая модель трансформер генерирует изображение более высокого качества, эффективнее выполняя распознавание крупных паттернов, а также лучше масштабируется.
Особенно хорошо заметно повышение качества в играх с трассировкой лучей, в которых новая модель трансформер обеспечивает значительное улучшение качества при реконструкции лучей и в сложных условиях освещения. Например, в сценах из игры Alan Wake 2 куда лучше отрисовывается сетчатое ограждение, снижено двоение и смазывание изображения на крутящихся лопастях вентилятора и других движущихся объектах, а также устранено мерцание тонких линий электропередач. А в игре Horizon Forbidden West новая модель ИИ улучшает детализацию текстур на одежде и аксессуарах главной героини, а также обеспечивает лучшую четкость в целом:
Реконструкция лучей повышает качество изображения при использовании возможностей ИИ для генерации дополнительных пикселей в сценах с интенсивной трассировкой лучей — DLSS заменяет работу шумодавов обученной нейросетью, которая генерирует более качественные пиксели. Чем сложнее и интенсивнее трассировка лучей в сцене, тем больший прирост качества будет от смены модели, особенно хорошо это заметно в сценах со сложным освещением. Модель трансформер для масштабирования Super Resolution показывает отличные результаты на деле, обеспечивая лучшую временную стабильность, меньшее количество ореолов и более высокую детализацию при движении.
И многокадровая генерация и новые модели трансформеров могут использоваться в играх, уже поддерживающих более ранние версии DLSS, и на видеокартах серии GeForce RTX 50 их можно использовать сразу во многих играх и приложениях. Среди них такие известные проекты, как Alan Wake 2, Cyberpunk 2077, Indiana Jones and the Great Circle, Star Wars Outlaws — все они имеют встроенную поддержку многокадровой генерации. Black Myth: Wukong, Naraka: Bladepoint, Marvel Rivals и Microsoft Flight Simulator 2024 также вскоре получат эту поддержку, а Black State, Doom: The Dark Ages и Dune: Awakening поддержат технологию с момента их выпуска в продажу.

Для игр, в которых используется DLSS предыдущих версий, можно использовать новую DLSS 4 при помощи новой функции подмены — DLSS Override. В приложении настроек нового драйвера доступны параметры переопределения DLSS для каждой поддерживаемой игры. Переопределение DLSS для генерации кадров включает многокадровую генерацию и поддерживается только на GeForce RTX 50, переопределение DLSS для предустановок моделей ИИ включает последнюю модель генерации кадров для GeForce RTX 50 и RTX 40, а модель трансформера для суперразрешения и реконструкции лучей доступна для всех пользователей GeForce RTX. Есть возможность принудительного форсирования работы DLSS в режим DLAA или DLSS Ultra Performance, даже если они отсутствуют в игровых настройках. Поддержка DLSS Override есть для 75 игр и приложений на момент запуска, а новая реконструкция лучей на основе модели трансформера, Super Resolution и DLAA поддерживается в более чем 50 играх и приложениях.
В последней версии драйвера появилась еще одна новая функция — Nvidia Smooth Motion. Это новая модель ИИ в драйвере, которая генерирует дополнительный кадр между двумя отрисованными игрой кадрами. По сути, это возможность форсирования генерации одного промежуточного кадра для игр без поддержки генерации кадров DLSS, чтобы увеличить итоговую частоту кадров, но в более простом варианте. Smooth Motion можно включать в играх, работающих в родном разрешении, а также с технологиями сверхвысокого разрешения или другими методами масштабирования, просто итоговая частота кадров увеличивается. Конечно, работает это не так хорошо, как полноценная генерация кадров DLSS, использующая данные из движка игры для улучшения качества, но в некоторых случаях и такая относительно простая интерполяция смотрится неплохо. Smooth Motion включается для совместимых DirectX 11 и DirectX 12 играх в настройках приложения Nvidia.
Новый тип шейдеров — нейронные шейдеры
Это еще одно нововведение Blackwell, весьма многообещающее и перспективное, но не дающее результата прямо сейчас. Nvidia предлагает новый вид шейдеров для того, чтобы нейросети напрямую участвовали в рендеринге, дополняя работу привычных вычислительных блоков. Компания изменила многое в игровой индустрии в 2018 году с выпуском первых видеокарт серии GeForce RTX, и тогда они получили шквал критики за малый прирост производительности в существующих играх в погоне за «не нужной» (как казалось тогдашним критикам) аппаратной трассировкой, которую тогда использовали буквально в двух-трех играх. Но с тех пор уже несколько сотен игр и приложений используют трассировку лучей и технологии ИИ так или иначе, и они появились уже и в игровых консолях. Трассировка лучей и трассировка пути в реальном времени — это именно то, что приносит играм реалистичное изображение с максимально точной и достоверной имитацией реалистичного освещения, и игр с их поддержкой становится всё больше.
Сегодня уже мало кто критикует трассировку лучей, она доказала свою актуальность и применимость. Но Nvidia не была бы собой, если бы не продолжила предлагать индустрии что-то новое еще и еще. Это нейронный рендеринг RTX Neural Rendering — набор технологий искусственного интеллекта и рендеринга с ускорением рендеринга сложных сцен, а также реалистичной визуализацией различных объектов. Многие архитектурные улучшения в Blackwell были сделаны именно для повышения производительности и эффективности нового типа шейдеров. Чаще всего шейдеры вычисляют уровни освещения и цвета для всех пикселей сцены, эти программы работают на GPU в качестве части графического конвейера. Изначально применялись самые простые программы — конвейер с фиксированными функциями, когда все операции графического конвейера предопределены и частично настраиваемы, но программировать их было нельзя. Тогдашние GPU были заточены для выполнения конкретного предопределенного набора операций, но в GeForce 3 появились зачатки программируемого затенения и вершинные шейдеры. В дальнейшем стали применять язык HLSL для затенения пикселей, в DirectX 10 появились геометрические шейдеры, в DX11 — вычислительные шейдеры, а в DX12 и аппаратная трассировка лучей.
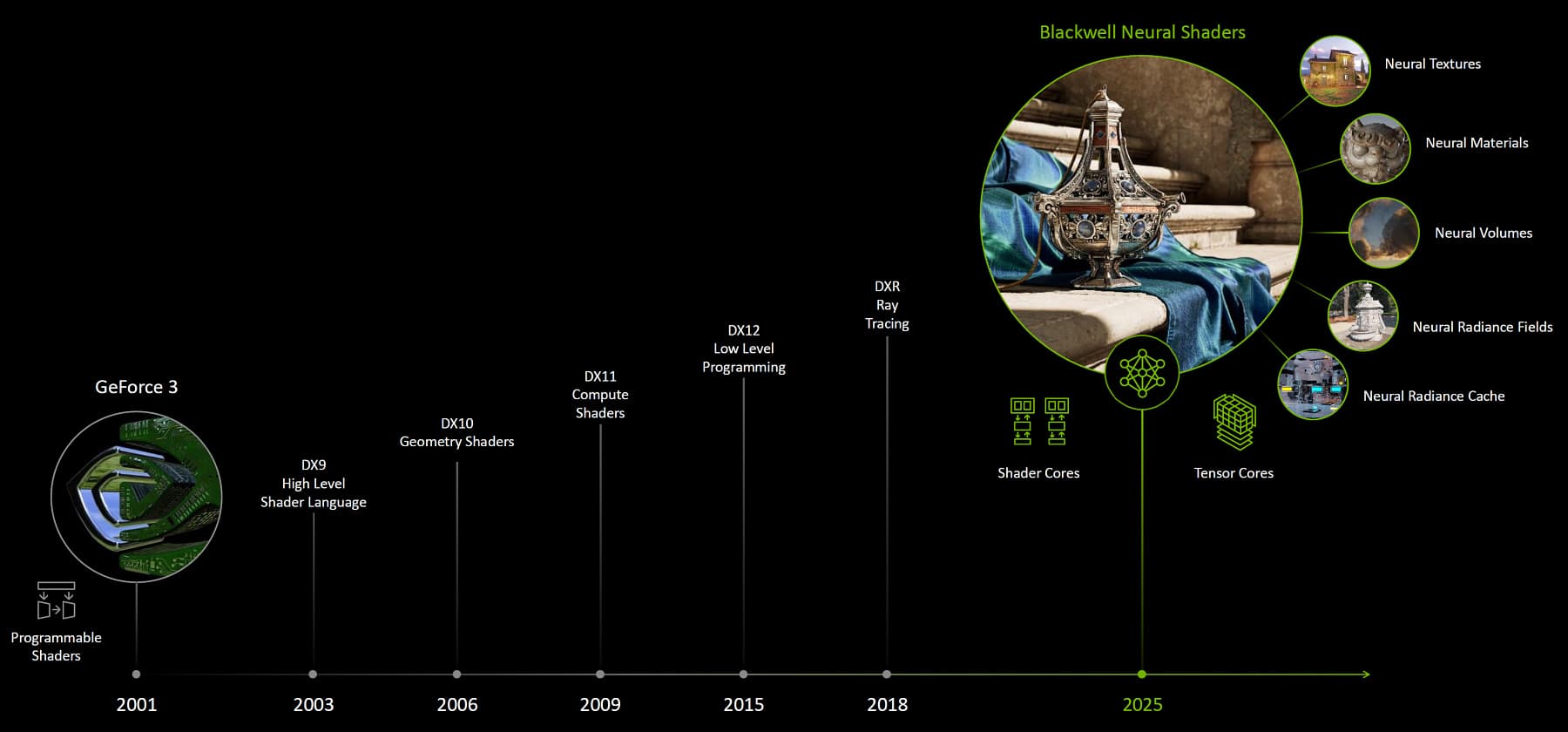
Нейронные шейдеры являются следующим шагом эволюции программируемых шейдеров, и вместо того, чтобы писать сложные шейдеры, можно обучить модели ИИ для выдачи результата без работы привычных шейдеров. Nvidia утверждает, что нейронные шейдеры станут преобладающей формой шейдеров и в будущем все игры будут использовать такие технологии при рендеринге. Решения компании уже используют нейросети в DLSS с помощью тензорных ядер, а с будущими возможностями графических API по доступу к тензорным ядрам, можно будет получить доступ из любого типа шейдера, включая пиксельные шейдеры и трассировку лучей. Это позволит использовать множество технологий, доступных нейросетям, включая нейронное сжатие текстур, а также другие технологии, такие как Neural Materials, Neural Radiance Cache, RTX Skin и RTX Neural Faces. Применения нейрошейдеров обширны, специализированные SDK позволят разработчикам обучать нейросети в шейдерах на GeForce RTX и ускорять их на тензорных ядрах. Вкратце рассмотрим лишь некоторые из открывающихся возможностей.
Компрессия текстур RTX Neural Texture Compression (NTC) использует возможности ИИ при сжатии текстур, их «нейронное» представление занимает в памяти в несколько раз меньше места — по оценкам Nvidia до 7 раз меньше по сравнению с традиционными блочными форматами сжатия при сохранении того же качества. Объем необходимых играм данных постоянно растет, большая часть из них именно текстуры, что повышает требования к объему памяти GPU и влияет на производительность из-за ограничения ее пропускной способности. Нейронное сжатие текстур использует нейросети из нейронных шейдеров для сжатия и распаковки и делает это эффективнее привычных методов. Так, демонстрация Nvidia Neural Materials использует 1110 МБ памяти для стандартных материалов фонаря и ткани, а с нейронными материалами та же картинка получается при использовании лишь 333 МБ — налицо трехкратная экономия при даже более высоком качестве.
Интересна также стохастическая фильтрация текстур — Stochastic Texture Filtering (STF), которая используется для введения элемента случайности в текстурные выборки для снижения визуальных артефактов алиасинга и муара в тех случаях, когда нецелесообразно применять традиционные методы фильтрации — трилинейную или анизотропную при использовании нейронного сжатия текстур, например. Или же можно использовать эту возможность совместно с аппаратной фильтрацией для получения фильтрации более высокого уровня — кубической или гауссовой. Стохастическая фильтрация работает вдвое быстрее на графических процессорах семейства Blackwell из-за увеличения скорости точечных выборок из текстур вдвое, по сравнению с GPU предыдущих поколений.
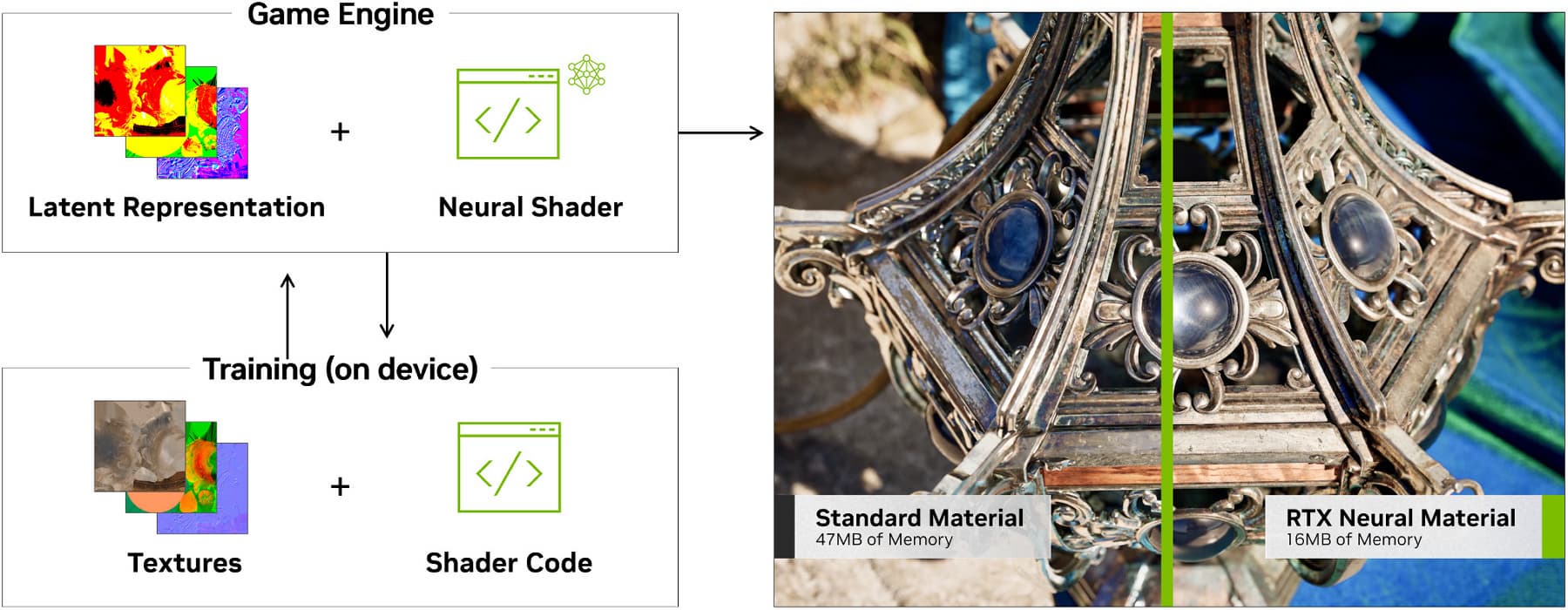
Нейроматериалы Neural Materials используют возможности ИИ для «сжатия» сложного шейдерного кода, применяемого для многослойных материалов, вроде фарфора и шелка — при этом отрисовка этих материалов происходит в несколько раз быстрее, что позволяет снизить ресурсоемкость рендеринга. Некоторые материалы могут состоять из нескольких слоев, и делать полноценную трассировку лучей для этих нескольких слоев — слишком дорогостоящее занятие. Методы искусственного интеллекта могут заменить математическую модель материала его нейронной аппроксимацией, что позволяет достаточно качественно отрисовать материалы и позволит сделать это с высокой частотой кадров.
Neural Radiance Cache (NRC) — нейронный шейдер для кэширования и аппроксимации информации об освещении. Этот шейдер использует нейросети, обученные на игровых данных, для точной отрисовки непрямого освещения в игровой сцене. С его помощью можно сохранять информацию о сложном освещении и использовать ее для создания качественного глобального освещения (GI) при рендеринге реального времени. NRC частично трассирует один-два луча, сохраняет данные в кэше и затем выводит условно бесконечное количество отскоков лучей для реалистичного представления непрямого освещения в игре. Это одновременно улучшает качество непрямого освещения при трассировке пути и повышает производительность, так как в процессе трассируется меньше лучей. NRC уже доступен через RTX Global Illumination SDK и будет применяться в Portal RTX, а затем и в RTX Remix.

Нейронный шейдер NRC принимает в качестве входных данных результат трассировки пути после одного отскока луча, а выводит значения освещения уже для многих отскоков. NRC обучает маленькие нейронные сети на основе игровых данных в реальном времени и имитирует трассировку пути с большим количеством отскоков лучей, помещая эти данные в кэш. Так как нейросеть обучается во время игры, NRC постепенно подстраивается для получения точного профиля глобального освещения для разных игровых сцен.
Корректный рендеринг кожи — одна из известных проблем 3D-графики, и если отрисовывать ее без учета полупрозрачности, как будто она непроницаема для лучей света, как дерево или металл, тогда изображения людей будут казаться пластиковыми. А в реальности лучи света проникают под кожу и рассеивается внутри, излучаясь затем в других фрагментах. Традиционные методы рендеринга недостаточно точно имитируют взаимодействие света с кожей, и для улучшения рендеринга кожи часто используют подповерхностное рассеивание (SubSurface Scattering — SSS), и RTX Skin — один из вариантов применения подповерхностного рассеяния вместе с трассировкой лучей в играх. SSS имитирует проникновение света в полупрозрачные материалы и его рассеивание внутри, в итоге создавая более мягкий и естественный вид кожи (не только человеческой).

Еще большей сложностью при рендеринге реального времени является реалистичная визуализация человеческих лиц. Люди сразу же чувствуют любые недостатки на человеческих лицах, даже самые незаметные, для этого есть даже термин с названием «Зловещая долина» — когда искусственный человек выглядит очень похоже на настоящего, но при этом он не точно как настоящий, и эта небольшая разница вызывает даже несколько большую неприязнь у наблюдателей, чем если бы объект был совсем не похож на человека. При рендеринге в кинофильмах со временем решили проблему, но это обычно требует очень больших вычислительных ресурсов.
RTX Neural Faces предлагает новый подход к улучшению качества рендеринга лиц с использованием генеративного ИИ. В качестве входных данных используется простое растровое изображение лица вместе с данными о его положении в пространстве (поза, поворот и т.д.), и применяется модель генеративного ИИ для отрисовки более естественных лиц. Нейросеть может обучаться на основе тысяч изображений лица под любым углом, при разном освещении, выражении разных эмоций и т.д. Можно использовать реальные фотографии или изображения, сгенерированные с высоким качеством за длительное время. Обученная модель оптимизируется Nvidia TensorRT и используется для отрисовки лиц в реальном времени — это серьезный шаг на пути к переопределению графики при помощи генеративного ИИ в реальном времени.
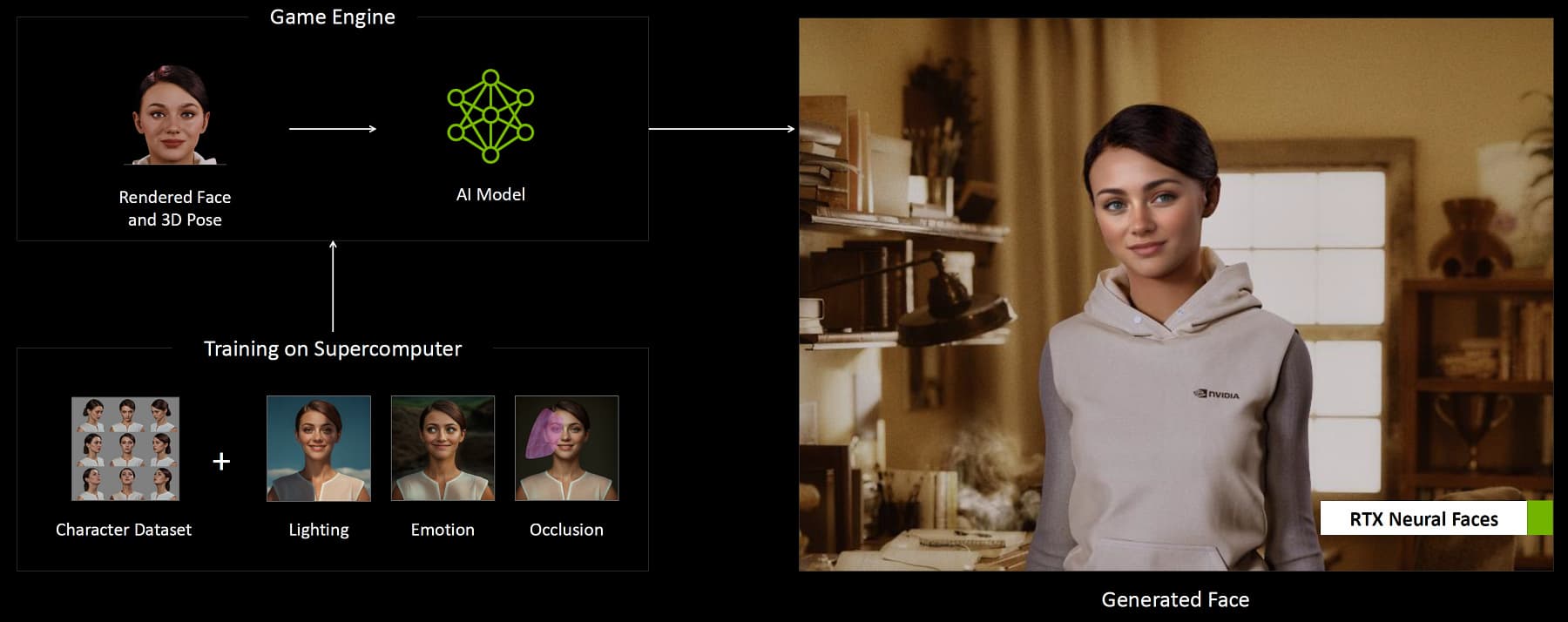
RTX Neural Faces можно дополнить RTX Character Rendering SDK для отрисовки реалистичных волос и кожи, что также является непростой задачей. Реалистичные методы отрисовки волос на основе прядей требуют до 30 треугольников на прядь и под 4 миллиона треугольников для всех волос, что делает ту же трассировку лучей очень сложной. Мы уже писали, что Nvidia предлагает использование нового примитива Linear-Swept Spheres (LSS), который уменьшает объем геометрии, необходимой для рендеринга волос, использует сферы вместо треугольников и позволяет отрисовывать волосы с трассировкой лучей с ускорением на GeForce RTX 50, а значит и лучшей производительностью.
Методик применения нейронных шейдеров очень много, Nvidia приводит пример лишь нескольких из них, над которыми уже плотно поработала. Нейронные шейдеры могут отрисовать при помощи тензорных блоков сложные многослойные материалы или материалы для которых важен расчет подповерхностного рассеивания света — без необходимости точных физических расчетов. Вы спросите, зачем упрощать рендеринг, если мы только что перешли к физически корректной трассировке лучей, а теперь снова ищем какие-то хаки? Всё дело в том, получается ли создать изображение, аналогичное тому, что получается при точном физическом расчете. Если да, то какая пользователю разница, была ли это полноценная трассировка пути или ее имитация при помощи нейросетей? В этом отличие от хаков растеризации, которые чаще всего создают физически неправдоподобное и нереалистичное изображение. Можно делать и полностью корректные расчеты с трассировкой лучей, но это очень сложно вычислительно, а нейронные шейдеры способны в некоторых случаях имитировать аналогичный результат с приемлемой точностью.
Технологии нейронного рендеринга — это прекрасно и перспективно, но увидим ли мы их в играх прямо сегодня? Точно нет, да и завтра очень вряд ли. Они обязательно будут, но на первых порах штучно, скорее всего — чтобы показать возможности технологии. А для широкого распространения нужна поддержка не только разработчиков игр, но и со стороны графических API. Пока что наверняка можно использовать NVAPI и расширения Nvidia для Vulkan, но было бы очень хорошо получить полноценную поддержку со стороны того же DirectX. Радует, что компания Nvidia уже работает совместно с Microsoft для внедрения поддержки функциональности Cooperative Vectors, которая позволит перемножать матрицы с произвольными размерами в шейдерном коде, что и необходимо для работы нейросетей. Это раскроет возможности тензорных ядер GeForce RTX и позволит разработчикам игр ускорить нейронные шейдеры на решениях Nvidia, а затем и на GPU других производителей. Другие производители графических процессоров будут вынуждены сделать поддержку Cooperative Vectors в своих решениях, и в итоге это будет полезно для всей индустрии. Пока же эта возможность является исключительной для решений Nvidia и вряд ли получит очень широкое распространение, хотя перспективы технологии впечатляют.
Другие изменения и улучшения
Еще в графических процессорах Ada Lovelace появилась возможность динамической перегруппировки инструкций — Shader Execution Reordering (SER), служащая для улучшения когерентности доступа к данным при таких задачах, как исполнение пиксельных шейдеров для отраженных лучей. В архитектуре Blackwell эффективность SER увеличилась вдвое, что полезно для лучшей загрузки работой тензорных ядер при исполнении нейронных шейдеров. Новые решения архитектуры Blackwell получили также программируемый планировщик контекста AI Management Processor (AMP), основанный на ядре RISC-V. Предыдущие GPU уже имели подобный планировщик, но AMP более гибко и эффективно распределять время GPU для разных задач.
Shader Execution Reordering (SER) — это технология, позволяющая при трассировке лучей реорганизовать исполняемые на GPU вычислительные потоки для максимального использования аппаратных возможностей. Динамическое переупорядочение работы особенно эффективно в сложных рабочих нагрузках при трассировке лучей, вроде трассировки пути. Потоки, когерентно выполняющие нейронные задачи, могут быть отправлены в тензорные ядра, SER значительно ускоряет и нейронное затенение. SER был улучшен в Blackwell как аппаратно, так и программно. Основная логика переупорядочения SER в Blackwell вдвое эффективнее, что снижает накладные расходы на переупорядочение. SER контролируется приложениями при помощи небольшого API, это позволяет разработчикам применять переупорядочение более точно. Несколько игр с реализацией трассировки пути уже используют SER.
Произошли некоторые изменения и контроллере вывода на дисплеи и медиадвижках GeForce RTX 50. Для вывода изображения графические процессоры Blackwell получили поддержку разъемов DisplayPort 2.1b, обеспечивающих пропускную способность до 80 Гбит/с в режиме передачи UHBR 20, что позволяет использовать дисплеи с высоким разрешением и частотой обновления: 8K при 165 Гц (с DSC) и 4K при 480 Гц (также с DSC). Если говорить о более приземленных вещах, то такая пропускная способность позволяет подключить 8K-дисплей с частотой обновления 60 Гц по одному кабелю.
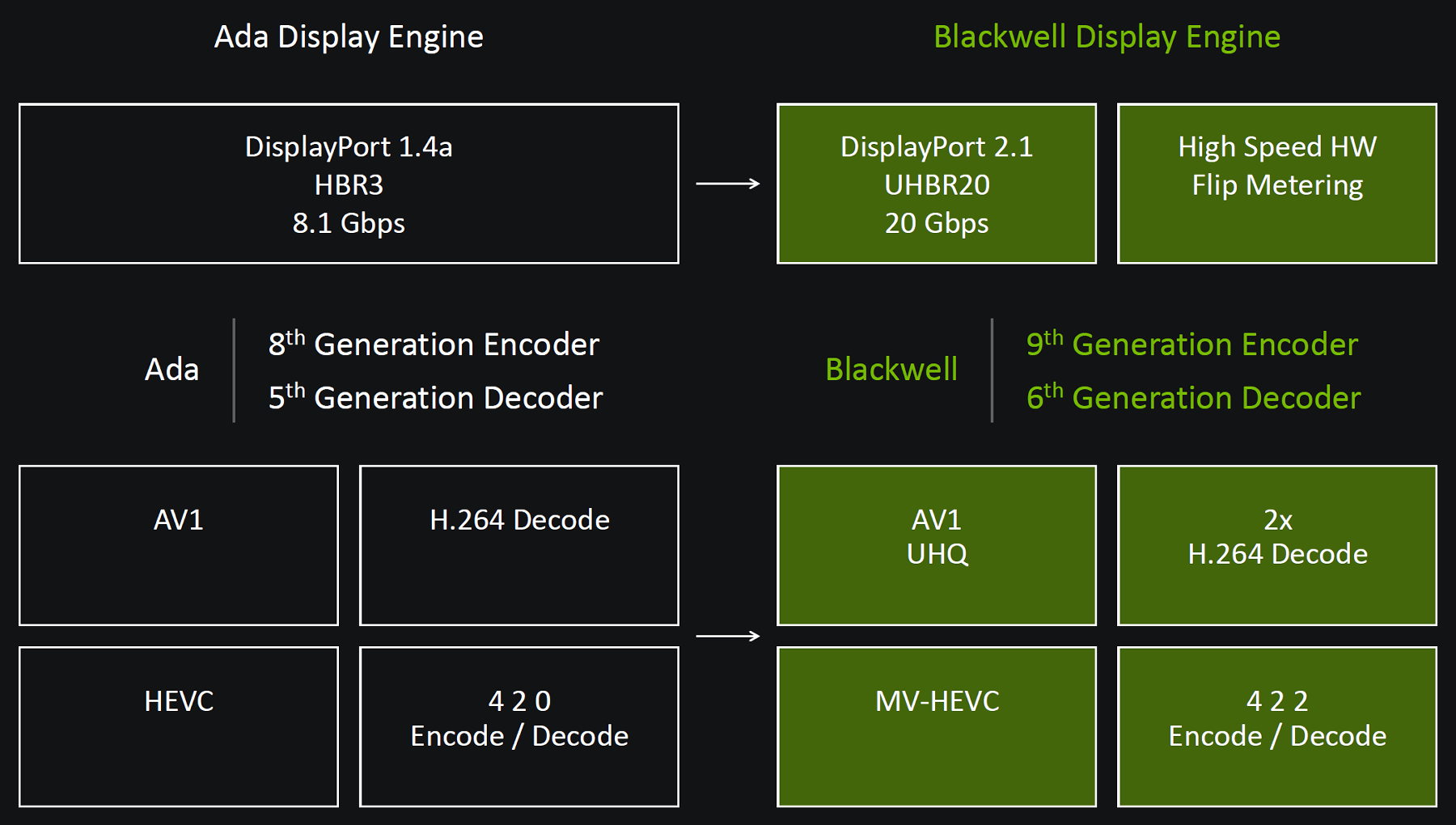
В новых видеокартах семейства GeForce RTX 50 была добавлена поддержка кодирования и декодирования видео с цветовой субдискретизацией 4:2:2 для форматов H.264 и H.265. Ada Lovelace и остальные предыдущие архитектуры GPU предлагали поддержку только 4:2:0 для видеоданных в форматах H.264 и H.265, а новое семейство добавляет возможность кодирования и декодирования с лучшим качеством. В формате 4:4:4 каждый канал сохраняет полное значение, но это приводит к большим размерам файлов и увеличению требуемой пропускной способности при передаче данных. Цветовая субдискретизация снижает эти требования за счет хранения меньшего количества информации о цветности, в видео 4:2:0 полные данные сохраняются только по яркости, а каналы цветности содержат лишь 25% исходной информации о цвете. Формат 4:2:2 предлагает некий баланс между сохранением большего количества цветовой информации и уменьшением размера файла, в нем сохраняется половина исходной цветовой информации.

Этот вариант обеспечивает лучшее качество и популярен в дорогих полупрофессиональных и профессиональных видеокамерах, но программная обработка таких видеоданных затруднена из-за высокой ресурсоемкости. Если говорить более точно, формат 4:2:2 обеспечивает вдвое больший объем информации о цвете при всего лишь на 30% большем размера файла, по сравнению с 4:2:0, а эта дополнительная цветовая информация особенно полезна для HDR-контента и сохранения мелких деталей. На GPU без аппаратной поддержки используется программное декодирование 4:2:2, что создает довольно высокую вычислительную нагрузку, аппаратная же поддержка декодирования 4:2:2 позволяет видеоредакторам с легкостью работать с таким контентом.
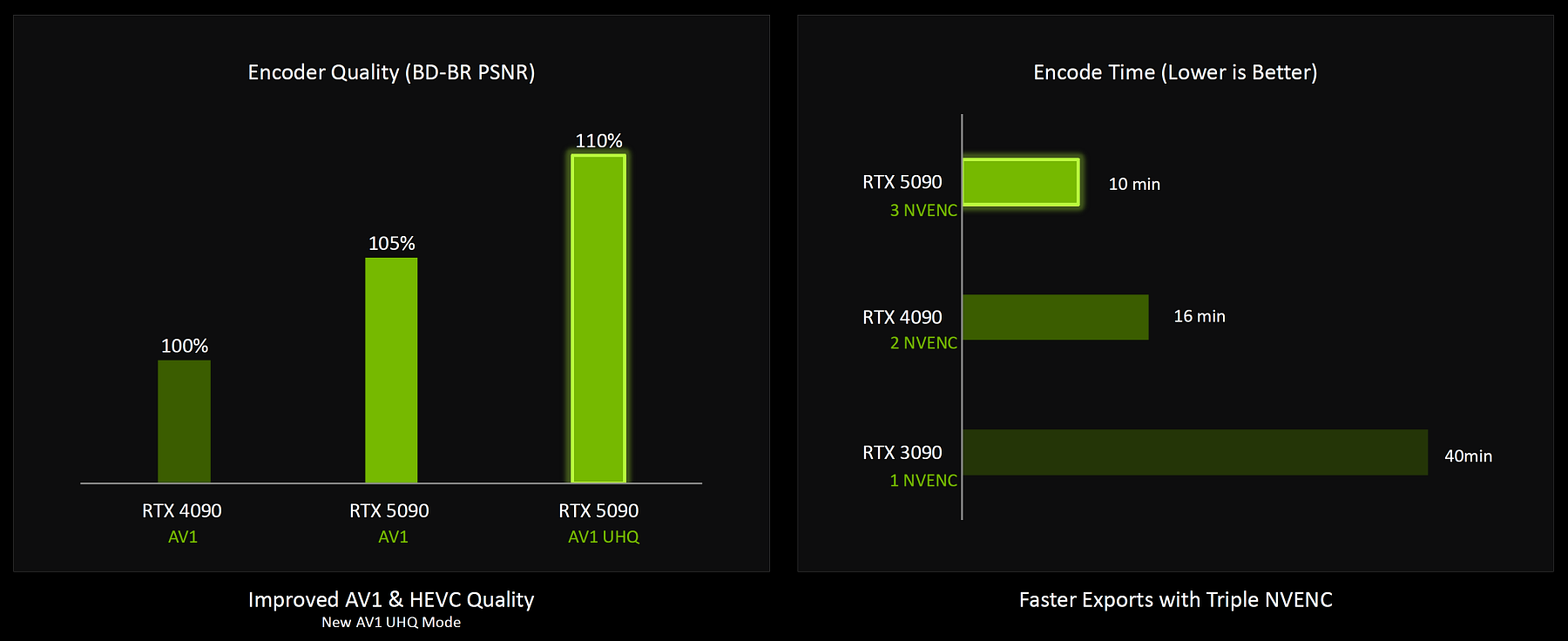
Программные возможности кодирования в несколько раз медленнее, по сравнению с аппаратными кодерами NVEnc 9-го поколения, которые есть в решениях семейства Blackwell. Старшая пара из анонсированных решений семейства Blackwell имеет по два декодера NVDec, как их аналоги в Ada Lovelace, но их производительность при работе с видеоданными в формате H.264 выросла вдвое. Кодировщиков видеоданных в чипах разное количество — в топовом кристалле GB202 их три, а в рассматриваемом GB203 — два блока NVEnc. Также появился новый режим AV1 Ultra High Quality (UHQ), более требовательный, но обеспечивающий небольшое улучшение качества картинки.
Предварительная оценка производительности
Сравним теоретические показатели анонсированных видеокарт серии GeForce RTX 50, основанных на трех анонсированных чипах линейки GB20x — это позволит наглядно оценить разницу между ними.
| RTX 5090 | RTX 5080 | RTX 5070 Ti | RTX 5070 | |
|---|---|---|---|---|
| Графический процессор | GB202 | GB203 | GB203 | GB205 |
| Транзисторов, млрд. | 92,2 | 45,6 | 45,6 | 31,1 |
| Площадь чипа, мм² | 750 | 378 | 378 | 263 |
| Количество ядер CUDA | 21760 | 10752 | 8960 | 6144 |
| Количество блоков TMU | 680 | 336 | 280 | 192 |
| Количество блоков ROP | 176 | 112 | 96 | 80 |
| Количество RT-ядер | 170 | 84 | 70 | 48 |
| Тензорные ядра | 680 | 336 | 280 | 192 |
| Турбо-частота, ГГц | 2,41 | 2,62 | 2,45 | 2,51 |
| Объем памяти, ГБ | 32 | 16 | 16 | 12 |
| Шина памяти, бит | 512 | 256 | 256 | 192 |
| Пропускная способность, ГБ/с | 1792 | 960 | 896 | 672 |
| Энергопотребление, Вт | 575 | 360 | 300 | 250 |
| Цена, $ | 1999 | 999 | 749 | 549 |
Топовый чип GB202, на котором основана видеокарта RTX 5090, поставил рекорд по сложности в игровых GPU — 92,2 млрд, что уже близко к GB100 — специализированному вычислительному чипу той же архитектуры Blackwell, который состоит из 104 млрд. транзисторов. А по площади кристалла GB202 в 750 мм² он совсем немного уступил 754 мм² чипа TU102 архитектуры Turing. Флагманское решение включает 192 потоковых мультипроцессора SM, что дает в целом 24576 CUDA-ядер, да и остальные характеристики этого GPU весьма впечатляют. Он также имеет 512-битный интерфейс памяти, что в сочетании с GDDR7-памятью дает очень высокую пропускную способность в 1792 ГБ/с! В остальном топовый GPU явно ограничен возможностями техпроцесса, если Ada Lovelace с большим шагом по микроэлектронному производству позволил повысить вычислительную мощность более чем на 70%, то GB202 превосходит своего предшественника уже лишь на треть. У инженеров Nvidia получилось разместить на той же площади больше ALU и других блоков, но не увеличить плотность по количеству транзисторов на площадь кристалла.
А вот остальные игровые чипы семейства Blackwell получили совсем не столь впечатляющие характеристики на фоне быстрейшего GPU. Второй по счету GB203 сразу вдвое меньше флагмана — и по площади и по сложности, да и по количеству вычислительных блоков не слишком впечатлил на фоне чипа AD103 предыдущего поколения примерно того же позиционирования. К тому же, шина памяти у GB203 сразу вдвое уже — лишь 256-бит. Хотя с GDDR7-памятью это не является узким местом для решения такого уровня. Если сравнивать новинку с GeForce RTX 4080 и RTX 4080 Super, то ее тактовая частота лишь чуть выше, а рост пиковой производительности не превышает 10%-15%. То есть, в играх без использования новых технологий, RTX 5080 вряд ли сильно превзойдет графические процессоры предыдущего поколения того же уровня.
Но GeForce RTX 5080 имеет 16 ГБ GDDR7-памяти с эффективной частотой 30 ГГц, которая подключена по 256-битной шине. Это обеспечивает приличную пропускную способность в 960 ГБ/с, что на треть выше по сравнению с модификациями RTX 4080. И в некоторых случаях прирост ПСП может дать и соответствующий рост частоты кадров, но вряд ли он будет выше 25%-30% в любом случае. И только в самых тяжелых играх с трассировкой лучей приросты будут больше 15%-20%. Также возможны улучшения в играх с расчетом глобального освещения с большим количеством просчитываемых отражений лучей — в том числе потому, что эти алгоритмы часто упираются в пропускную способность памяти.
И при показателе энергопотребления в 360 Вт, превышающем 320 Вт у предшественников, совсем неудивительно, что для многих читателей новая модель выглядит скорее как GeForce RTX 4080 Ti, чем как RTX 5080. Тем более что Nvidia оставила рекомендованную цену в $999, так что на некую улучшенную RTX 4080 Ti она вполне похожа. Но всё же аппаратные улучшения в графической архитектуре есть, и немалые, поэтому это скорее именно RTX 5080, но... лишь с косметическими аппаратными изменениями, скажем так. К сожалению, в этом поколении очень сильно вырос разрыв между RTX 5080 и RTX 5090 — у флагмана все характеристики вдвое или почти вдвое лучше, и объем памяти с ПСП в том числе. Правда, и цена отличается ровно вдвое.
Технический прогресс несколько замедлился по объективным причинам, и рост чистой производительности GPU уже не может происходить прежними темпами, которые мы видели в предыдущих поколениях. Специалистам Nvidia пришлось выжимать максимум из имеющегося техпроцесса 5 нм при помощи новой функциональности, и Blackwell отличается новыми возможностями технологии DLSS и внедрением нейронных шейдеров и других предлагаемых функций не просто так. Это продолжение движения в сторону того, чтобы рендеринг производился не только грубой силой традиционных исполнительных блоков и с порой даже излишне сложной работой над изображением, но и дорисовыванием пикселей при помощи масштабирования и генерации дополнительных кадров при помощи технологии DLSS 4 уже сейчас, а в будущем — с широким использованием нейронных шейдеров.

Nvidia привычно указывает преимущество новинки над RTX 4080 до двух и даже больше раз, но этот прирост производительности не совсем честный. Он почти всегда учитывает многокадровую генерацию, а порой ведь и качество масштабирования может хромать, хотя в DLSS 4 серьезно улучшили его, устранив многие артефакты предыдущих версий. А иногда, даже при высокой частоте кадров из-за работы MFG, большие задержки ввода всё равно не позволят комфортно поиграть, так как реальная родная частота кадров будет ниже уровня минимального комфорта.
Так что пока что и так называемая чистая производительность для графических процессоров всё же очень важна, а GeForce RTX 5080 по ней не сильно отличается от RTX 4080, к сожалению. Если в предыдущих поколениях увеличенной мощи RTX 4080 хватало для того, чтобы догнать предыдущего флагмана, то в этот раз RTX 4090 совершенно точно остался впереди по скорости. Но ведь эта топовая модель из прошлого до сих пор стоит очень дорого, а RTX 5080 по рекомендованной цене не отличается от предшествующих моделей этого же уровня. Правда, пока что непонятно, по каким ценам реально будет купить решения новой линейки, ведь пока что они в большом дефиците.
Особенности карты Palit GeForce RTX 5080 GameRock (16 ГБ)
Сведения о производителе: Компания Palit Microsystems (торговая марка Palit) основана в 1988 году в Китайской Республике (Тайвань). Штаб-квартира — в Тайбэе/Тайвань, крупный центр по логистике — в Гонконге, второй офис (по продажам в Европе) — в Германии. Фабрики — в Китае. На рынке в России — с 1995 года (начинались продажи как безымянных продуктов, так называемых Noname, а под маркой Palit продукты начали идти только после 2000 года). В 2005 году компания приобрела торговую марку и ряд активов Gainward (после, по сути, банкротства одноименной компании), после чего был образован холдинг Palit Group. Был открыт еще один офис в Шеньжене, направленный на продажи в Китае. На сегодня внутри Palit Group сосредоточено еще несколько торговых марок и брендов.
Объект исследования: серийно выпускаемый ускоритель трехмерной графики (видеокарта) Palit GeForce RTX 5080 GameRock 16 ГБ 256-битной GDDR7





| Palit GeForce RTX 5080 GameRock 16 ГБ 256-битной GDDR7 | ||
|---|---|---|
| Параметр | Значение | Номинальное значение (референс) |
| GPU | GeForce RTX 5080 (GB203) | |
| Интерфейс | PCI Express x16 5.0 | |
| Частота работы GPU (ROPs), МГц | BIOS P: 2617(Boost)—2842(Max) BIOS S: 2617(Boost)—2842(Max) | 2617(Boost)—2850(Max) |
| Частота работы памяти (физическая, МГц (эффективная, Гбит/с)) | 2500 (30) | 2500 (30) |
| Ширина шины обмена с памятью, бит | 256 | |
| Число вычислительных блоков в GPU | 84 | |
| Число операций (ALU/CUDA) в блоке | 128 | |
| Суммарное количество блоков ALU/CUDA | 10752 | |
| Число блоков текстурирования (BLF/TLF/ANIS) | 336 | |
| Число блоков растеризации (ROP) | 112 | |
| Число блоков Ray Tracing | 84 | |
| Число тензорных блоков | 336 | |
| Размеры, мм | 330×150×71 | 310×120×40 |
| Количество слотов в системном блоке, занимаемые видеокартой | 4 | 2 |
| Цвет текстолита | черный | черный |
| Энергопотребление пиковое в 3D, Вт (BIOS P/BIOS S) | 346/347 | 360 |
| Энергопотребление в режиме 2D, Вт | 37 | 37 |
| Энергопотребление в режиме «сна», Вт | 10 | 10 |
| Уровень шума в 3D (максимальная нагрузка), дБА (BIOS P/BIOS S) | 31,9/28,7 | 39,0 |
| Уровень шума в 2D (просмотр видео), дБА | 18,0 | 18,0 |
| Уровень шума в 2D (в простое), дБА | 18,0 | 18,0 |
| Видеовыходы | 1×HDMI 2.1b, 3×DisplayPort 2.1b | 1×HDMI 2.1b, 3×DisplayPort 2.1b |
| Поддержка многопроцессорной работы | нет | |
| Максимальное количество приемников/мониторов для одновременного вывода изображения | 4 | 4 |
| Питание: 8-контактные разъемы | 0 | 0 |
| Питание: 6-контактные разъемы | 0 | 0 |
| Питание: 16-контактные разъемы | 1 | 1 |
| Вес карты с комплектом поставки (брутто), кг | 3,22 | 2,9 |
| Вес карты чистый (нетто), кг | 2,2 | 2,0 |
| Максимальное разрешение/частота, DisplayPort | 3840×2160@240 Гц, 7680×4320@120 Гц | |
| Максимальное разрешение/частота, HDMI | 3840×2160@144 Гц, 7680×4320@120 Гц | |
| Ориентировочная стоимость карт на базе GeForce RTX 5080 | 180 000 рублей | |
Память

Карта имеет 16 ГБ памяти GDDR7 SDRAM, размещенной в 8 микросхемах по 16 Гбит на лицевой стороне PCB. Микросхемы памяти Samsung (K4VAF325ZC-SC32) рассчитаны на номинальную частоту работы в 2666 МГц (эффективная ПСП 32 МТ/с).
Особенности карты и сравнение с Palit GeForce RTX 4080 Super GamingPro (16 ГБ)
| Palit GeForce RTX 5080 GameRock (16 ГБ) | Palit GeForce RTX 4080 Super GamingPro (16 ГБ) |
|---|---|
| вид спереди | |
 |  |
| вид сзади | |
 |  |
Мы логично сравниваем новинку с продуктом предыдущего поколения номинально того же уровня (GeForce RTX 4080 Super). Прекрасно видно, что, несмотря на одинаковые шины обмена с памятью, карты отличаются кардинально. Во-первых, сами графические ядра сильно различаются по размерам, во-вторых, система питания также претерпела изменения, в-третьих, печатная плата стала короче, но при этом выше (благо система охлаждения весьма высокая).
Ядро произведено на 51-й неделе 2024 года (кристалл выполнен по техпроцессу TSMC 4N — по разным оценкам это 5 нм). Маркировка — GB203-400, а -400 обычно означает полнофункциональный чип (все блоки активны). То есть если в будущем будет вариант GeForce RTX 5080 Super/Ti на GB203, то поднимать производительность можно будет только путем увеличения частот работы.

Суммарное количество фаз питания у карты Palit GeForce RTX 5080 GameRock — 19 (16+3).

Зеленым цветом отмечена схема питания ядра, красным — памяти.
16 фазами питания ядра управляет ШИМ-контроллер MP29816 (Monolithic Power Systems). Он рассчитан максимум на 16 фаз и расположен на тыльной стороне платы.

В преобразователе питания ядра и микросхем памяти используются транзисторные сборки DrMOS — MP87993 той же компании MPS, рассчитанные на 90 А.

Питанием микросхем памяти тоже управляет ШИМ-контроллер MPS — MP2988 (с OEM-маркировкой). Он рассчитан максимум на 3 фазы и расположен на лицевой стороне платы.

На оборотной стороны PCB имеется контроллер для мониторинга (отслеживания напряжений и температур) On Semi.

Управление подсветкой у видеокарт Palit традиционно возложено на контроллер Holtek.

Карта имеет два режима работы, они заложены в двух вариантах BIOS, которые переключаются с помощью переключателя на переднем торце карты: P (performance / производительный, он же 1) и S (silent / тихий, он же 2). Разница между режимами заключается, по сути, только в оборотах вентиляторов, предел энергопотребления в обоих случаях составляет 360 Вт.

Штатные частоты памяти, а также Boost-значение частоты работы ядра в обоих режимах BIOS 1(P)/BIOS 2(S) равны референсным значениям. При этом максимальная частота GPU у карты Palit чуть-чуть ниже референсной (на 8 МГц, так что это никак не влияет на производительность). Исследования показали, что карта Palit продемонстрировала идентичную с референс-картой производительность в играх.
Энергопотребление карты Palit в тестах доходило до 346 Вт (в режиме BIOS P) и до 347 Вт (BIOS S). Правда, в игре Cyberpunk 2077 при некоторых установках графики потребление может доходить и до 363 Вт.
Я попробовал ручной разгон и получил максимальные частоты 2955/31538 МГц, что обеспечило прирост в играх в разрешении 4К в среднем… всего 2,5% относительно референсных значений. Лимит потребления поднять невозможно, поэтому реальный прирост скорости оказался крайне мал, да и энергопотребление карты почти не выросло: 349 Вт.
Питание на карту Palit подается через 16-контактный разъем питания стандарта PCIe 5.0.

В комплекте поставки карты имеется переходник на такой разъем с трех обычных 8-контактных (хорошо всем знакомых).


Отметим приличные габариты данной карты, особенно по толщине: более 7 см. В результате видеокарта занимает 4 слота в системном блоке.


GeForce RTX 5080 не обладает поддержкой мультиграфической конфигурации, то есть технологии SLI, и у карты нет специального разъема на верхнем торце.
Карта имеет стандартный набор видеовыходов: три DP 2.1b и один HDMI 2.1b.
Управление работой карты обеспечивается с помощью фирменной утилиты ThunderMaster, мы о ней уже много раз писали: программа предоставляет управление вентиляторами (три вентилятора объединены в 2 блока: центральный и боковые), частотами работы карты и напряжением ядра и слежение за состоянием карты (мониторинг).


Нагрев и охлаждение
Мы видим кулер со сквозным продувом хвостовой части радиатора. Основой СО является огромный многосекционный пластинчатый никелированный радиатор с тепловыми трубками, распределяющими тепло по ребрам радиатора.

8 трубок припаяны к большой медной испарительной камере, которая охлаждает как ядро, так и микросхемы памяти (через термопрокладки). В качестве термоинтерфейса для охлаждения ядра используется термопаста (не жидкий металл!).

Для охлаждения преобразователей питания VRM имеются свои подошвы на радиаторе. Задняя пластина служит элементом защиты PCB.

Поверх радиатора установлен кожух с тремя вентиляторами ∅92 мм, имеющими по 9 лопастей и работающими на единой частоте вращения (по умолчанию, но через программу ThunderMaster можно настроить работу отдельно центрального и двух крайних). Кожух изготовлен из литого алюминия и представляет собой очень массивную раму, делающую всю конструкцию очень жесткой.

Пластины радиатора выполнены c наклоном в 30 градусов. Эта технология помогает снизить шум при повышении эффективности охлаждения.
Остановка вентиляторов при малой нагрузке на видеокарту происходит, если температура GPU опускается ниже 50 градусов, а нагрев микросхем памяти ниже 80 градусов. При запуске ПК вентиляторы работают, однако после загрузки видеодрайвера идет опрос рабочей температуры, и они выключаются. Ниже есть видеоролик на эту тему.
Мониторинг температурного режима:
Обратим внимание на то, что последняя на момент написания материала версия 8.20 утилиты HWInfo не еще не поддерживала GeForce RTX 50, поэтому часть показаний с ее датчиком была не совсем корректной. Мы использовали утилиту MSI Afterburner 4.6.6.beta5 для демонстрации температурных показателей, а также максимального энергопотребления.
Также стоит обратить внимание на то, что инженеры Nvidia убрали из данных мониторинга показатели самой горячей точки ядра (hot spot), так что HWInfo выдает тут некорректные значения, на которые не стоит обращать внимание.
Режим BIOS 1(P):

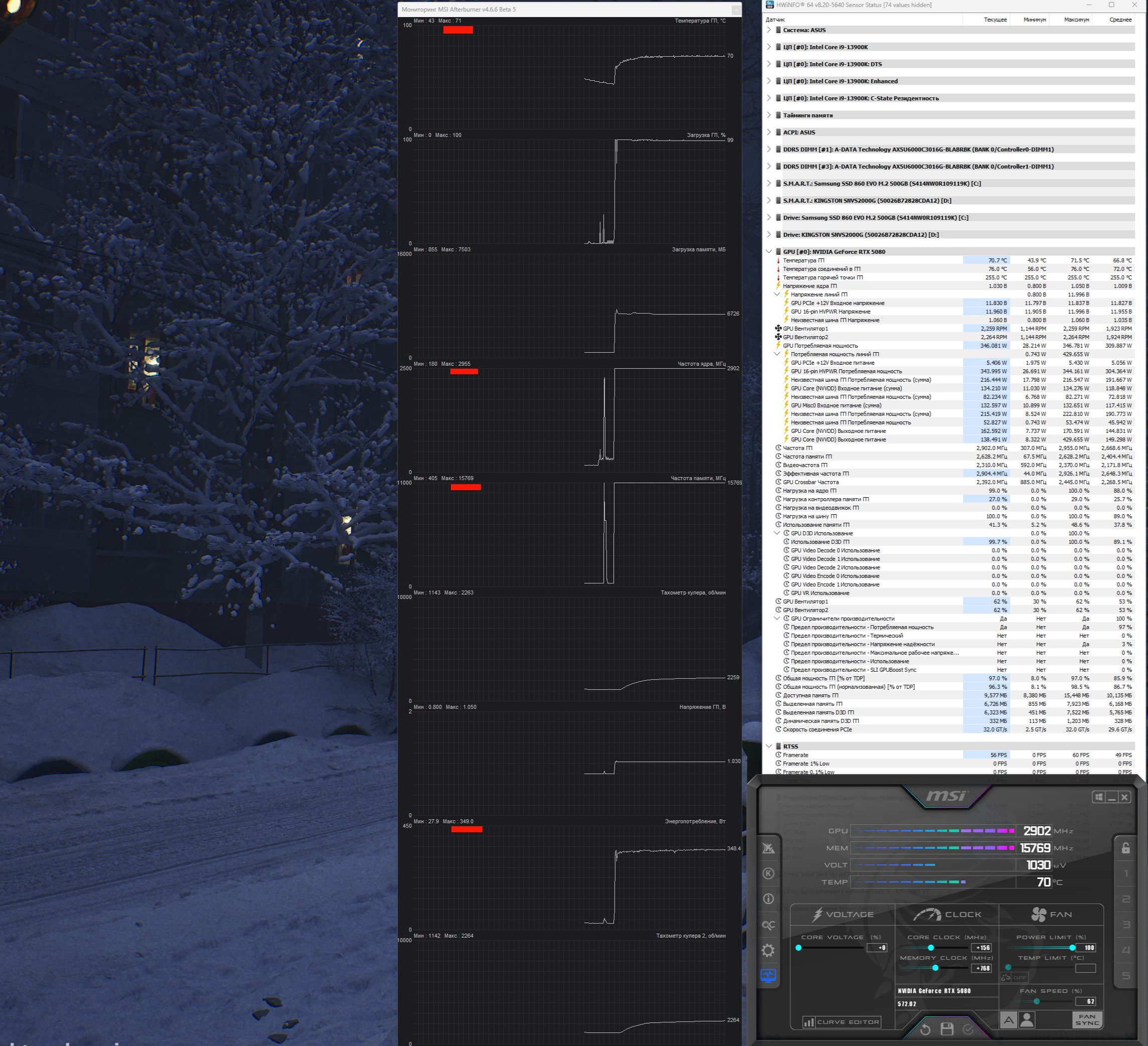
После прогона под нагрузкой максимальная температура ядра не превысила 71 градус, а микросхем памяти — 76 градусов, что является хорошим результатом. Энергопотребление карты доходило до 346 Вт.
Мы засняли и ускорили в 50 раз 8-минутный прогрев
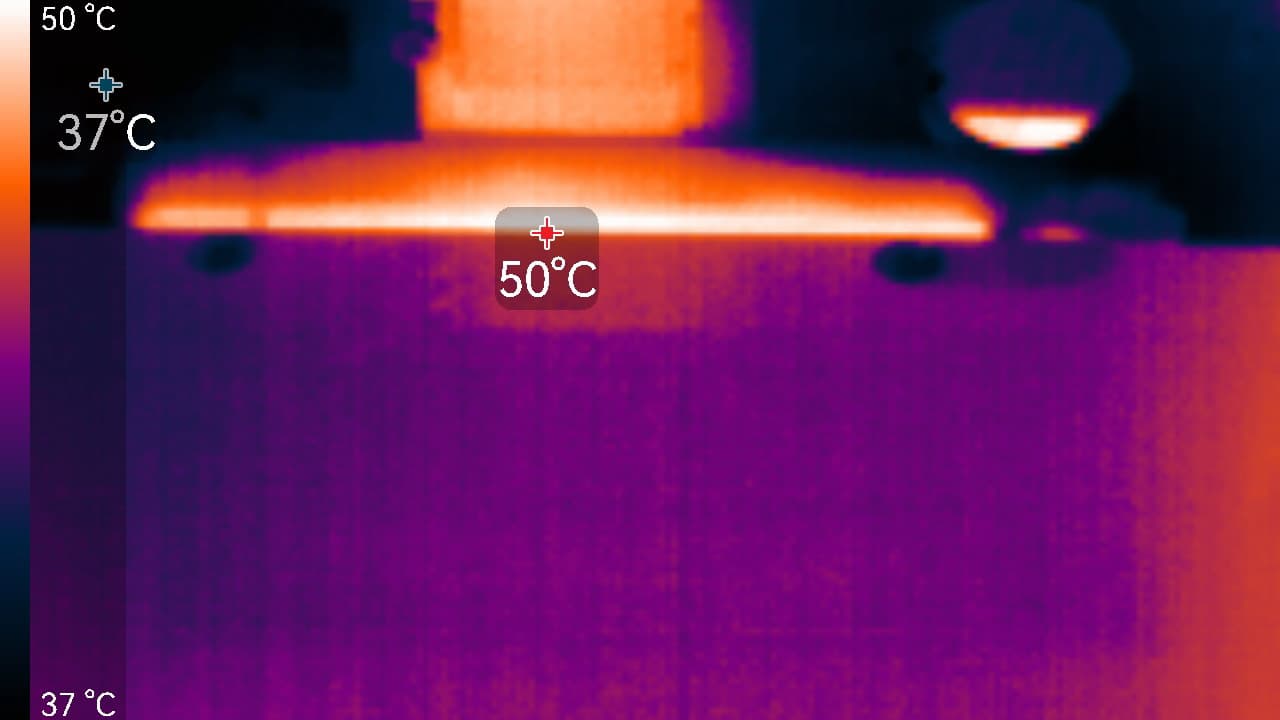
Максимальный нагрев наблюдался в нижней части PCB около разъема PCIe, а также около разъема питания карты.

При ручном разгоне температурные параметры работы карты почти не менялись (чуть вырастали обороты вентиляторов), а потребление карты поднималось до 349 Вт.
Режим BIOS 2(S):
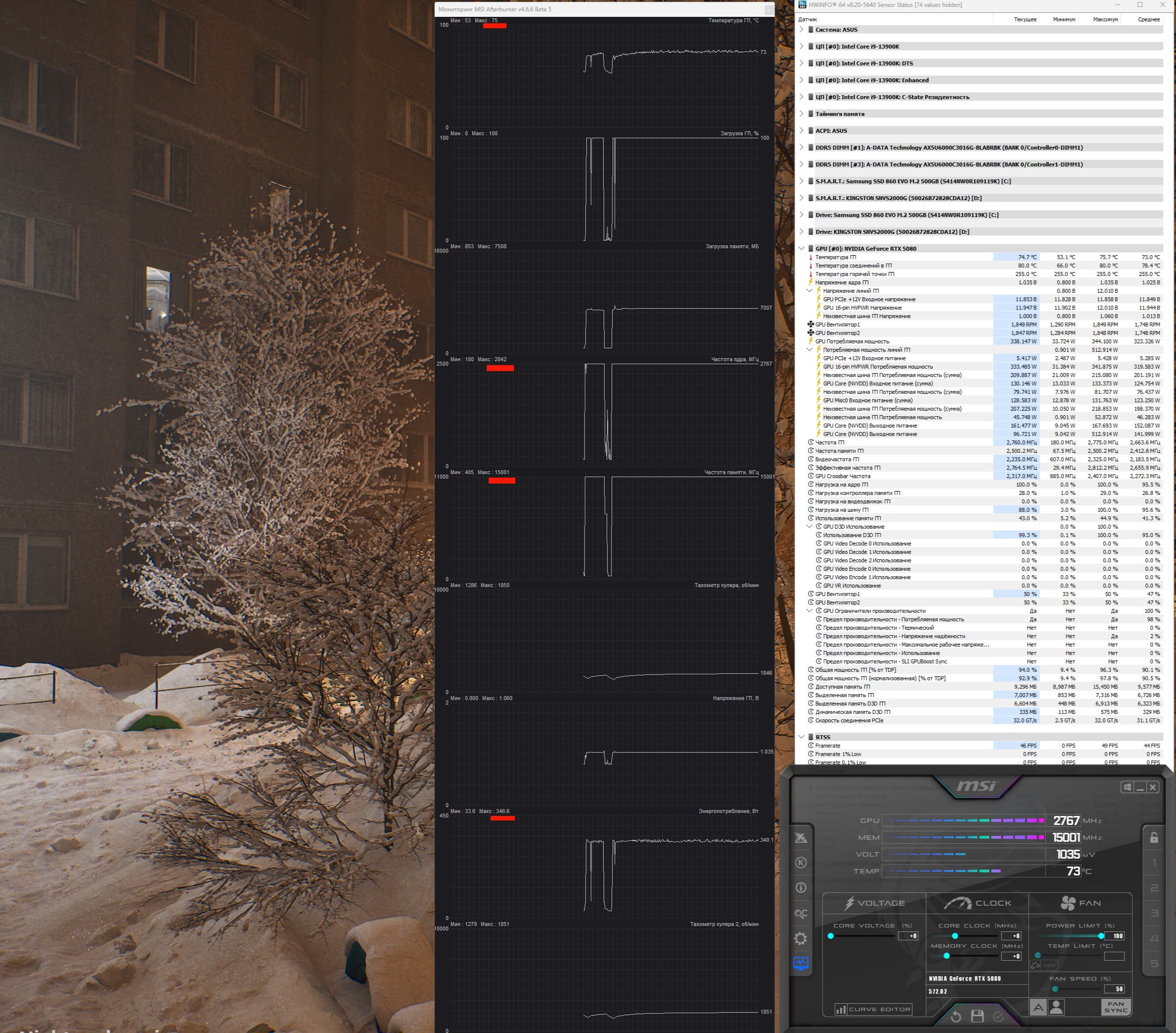
После прогона под нагрузкой максимальная температура ядра не превысила 75 градусов, микросхем памяти — 80 градусов, что также является приемлемым результатом. Энергопотребление карты доходило до 347 Вт.
Шум
Методика измерения шума подразумевает, что помещение шумоизолировано и заглушено, снижены реверберации. Системный блок, в котором исследуется шум видеокарт, не имеет вентиляторов, не является источником механического шума. Фоновый уровень 18 дБА — это уровень шума в комнате и уровень шумов собственно шумомера. Измерения проводятся с расстояния 50 см от видеокарты на уровне системы охлаждения.
Режимы измерения:
- Режим простоя в 2D: загружен интернет-браузер с сайтом iXBT.com, окно Microsoft Word, ряд интернет-коммуникаторов
- Режим 2D с просмотром фильмов: используется SmoothVideo Project (SVP) — аппаратное декодирование со вставкой промежуточных кадров
- Режим 3D с максимальной нагрузкой на ускоритель: используется тест FurMark
Оценка градаций уровня шума следующая:
- менее 20 дБА: условно бесшумно
- от 20 до 25 дБА: очень тихо
- от 25 до 30 дБА: тихо
- от 30 до 35 дБА: отчетливо слышно
- от 35 до 40 дБА: громко, но терпимо
- выше 40 дБА: очень громко
В режиме простоя в 2D температура была не выше 34 °C, вентиляторы не работали, уровень шума был равен фоновому — 18 дБА.
При просмотре фильма с аппаратным декодированием ничего не менялось.
Режим BIOS 1(P):
В режиме максимальной нагрузки в 3D температура достигала 71/76 °C (ядро/память). Вентиляторы при этом раскручивались до 2290 оборотов в минуту, шум вырастал до 31,9 дБА: это отчетливо слышно.
Аудиозапись шума — здесь. Спектрограмма шума проблем не выявила:
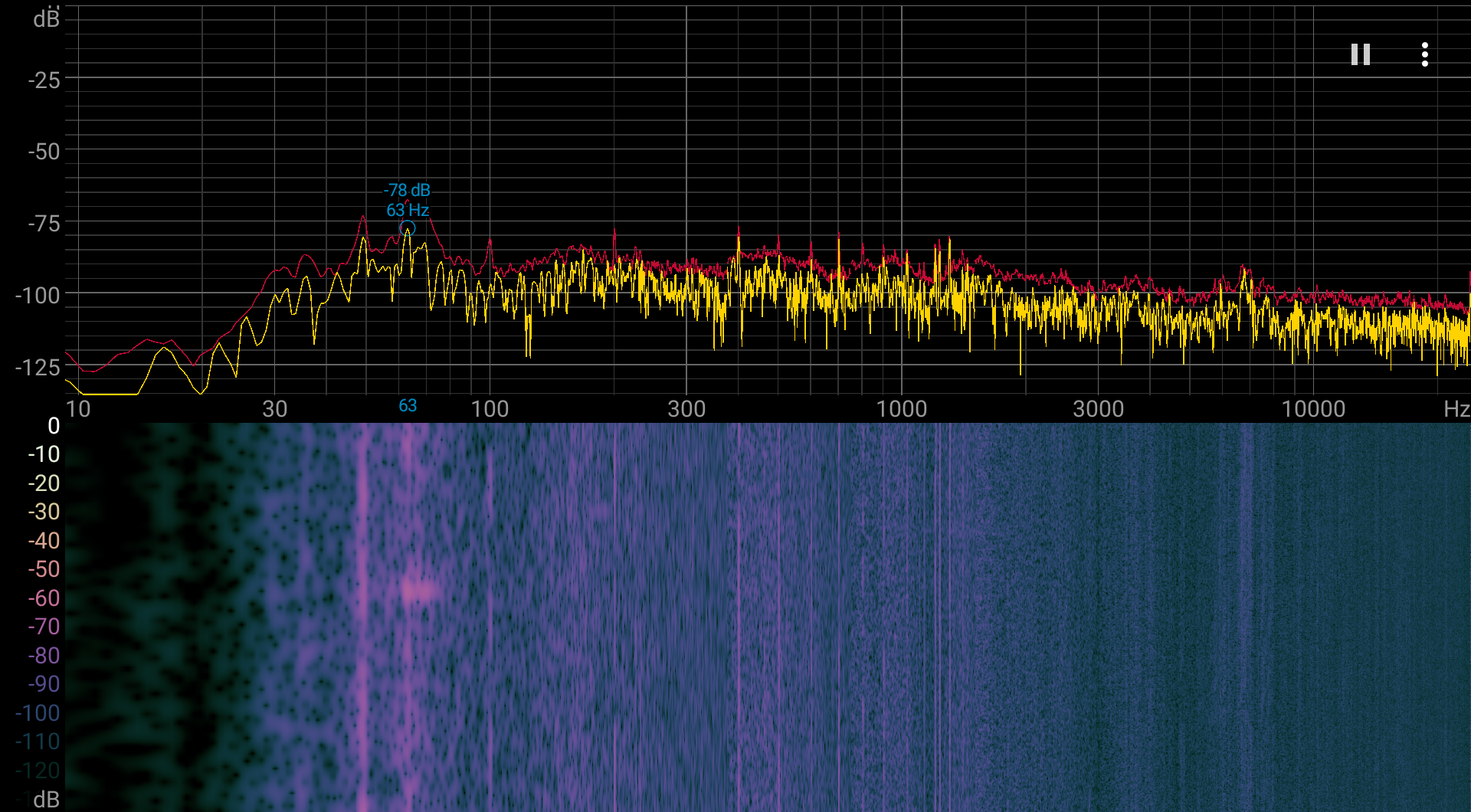
Режим BIOS 2(S):
В режиме максимальной нагрузки в 3D температура достигала 75/80 °C (ядро/память). Вентиляторы при этом раскручивались до 1850 оборотов в минуту, шум вырастал до 28,7 дБА: это тихо.
Подсветка
Карта имеет шикарную подсветку «хамелеон» по всей лицевой поверхности кожуха СО. Более того, «хамелеон» отлично смотрится и без подсветки, переливаясь разной гаммой цветов в зависимости от внешнего освещения.
Также на верхнем торце карты подсвечен логотип серии.
Управление режимами подсветки, в том числе и ее отключением, осуществляется той же утилитой ThunderMaster.
Имеется возможность сохранения выбранного режима в самой карте, то есть при желании можно настроить подсветку один раз и больше не запускать программу.
Отметим, что в комплект поставки карт серии GameRock входит кабель для подключения к разъему ARGB (5 В) на материнской плате, чтобы синхронизировать работу подсветки с платой. В этом случае запускать утилиту ThunderMaster вообще не требуется: карта самостоятельно определит подключение, и подсветка будет синхронизирована по умолчанию.
Комплект поставки и упаковка
В комплекте поставки кроме карты и адаптера питания имеется еще разборная подставка под видеокарту с регулируемым по высоте упором, а также бонусные наклейки и коврик для мыши.





Тестирование: синтетические тесты
Мы провели тестирование новой видеокарты Nvidia на стандартных частотах в нашем наборе синтетических тестов. Он продолжает меняться, иногда добавляются новые тесты, а устаревшие постепенно убираются. Мы бы хотели добавить еще больше примеров с вычислениями, но с этим есть определенные сложности. Мы постоянно стараемся расширять и улучшать набор синтетических тестов, и если у вас есть четкие и обоснованные предложения — напишите их в комментариях к статье или отправьте авторам.
Из более-менее новых бенчмарков мы начали использовать несколько дополнительных тестов для измерения производительности трассировки лучей и, а также технологий масштабирования разрешения и увеличения производительности: DLSS, FSR и XeSS. В качестве полусинтетических тестов у нас также используется набор подтестов из довольно популярного пакета 3DMark: Time Spy, Port Royal, DX Raytracing, Speed Way и др. А вот примеры приложений DirectX 11 и 12, входящие в различные SDK, пришлось уже полностью убрать — в последнее время они всё чаще давали некорректные результаты, делающие анализ бессмысленным.
Синтетические тесты проводились на следующих видеокартах:
- GeForce RTX 5080 со стандартными параметрами на шине PCIe 5.0 (RTX 5080 PCIe 5)
- GeForce RTX 5080 со стандартными параметрами на шине PCIe 4.0 (RTX 5080 PCIe 4)
- GeForce RTX 4090 со стандартными параметрами (RTX 4090)
- GeForce RTX 4080 Super со стандартными параметрами (RTX 4080 Super)
- Radeon RX 7900 XTX со стандартными параметрами (RX 7900 XTX)
Для анализа производительности новой видеокарты GeForce RTX 5080 мы использовали две видеокарты Nvidia предыдущего поколения. Во-первых, это флагманская RTX 4090 — самая мощная модель на основе предыдущей архитектуры, и мы посмотрим, насколько смогла новинка приблизиться к ней. Во-вторых, это RTX 4080 Super того же ценового уровня, которую и заменяет новинка семейства Blackwell. По их сравнительным результатам станет понятно, смогла ли новая архитектура ускорить решение этого уровня и насколько сильно на производительности сказывается пропускная способность памяти, так как по количеству исполнительных блоков они довольно близки.
В качестве прямого соперника для новинки мы взяли единственную подходящую для этой роли модель Radeon из нынешнего поколения — Radeon RX 7900 XTX, так как она является топовой видеокартой компании AMD и близка к новинке по рыночному позиционированию в теории. Все остальные видеокарты Radeon не годятся для сравнения с RTX 5080 по причине заметно меньшей мощности и цены, а новое поколение GPU хоть и было объявлено, но еще не выпущено на рынок. Сравнение с таким соперником даст нам понимание того, насколько новинка хороша против единственной условно конкурирующей модели.
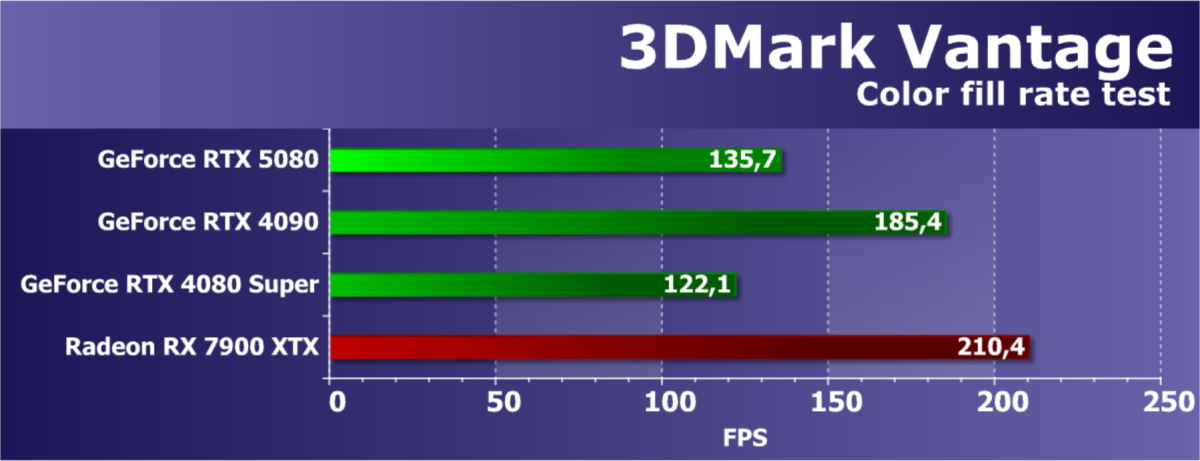
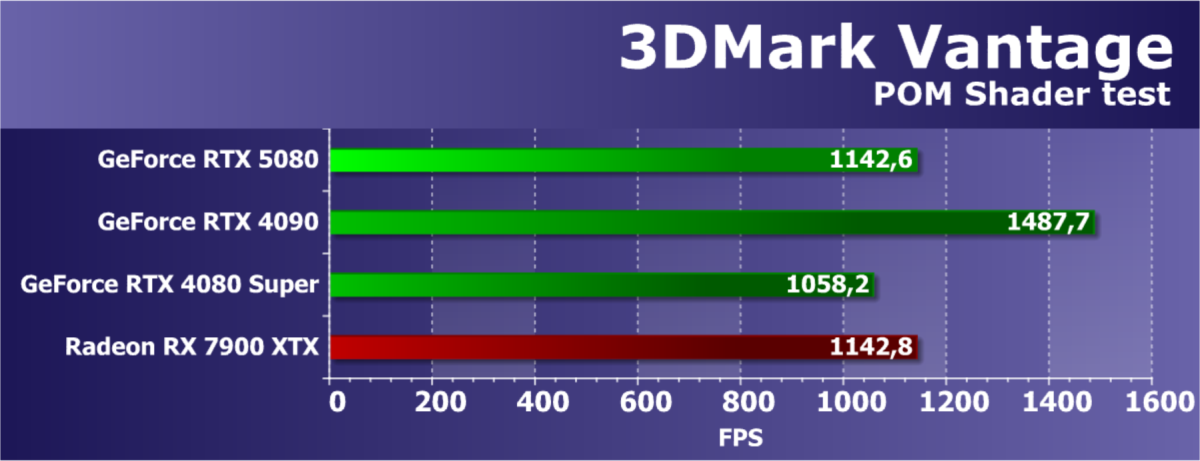
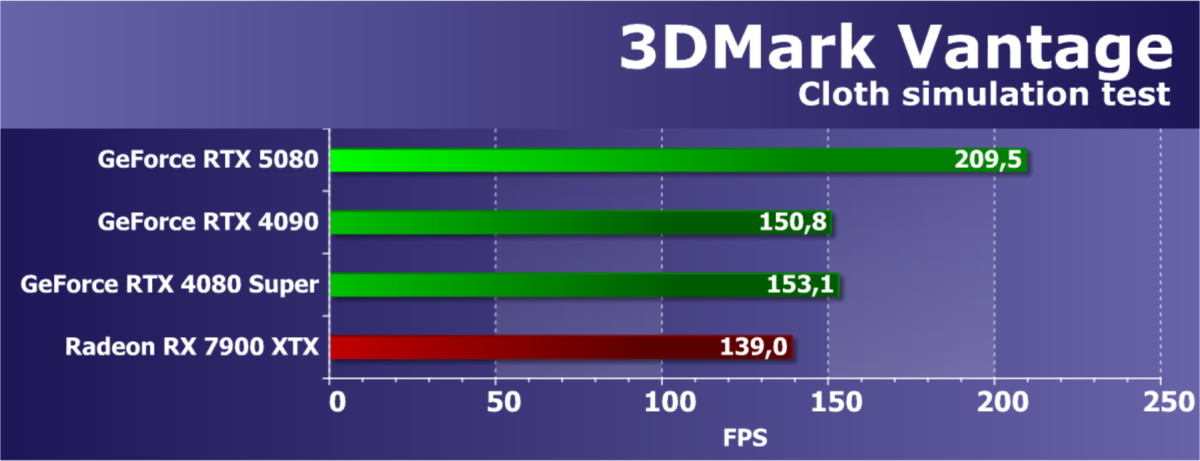
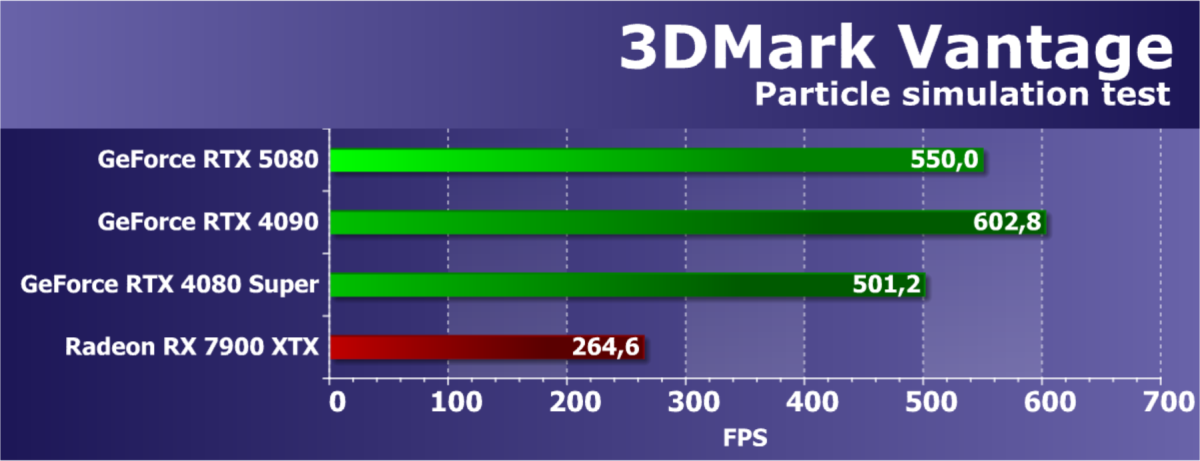


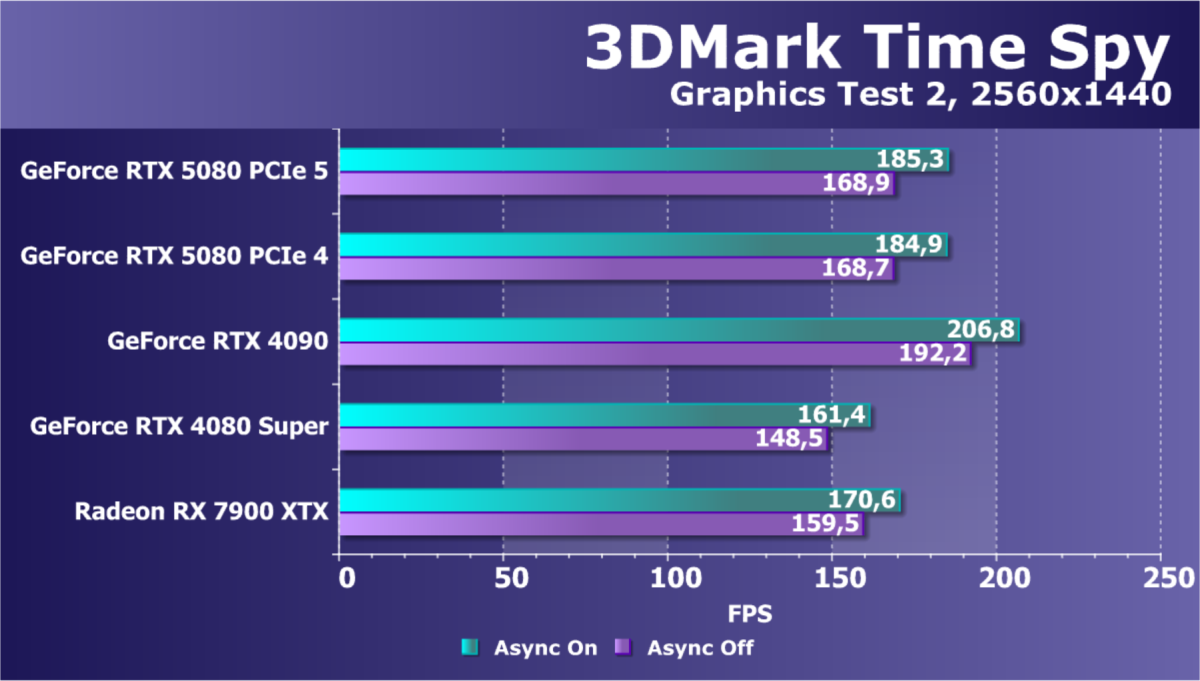
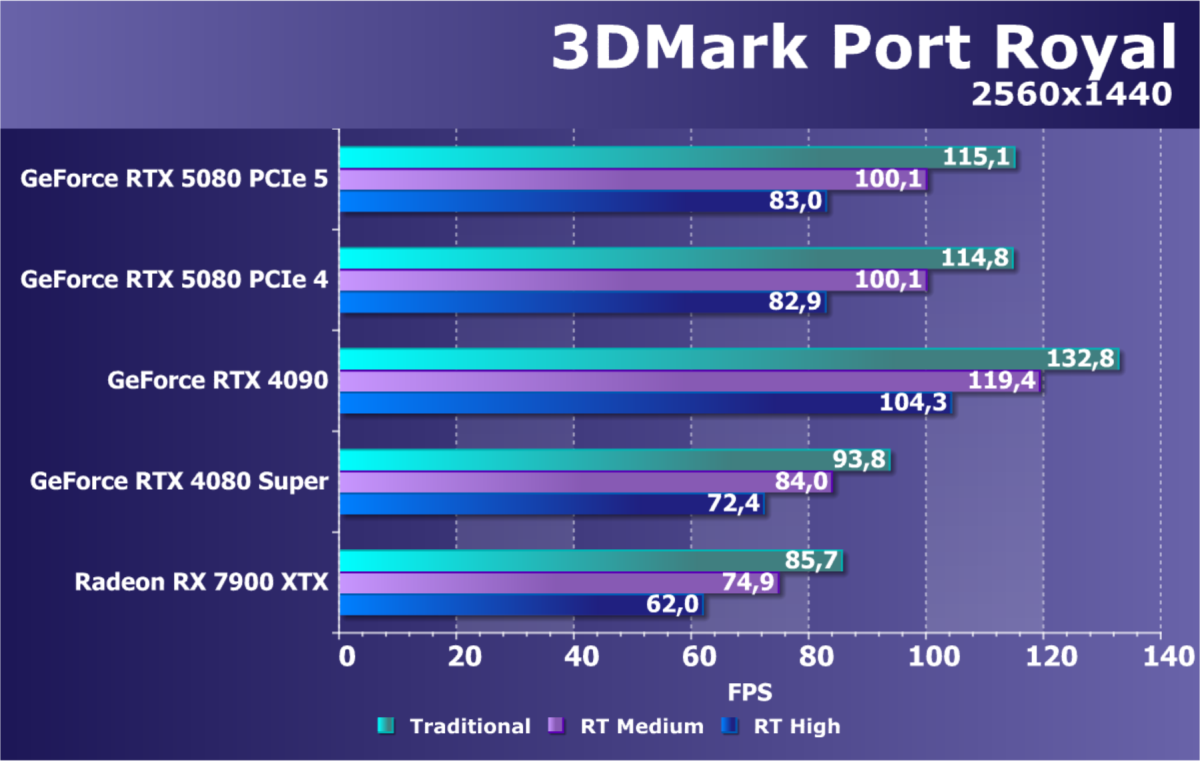
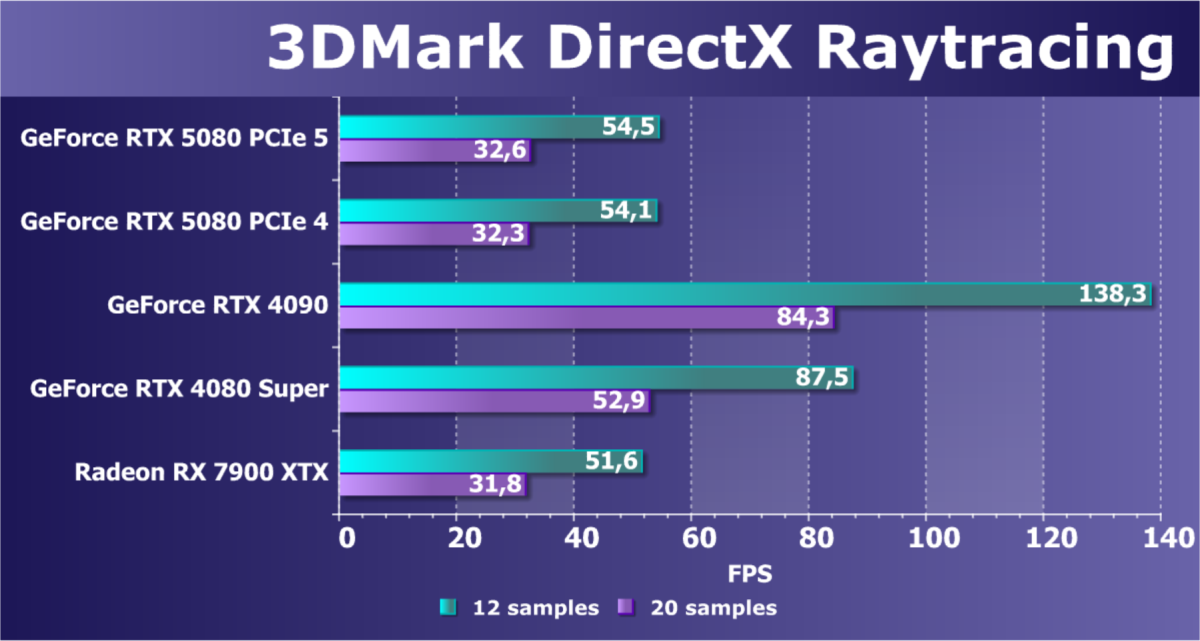
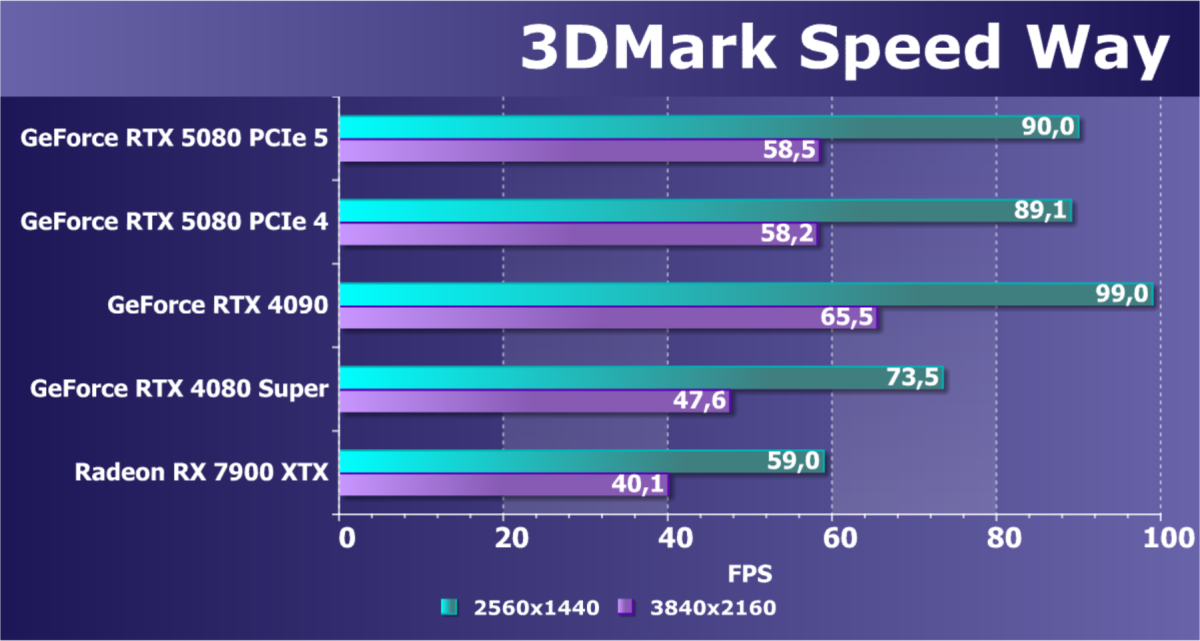
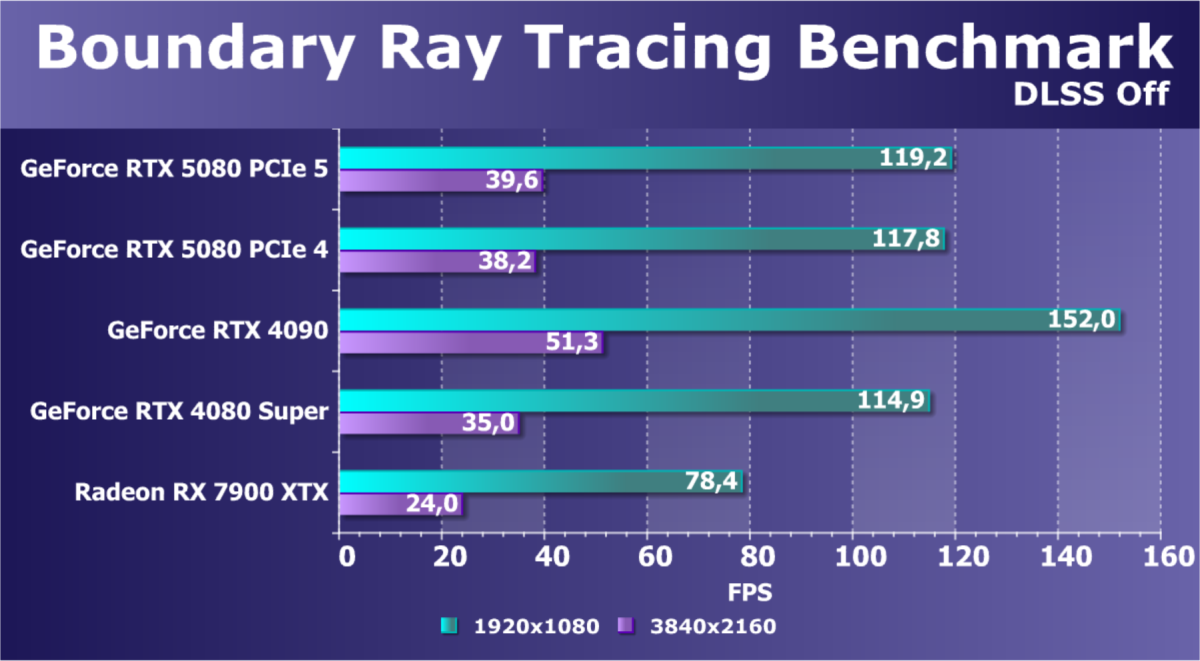
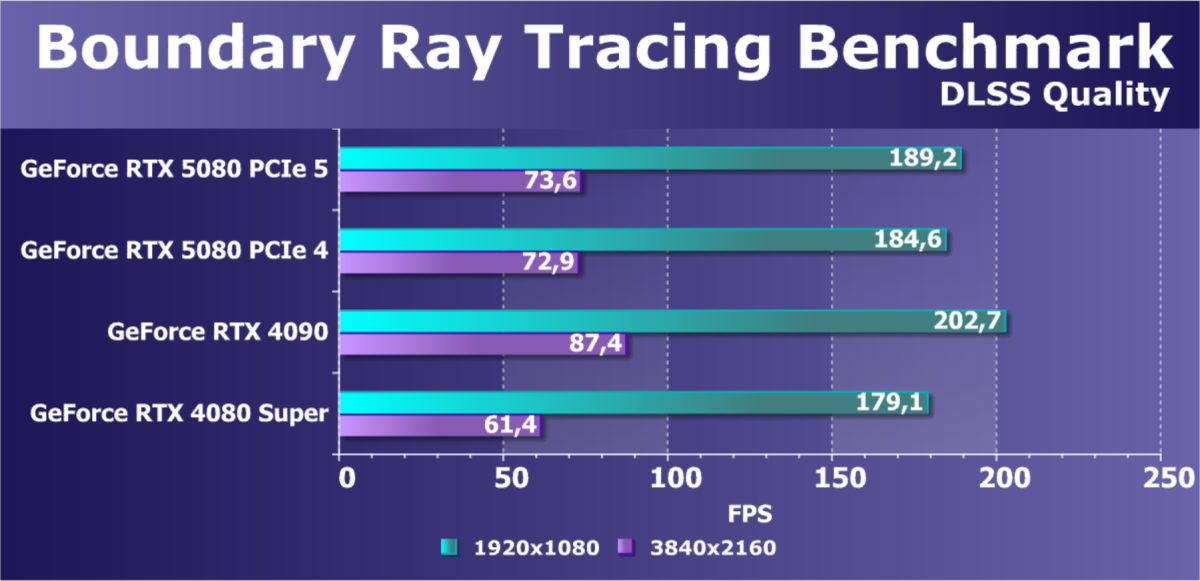
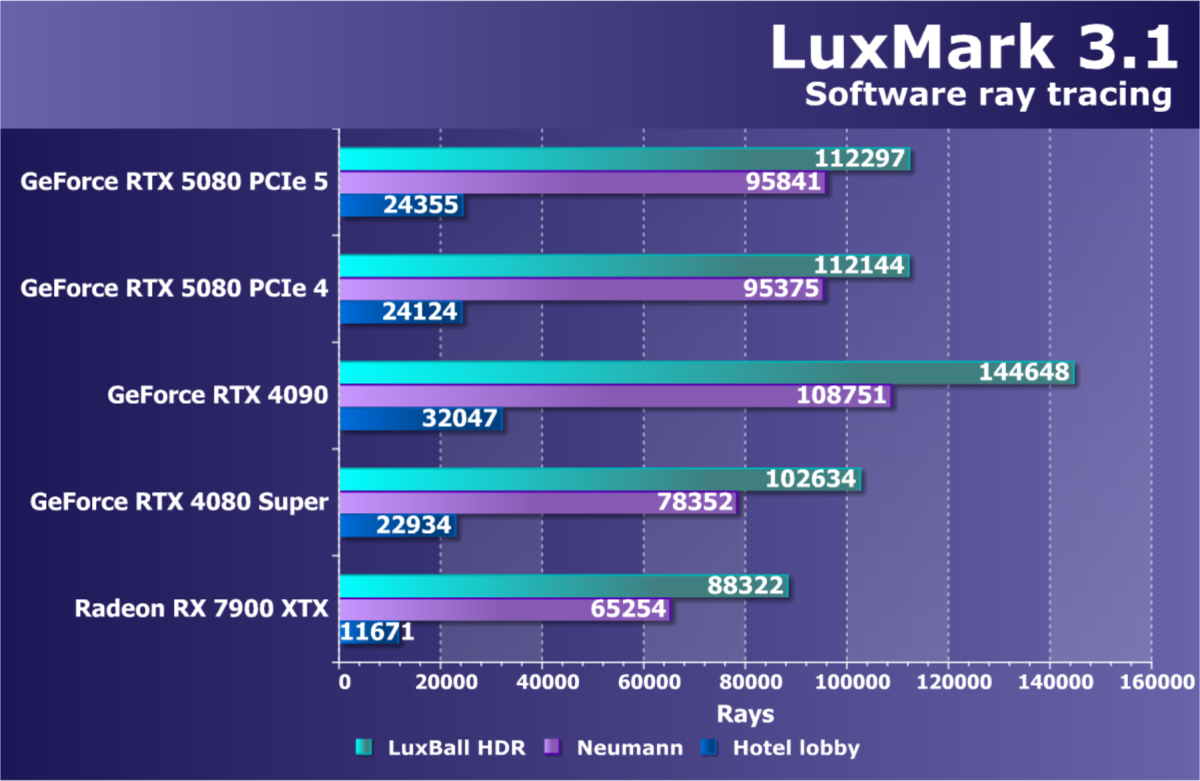
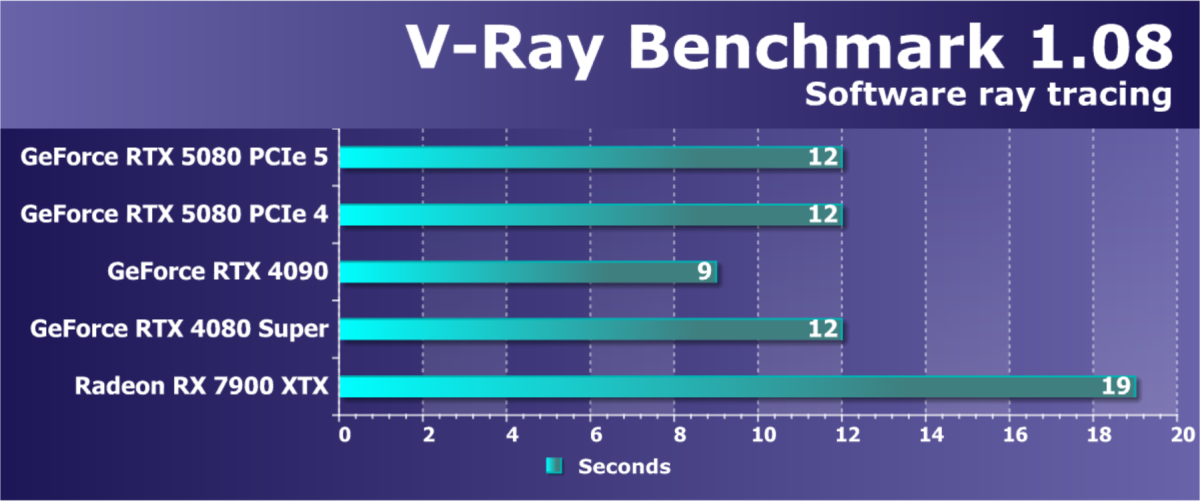
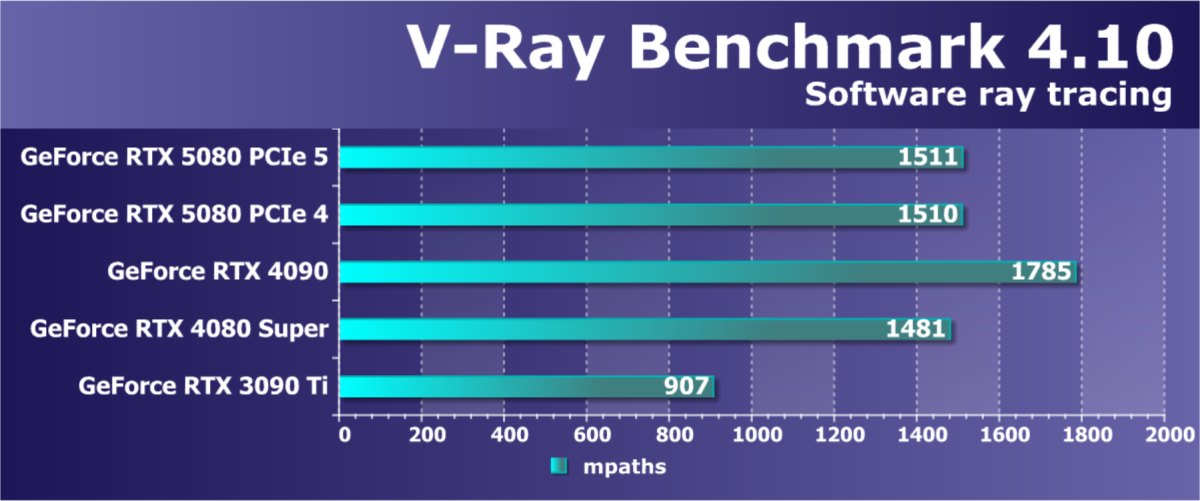
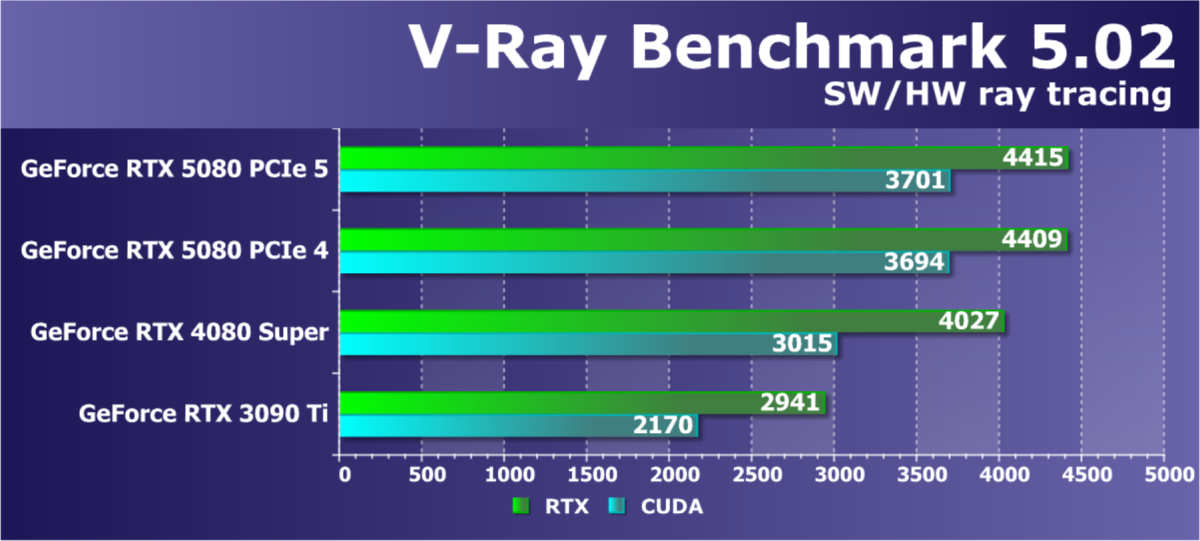
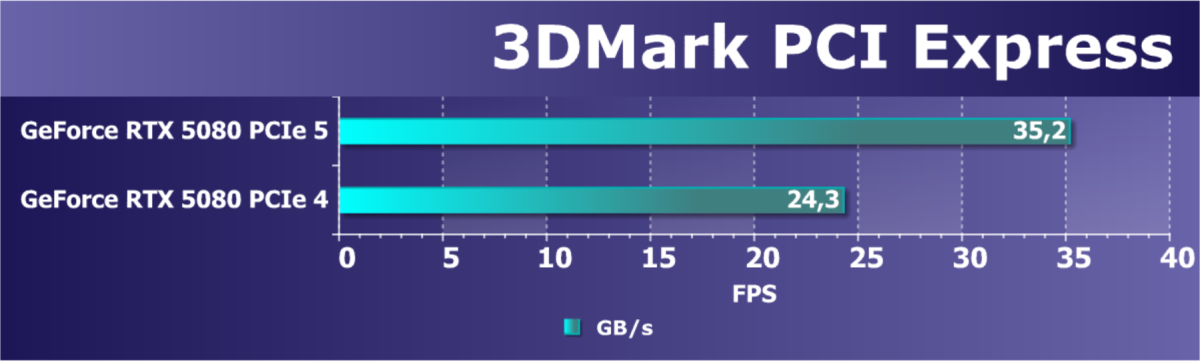
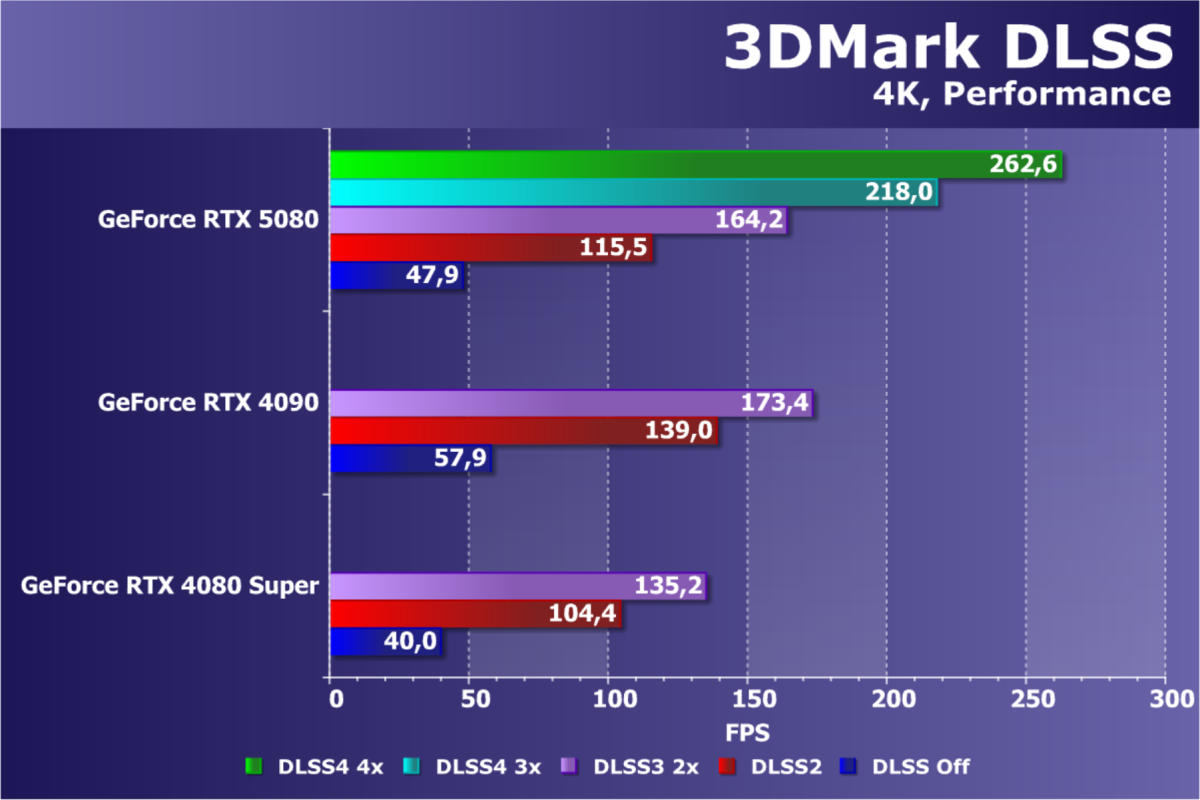
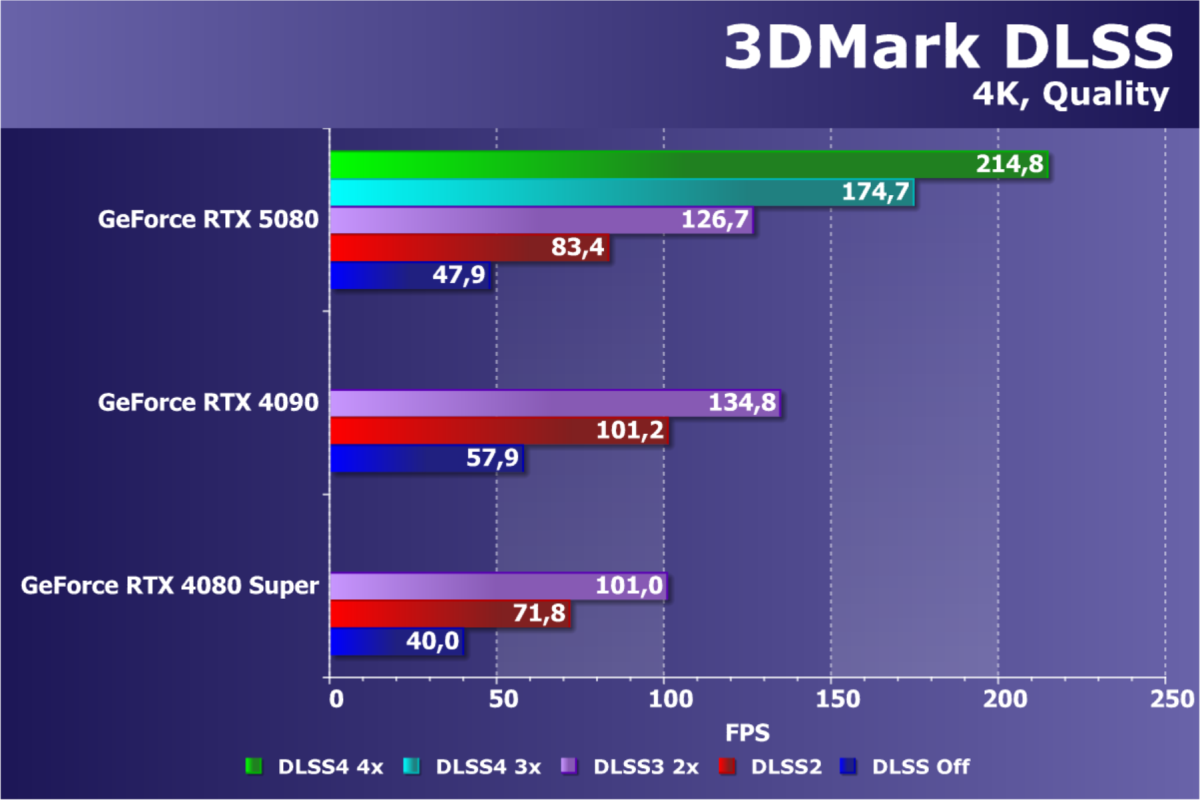
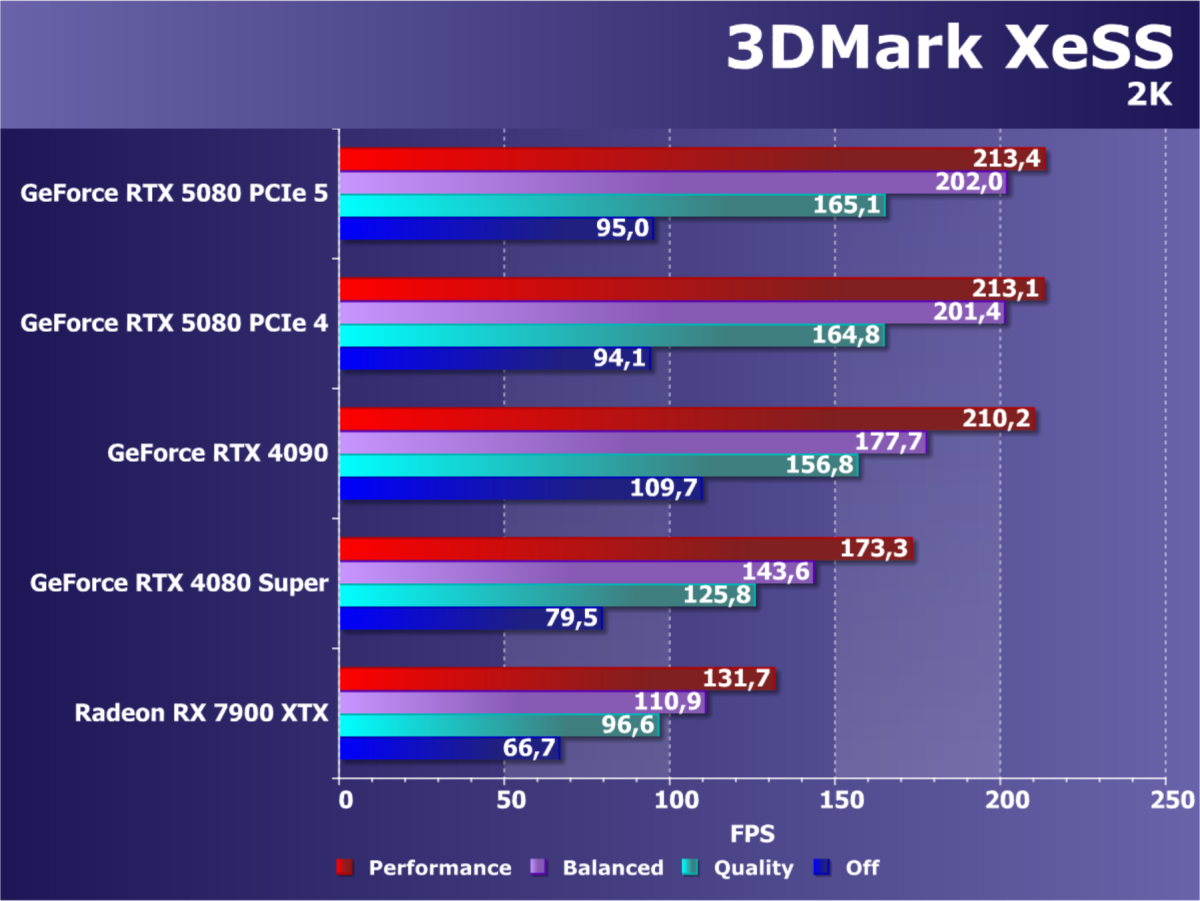
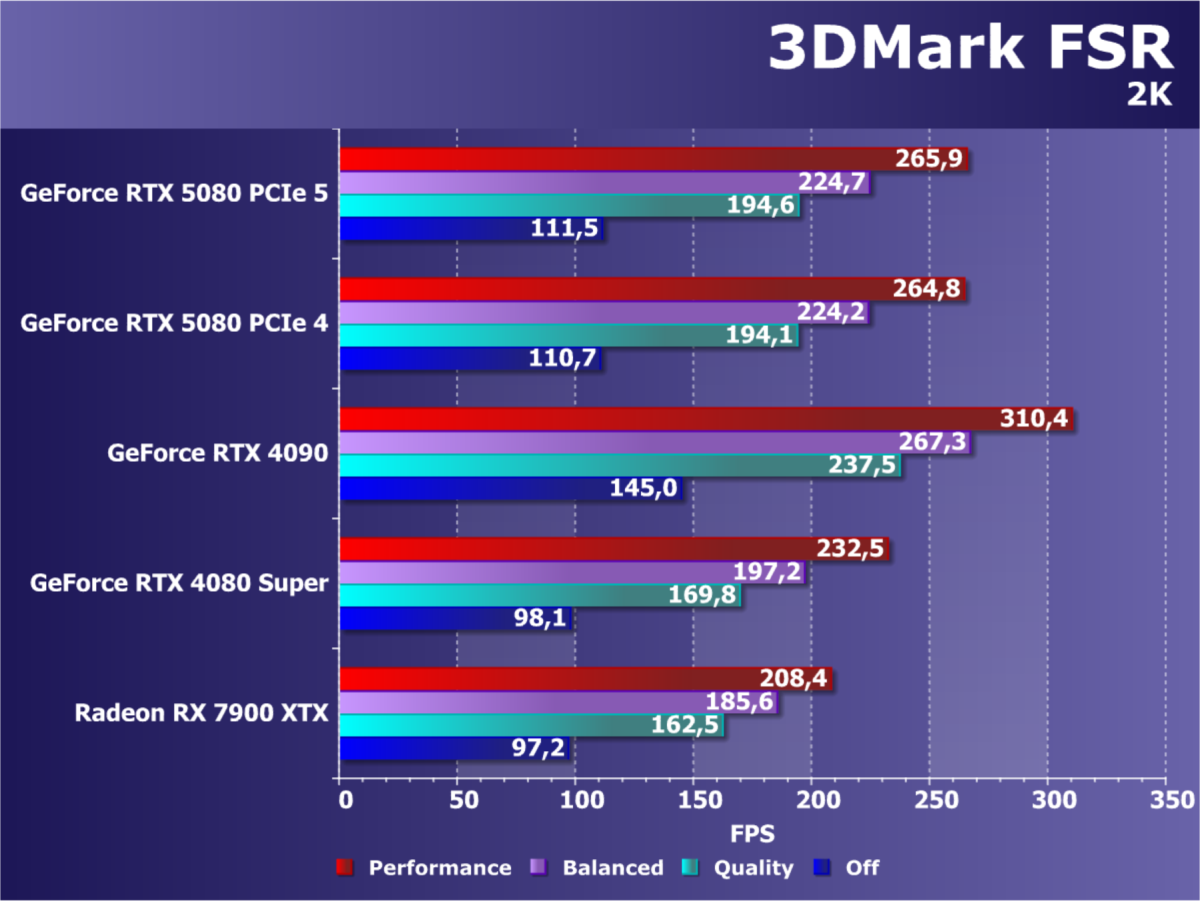

Тестирование: игровые тесты
Конфигурация тестового стенда
Список инструментов тестирования
Во всех игровых тестах использовалось максимальное качество графики в настройках.
- Black Myth: Wukong (Game Science/Game Science)
- Cyberpunk 2077 (Софтклаб/CD Projekt RED), патч 2.21 (январь 2025 г.)
- Senua’s Saga: Hellblade II (Ninja Theory/Xbox Games)
- Call of Duty: Modern Warfare II (Infinity Ward/Activision) (без трассировки и DLSS/FSR/XeSS!)
- Alan Wake 2 (Remedy/Epic Games)
- Ratchet and Clank: Rift Apart (Insomniac Games/Sony/Софтклаб)
- Ghost of Tsushima Director’s Cut (Sucker Punch Productions/Sony Interactive)
- Hogwarts Legacy (Avalance Software/Warner Bros)
- Avatar: Frontiers of Pandora (Ubisoft)
- Atomic Heart (Mundfish/VK)
- Indiana Jones and the Great Circle (Machine Games/Bethesda Softworks) (с RT и DLSS/FSR/XeSS!)
Кратко о производительности в 3D-играх
Перед демонстрацией детальных тестов мы приводим краткие сведения о производительности семейства, к которому относится конкретный исследуемый ускоритель, а также его соперников. Всё это нами субъективно оценивается по шкале из семи градаций.
Игры без использования трассировки лучей (классическая растеризация):
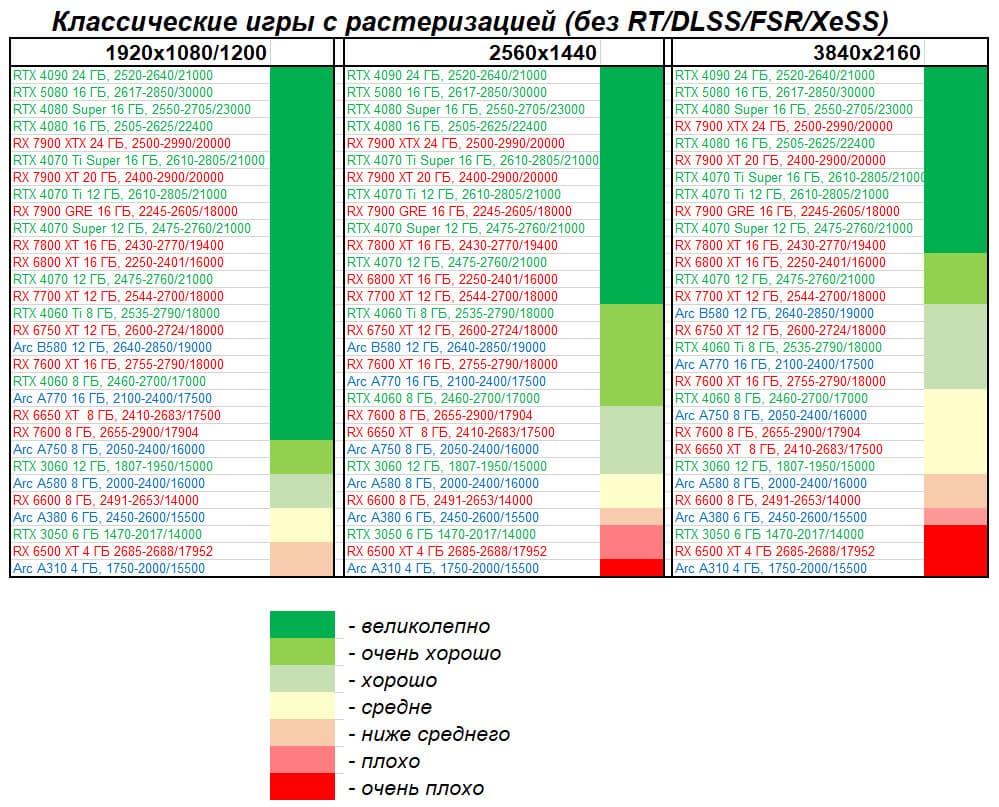
GeForce RTX 5080 занимает второе место в списке протестированных нами карт (ждем GeForce RTX 5090). Такие флагманские решения порой не могут раскрыть свой потенциал в классических играх даже в разрешении 4K — общая игровая производительность ограничивается системными ресурсами, в основном производительностью CPU. Здесь вердикт прост: можно играть на самых высоких настройках графики в любом разрешении, включая 4K (2160p), а в ряд игр — даже в 8K.
Игры с использованием трассировки лучей и DLSS/FSR/XeSS:
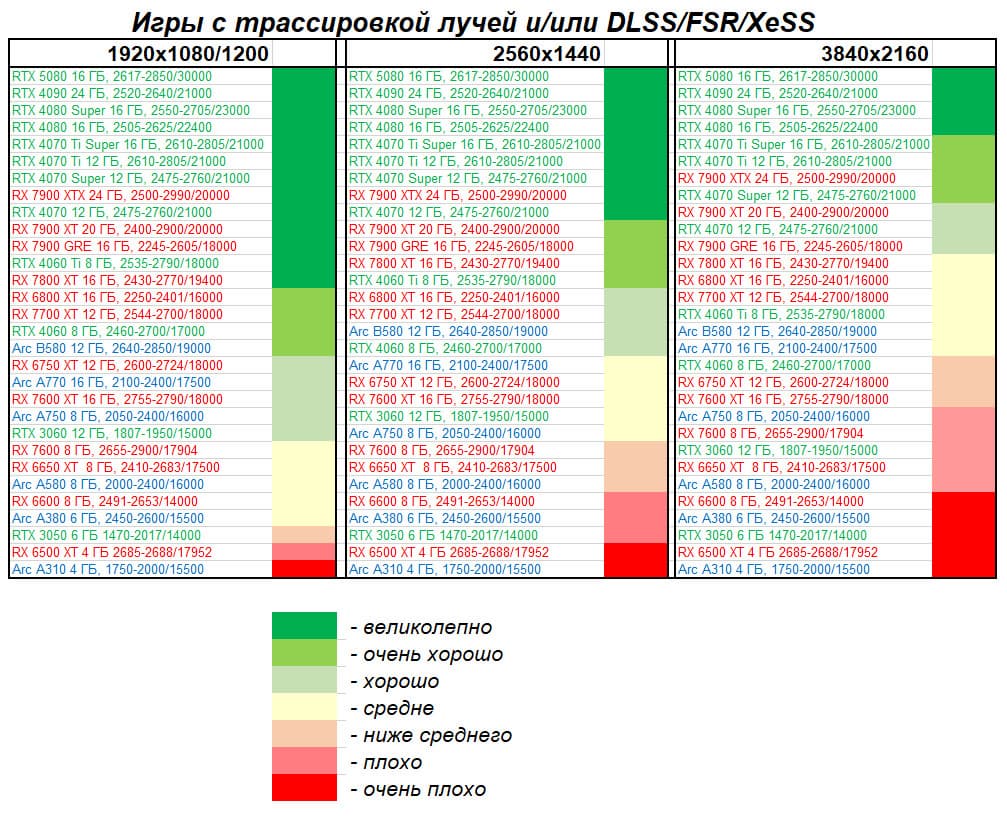
Опять же, во все игры можно играть с высокими настройками графики даже в 4K, включив трассировку лучей, и использование динамического масштабирования (апскейлинга) не является необходимым. А использование DLSS 3, не говоря уж о DLSS 4, обеспечит очень неплохую прибавку FPS в разрешении 8K (правда, не во всех играх поддерживается работа DLSS в 8K, да и наличие 16 ГБ локальной видеопамяти уже станет обязательно).
Более того, по производительности в играх при включении RT и DLSS карта GeForce RTX 5080 оказывается самой быстрой, опережая GeForce RTX 4090. Дело в том, что из десяти тестовых игр три уже поддерживают DLSS4 с MFG, в них показатели GeForce RTX 5080 заметно выше, что и повлияло на общий итог. Считать ли такую производительность «честной», мы оставляем решать нашим читателям.

Результаты тестирования в 3D-играх
Стандартные результаты тестов без использования аппаратной трассировки лучей в разрешениях 1920×1080, 2560×1440 и 3840×2160
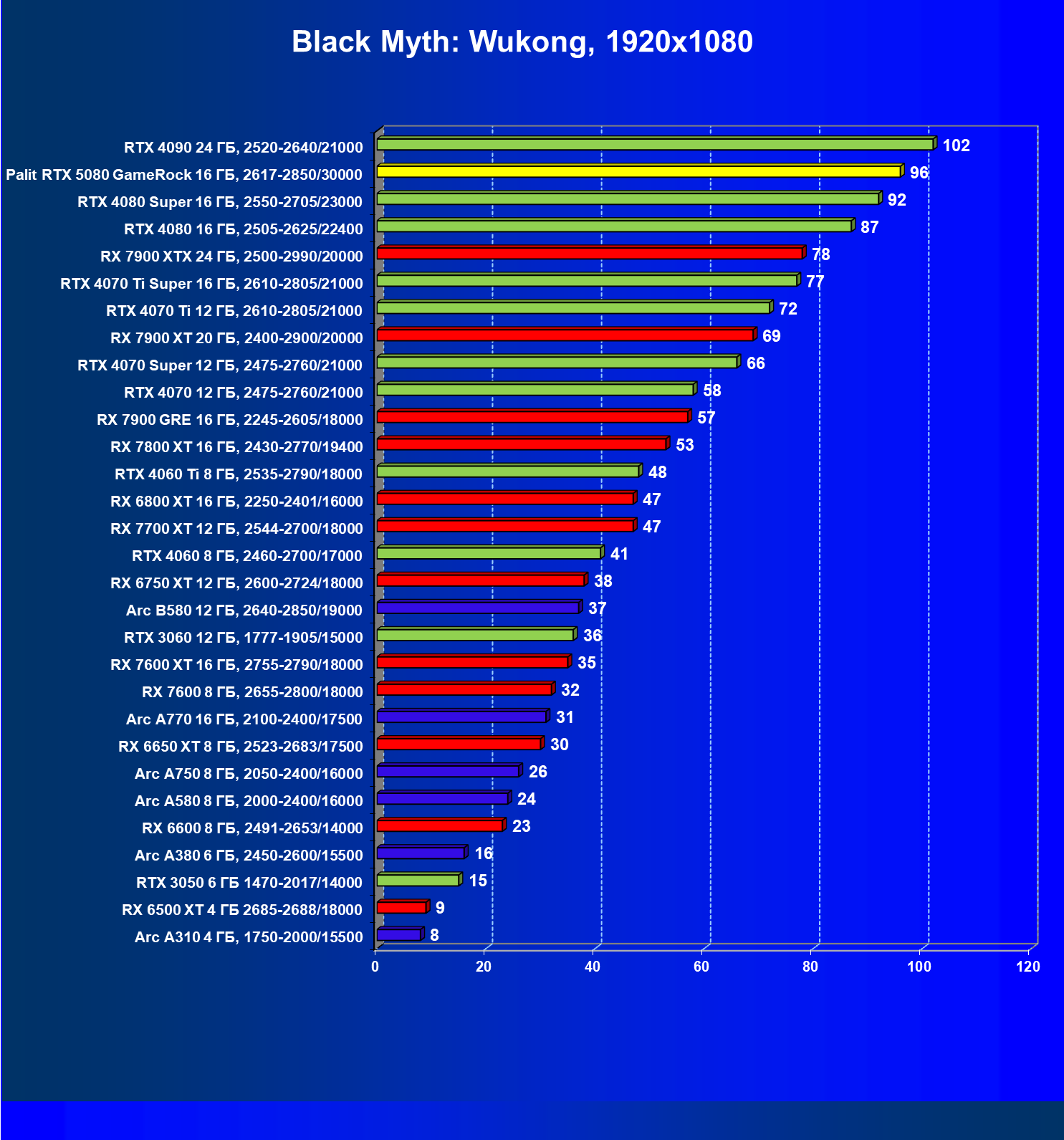
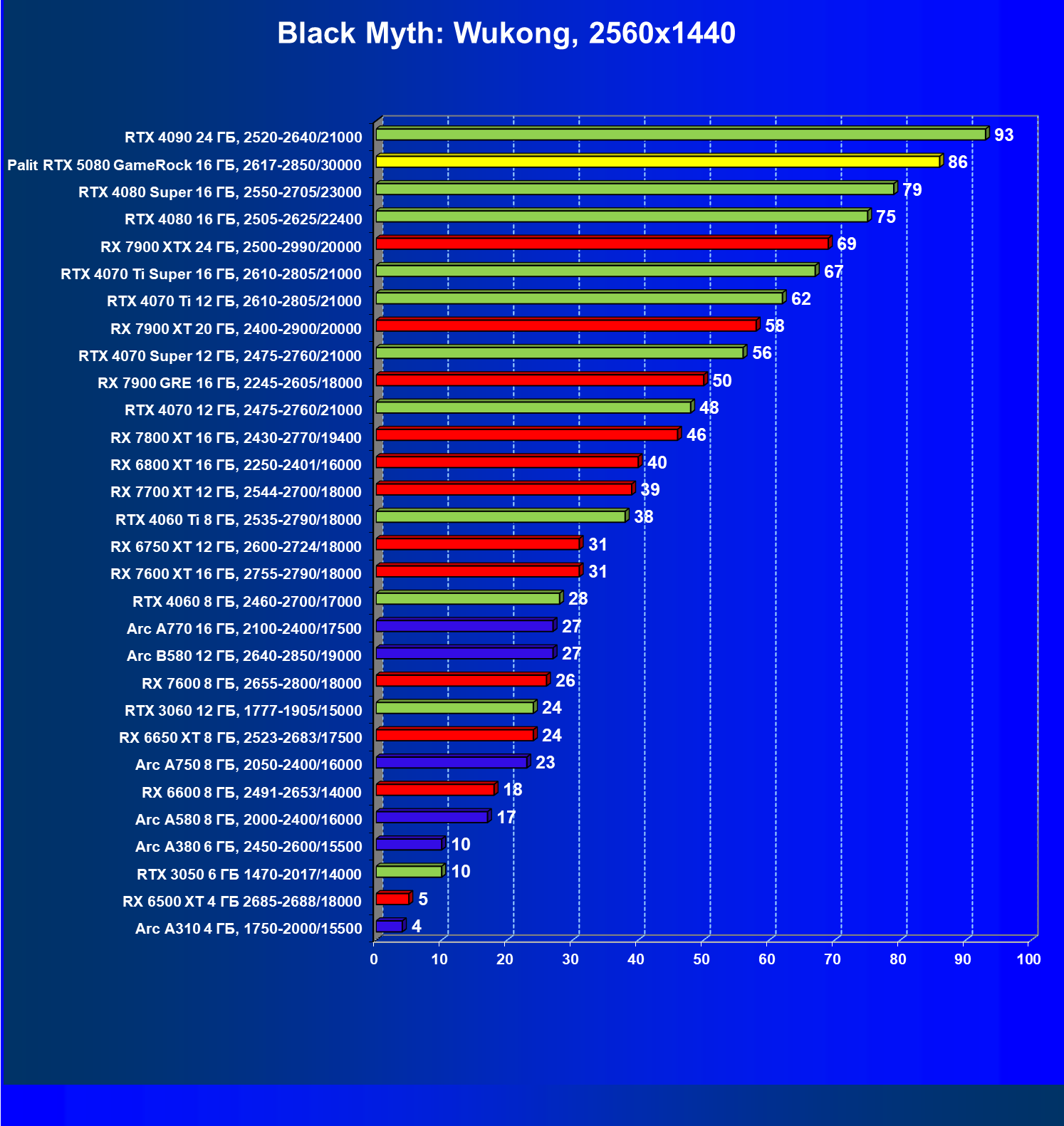
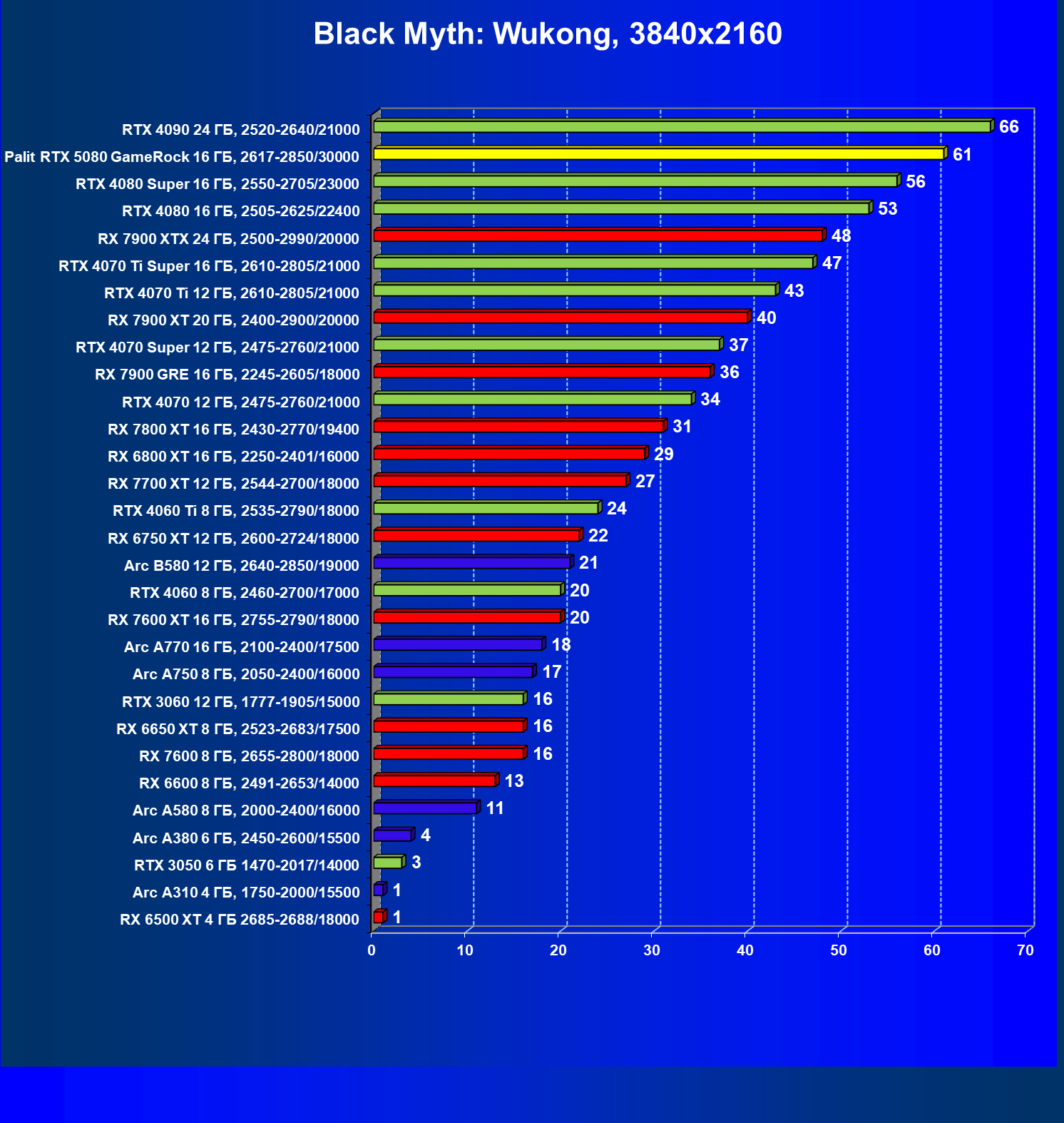
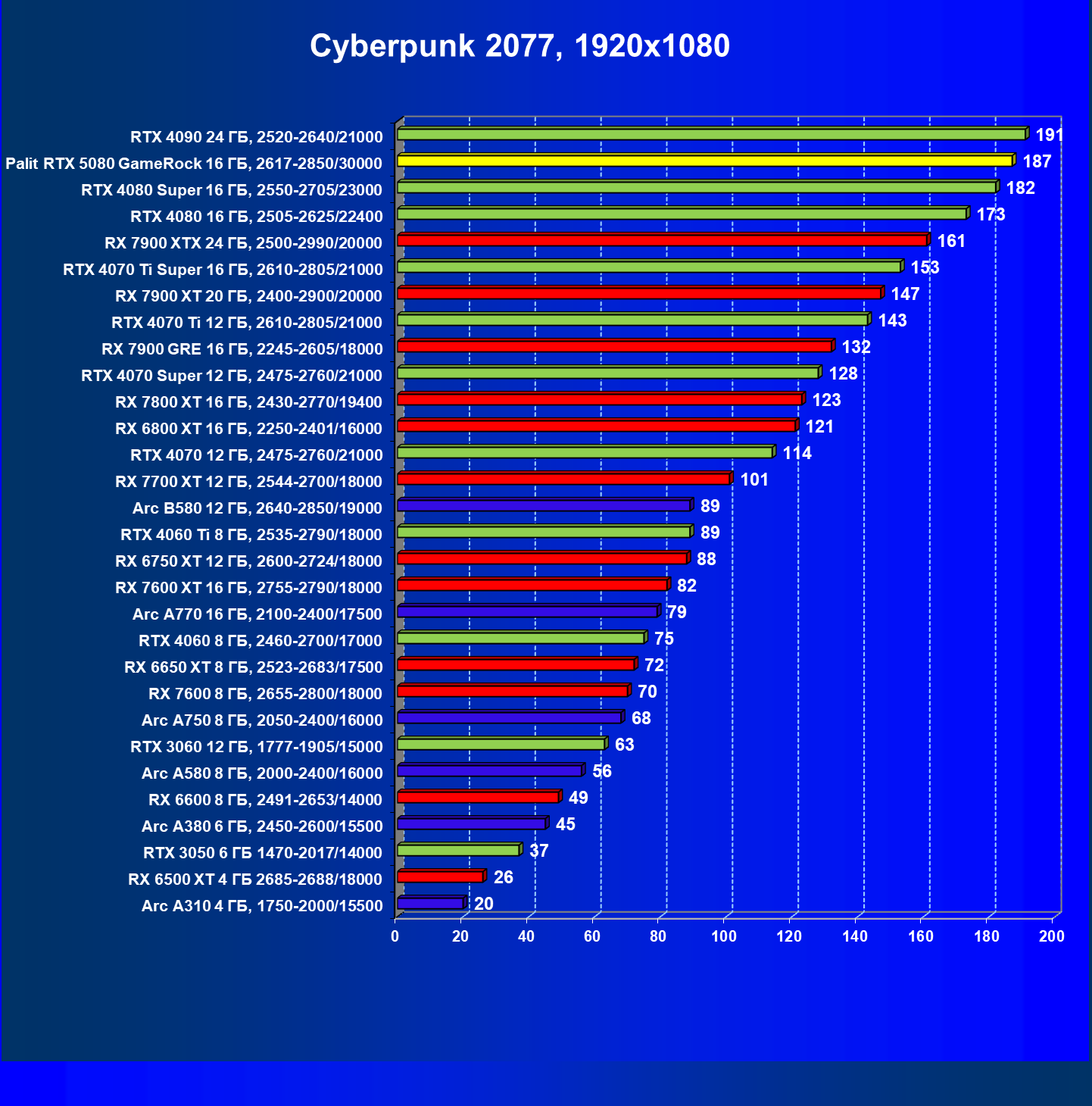
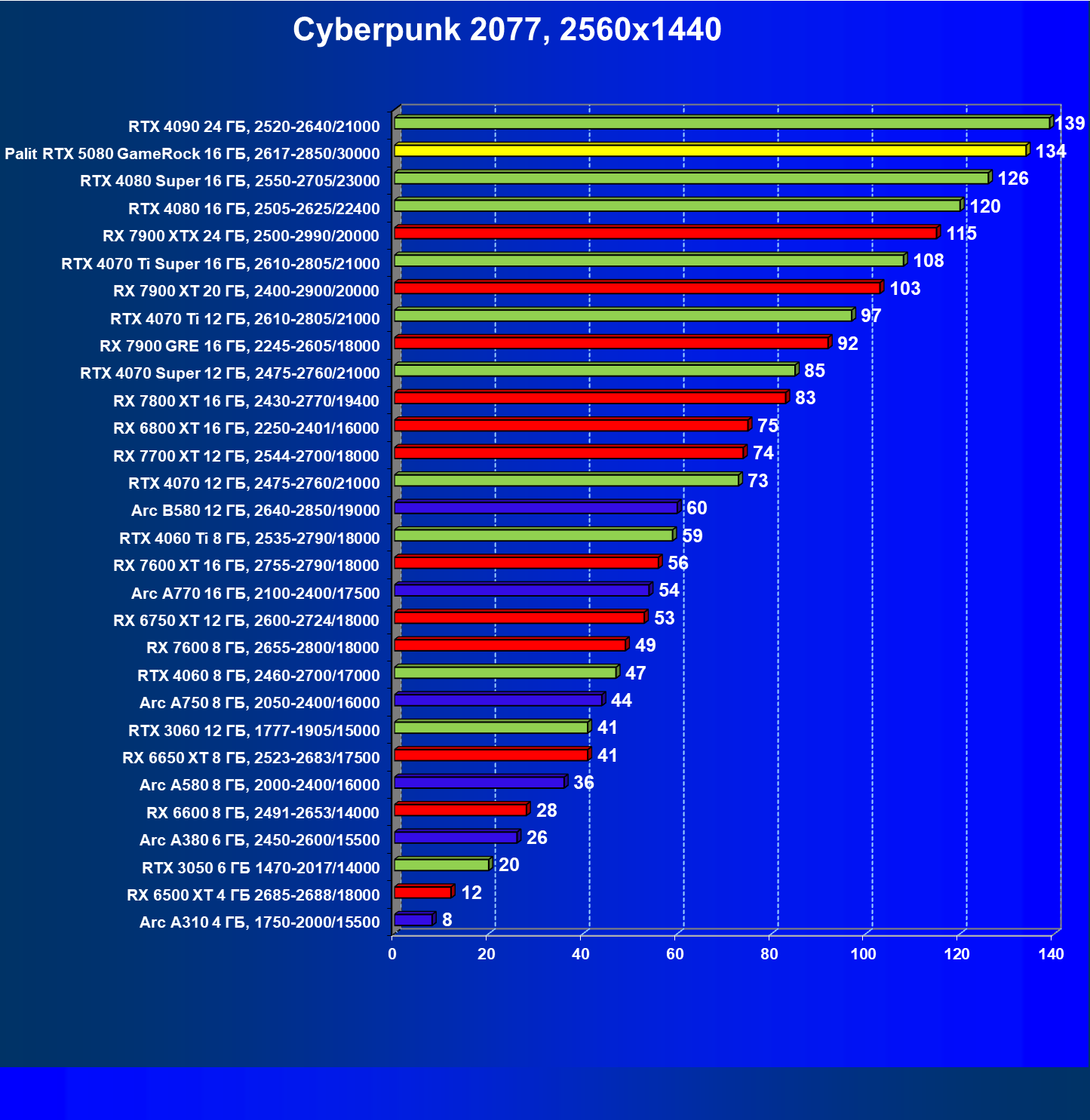
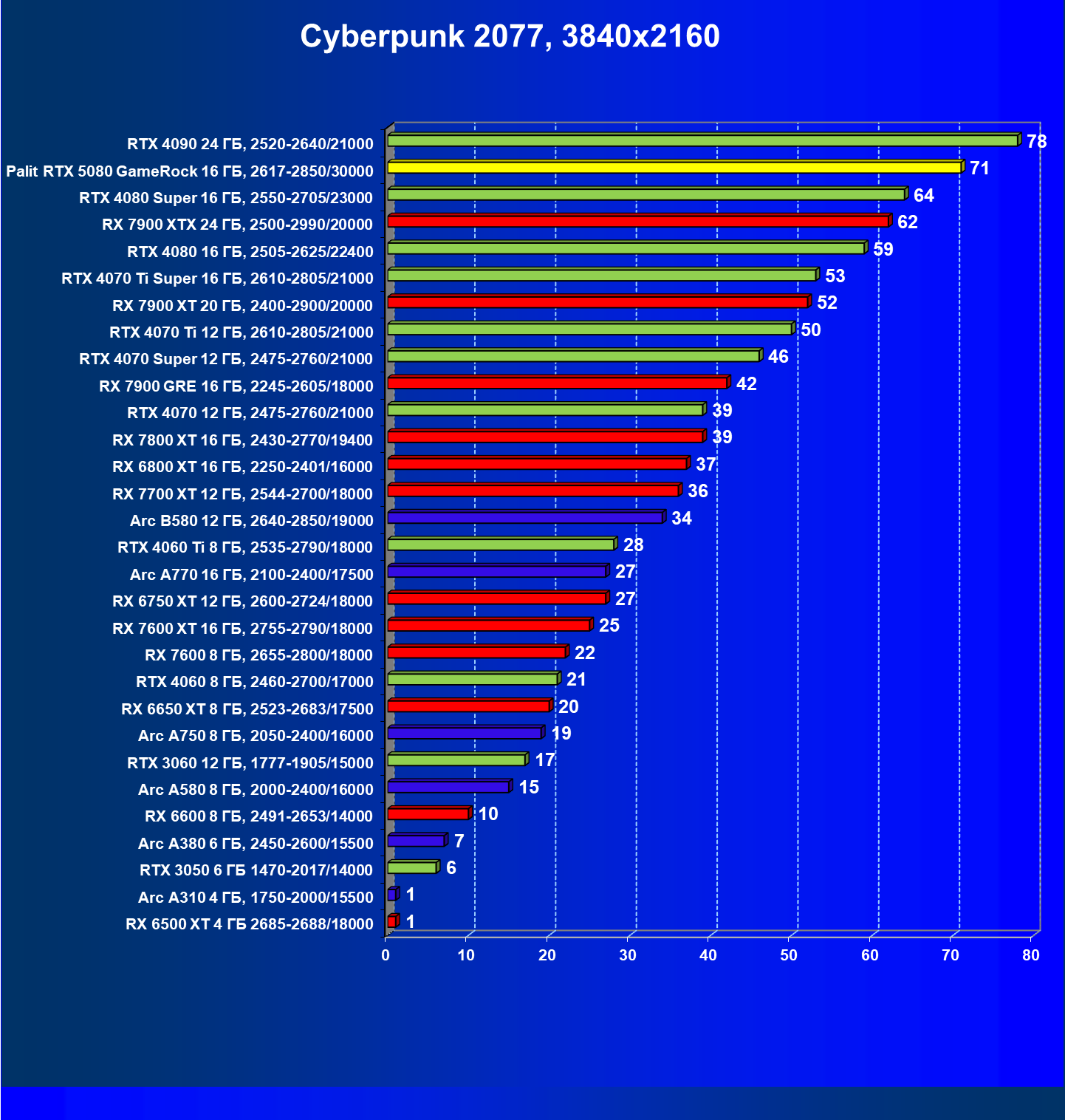
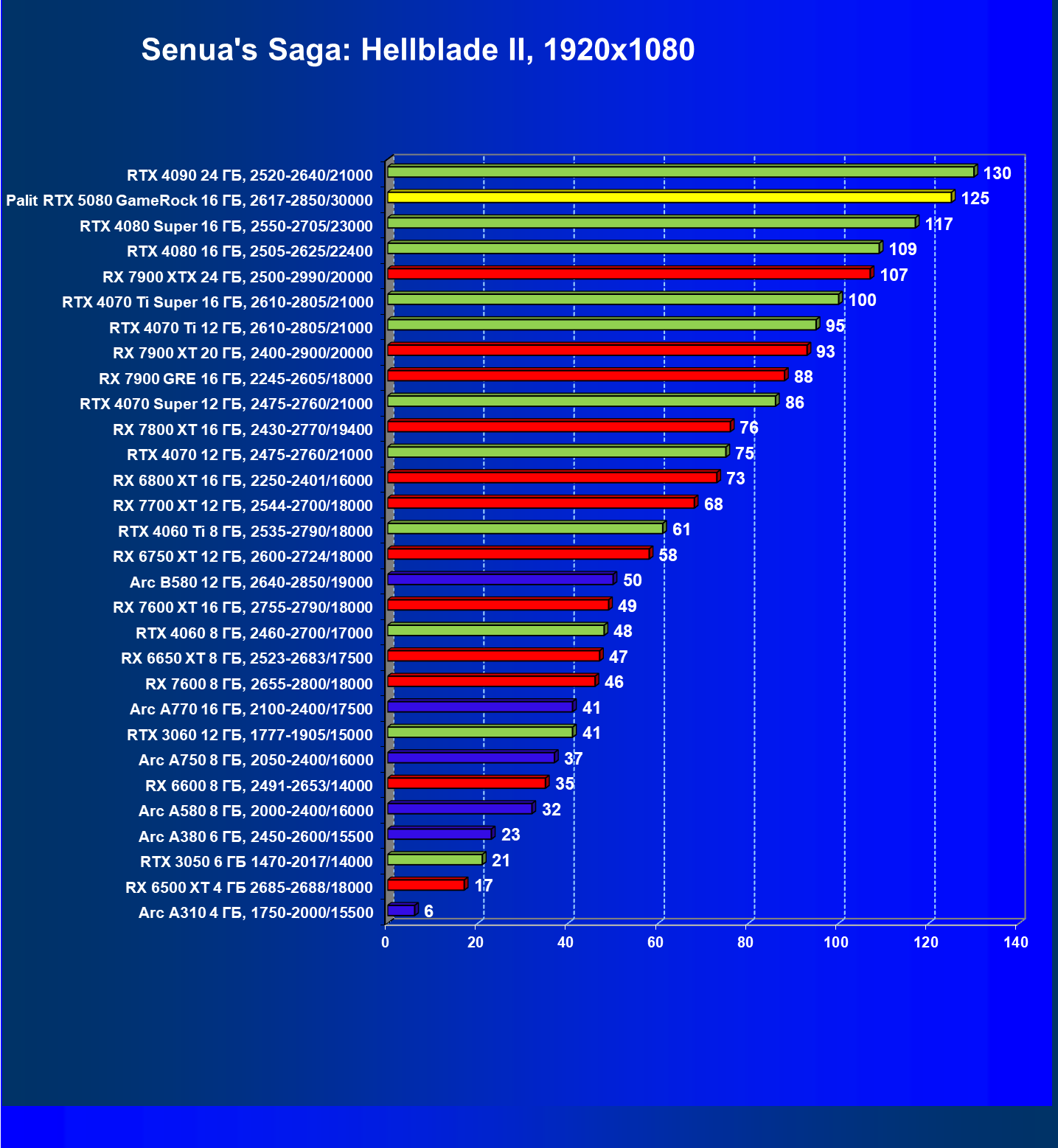
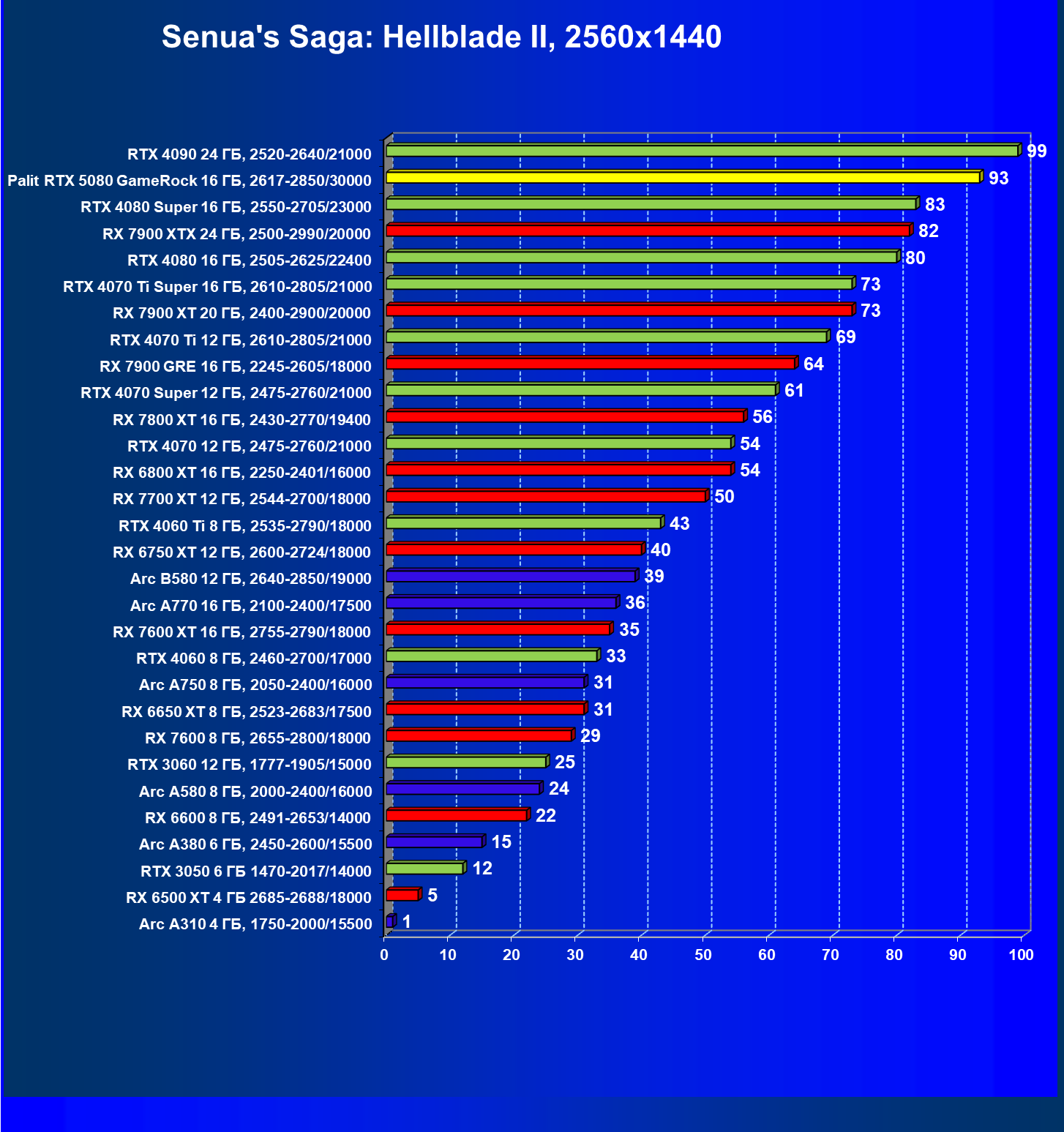
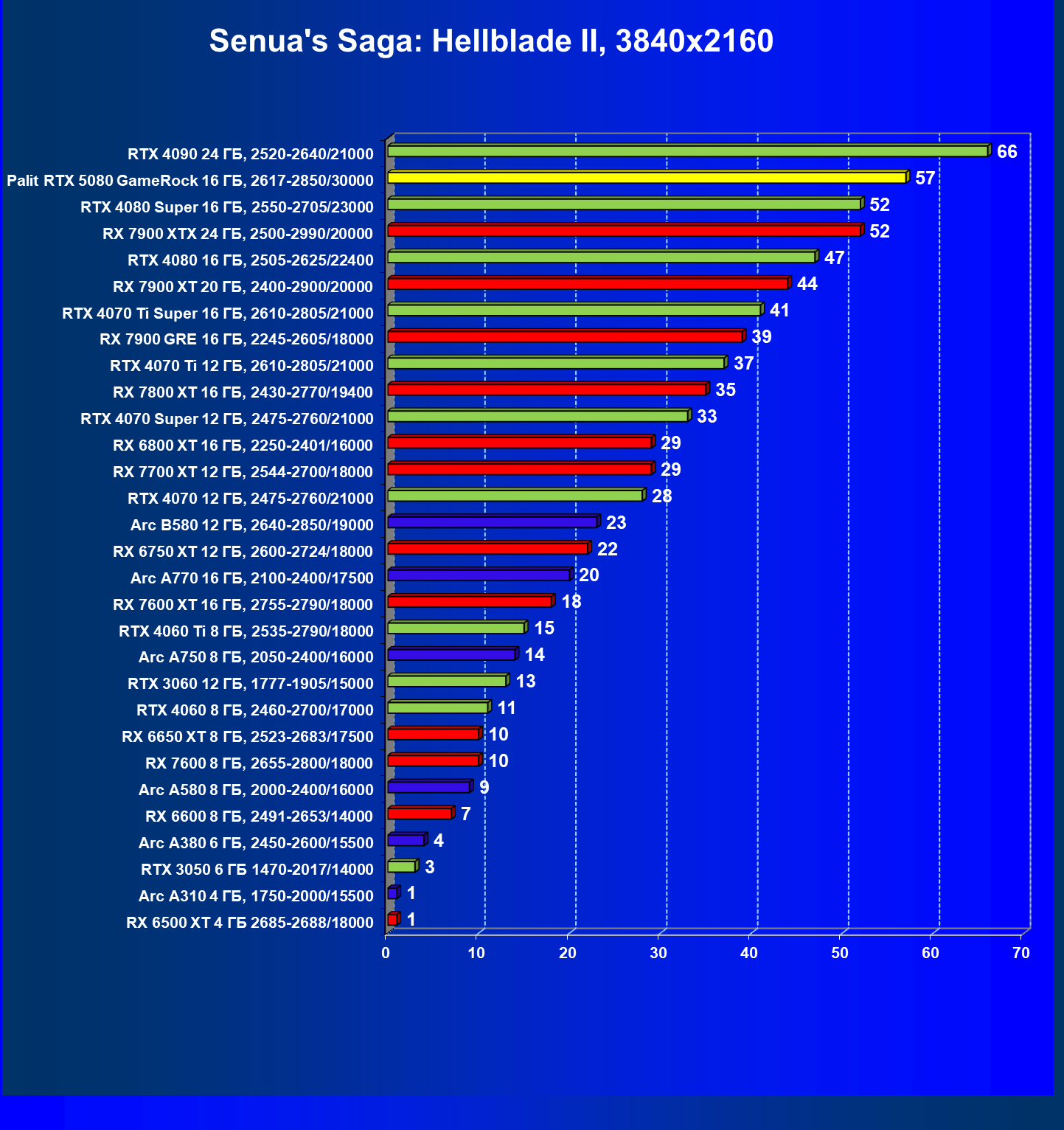
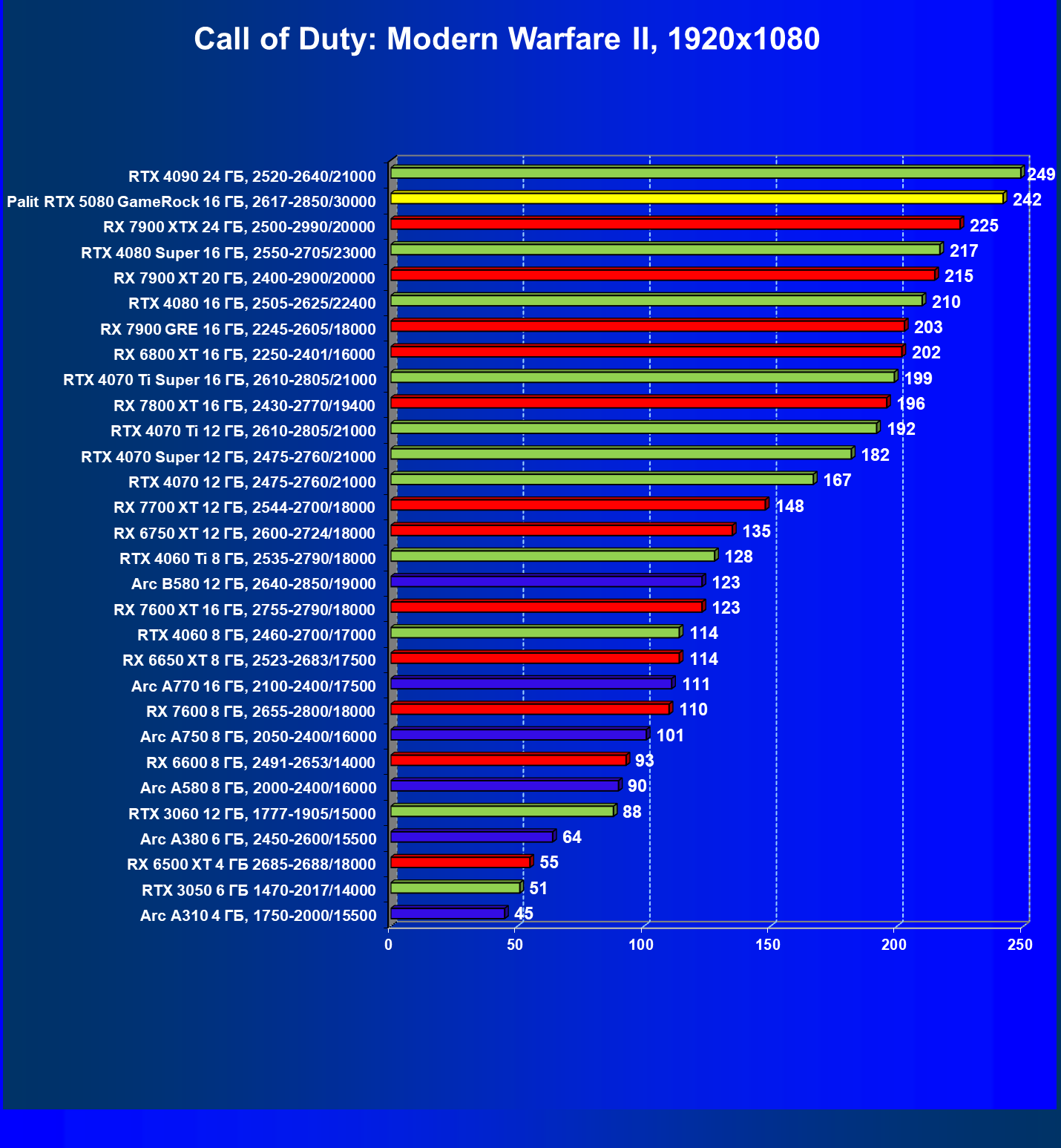
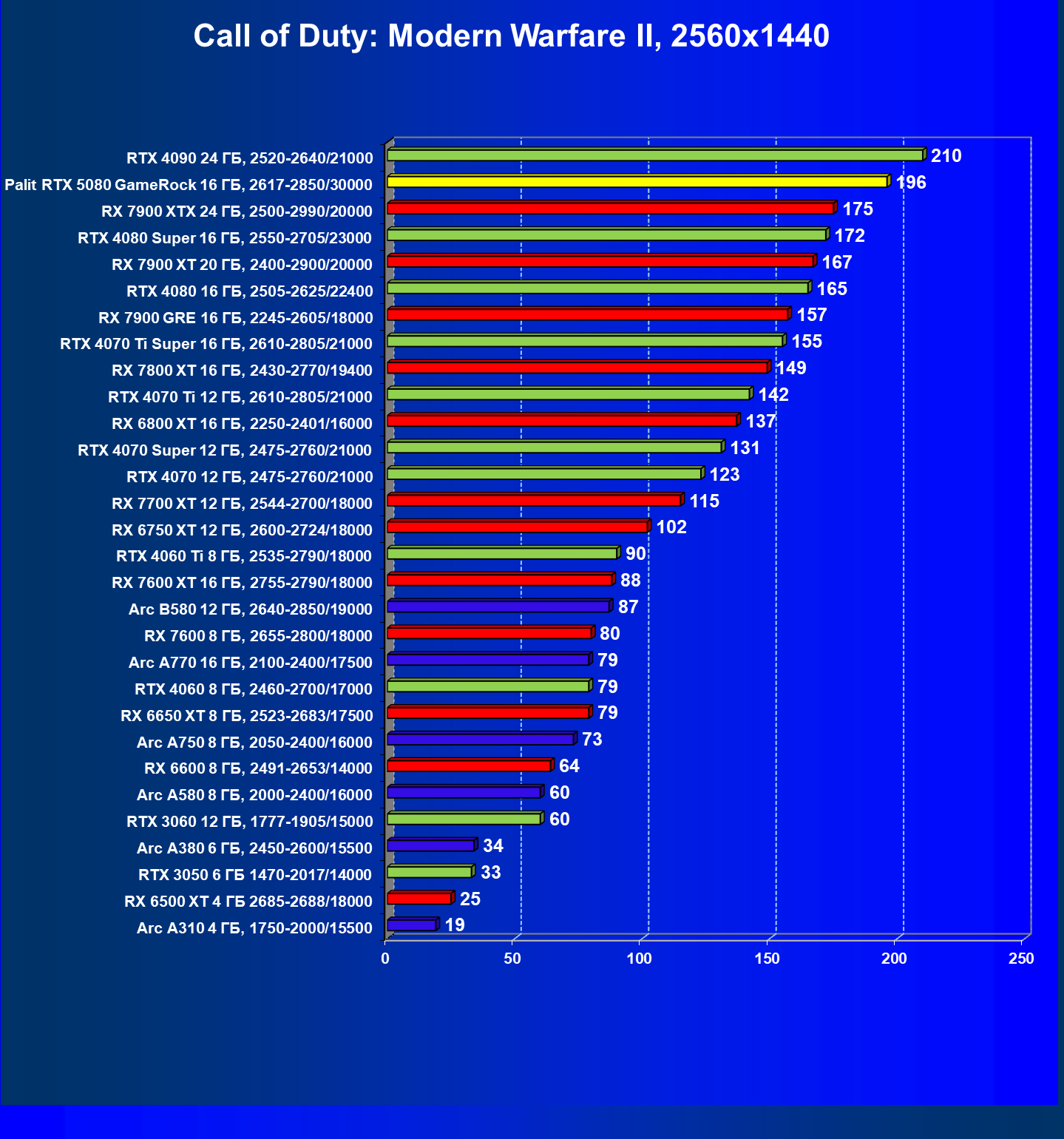
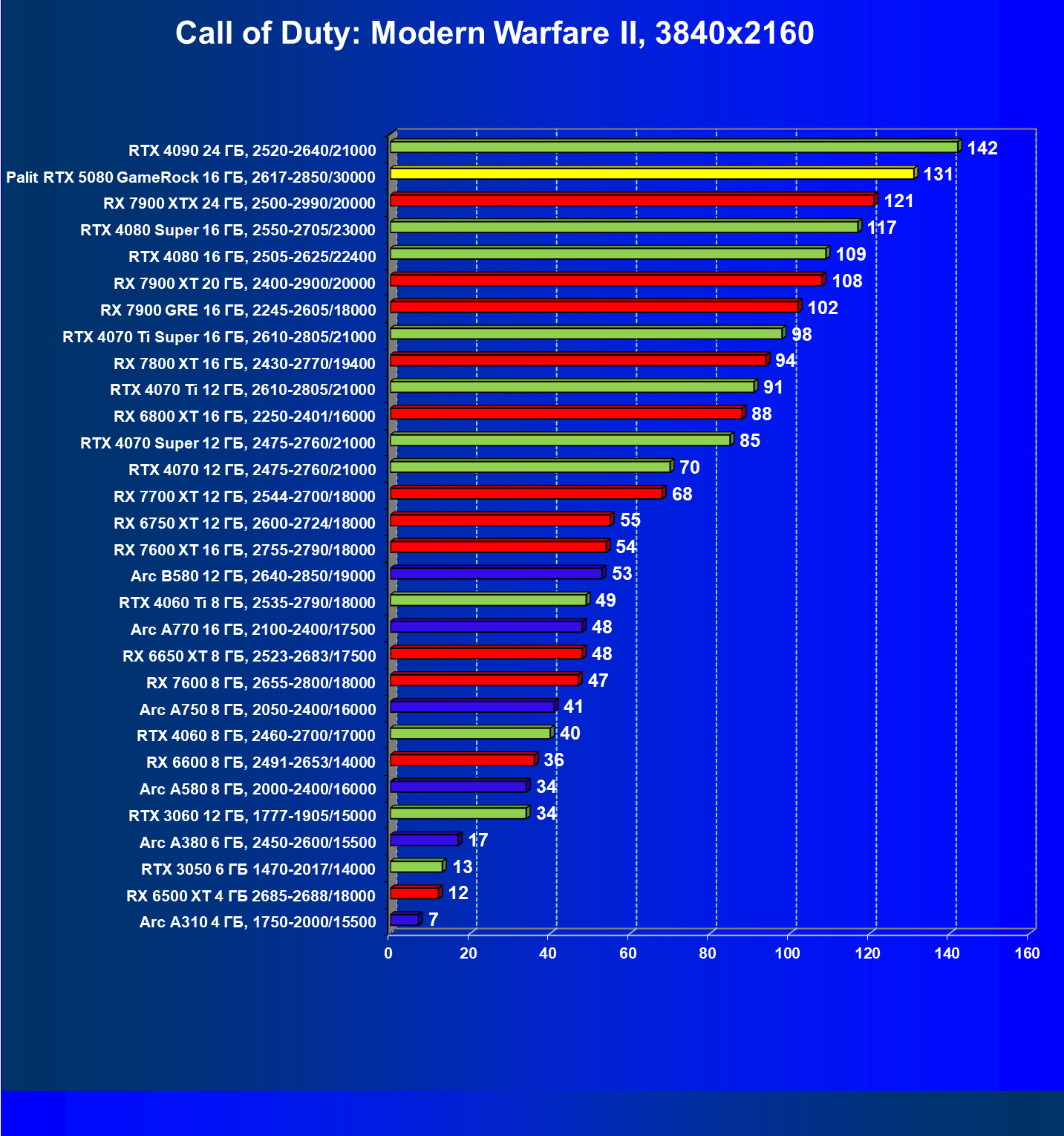
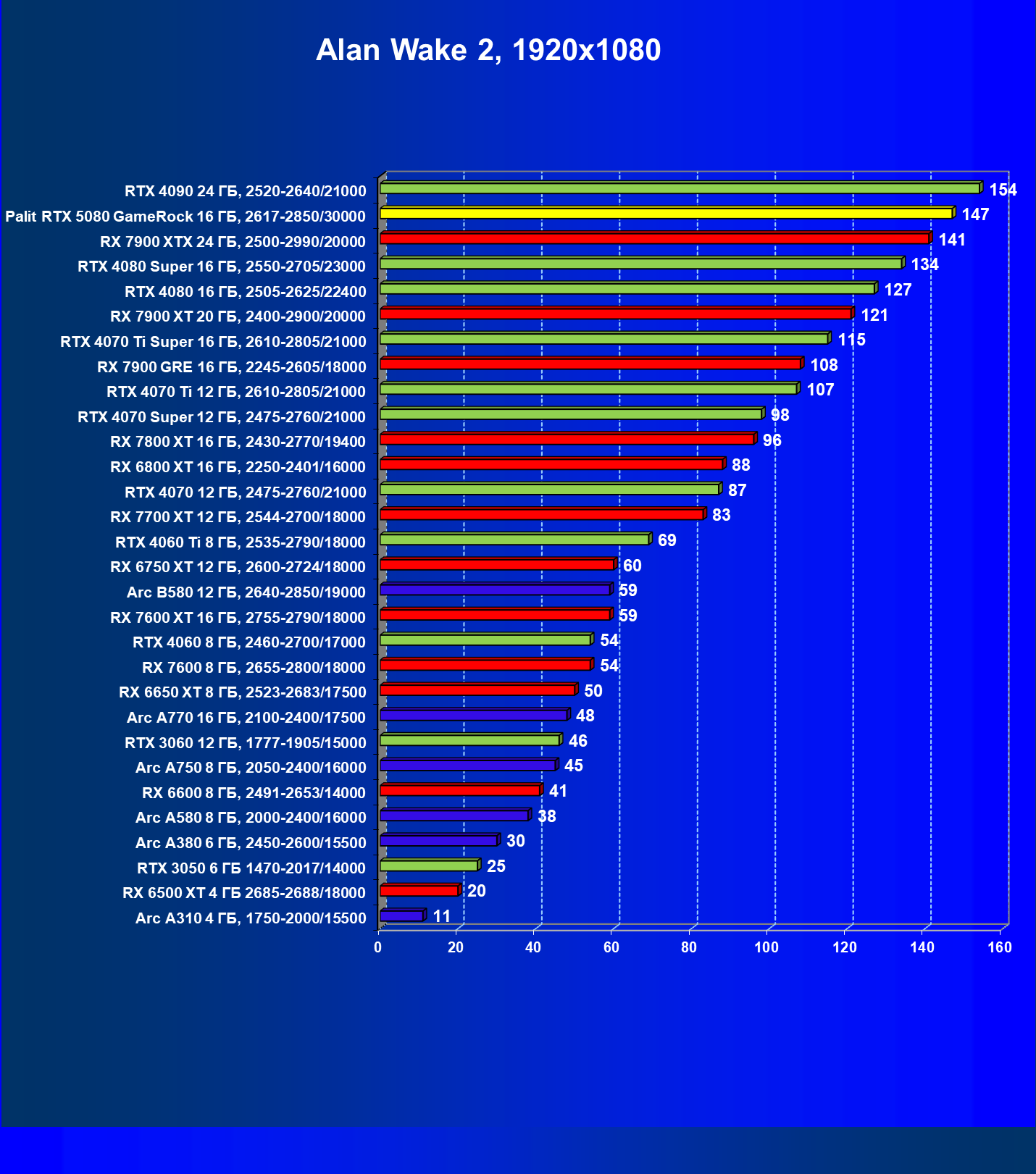
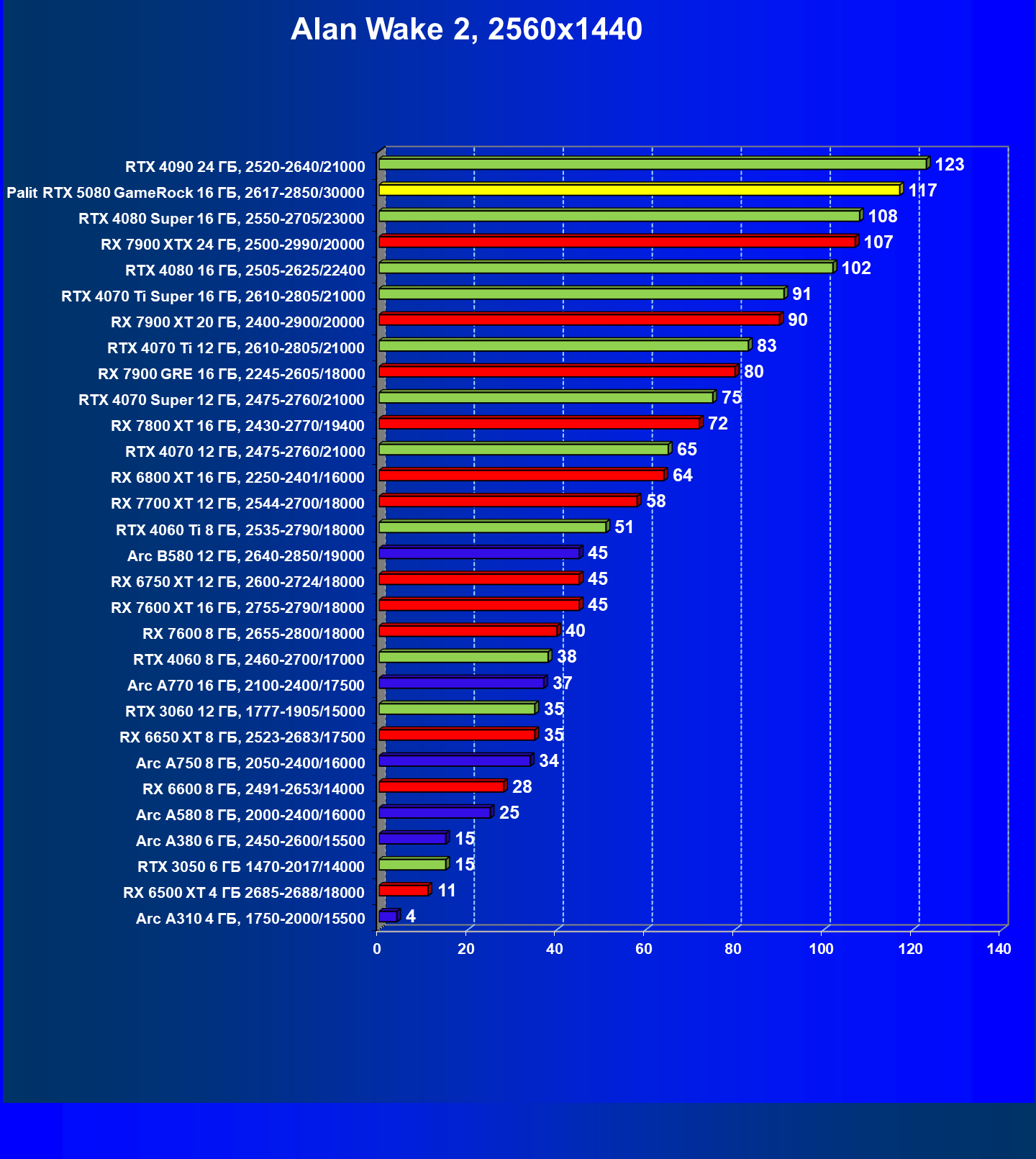

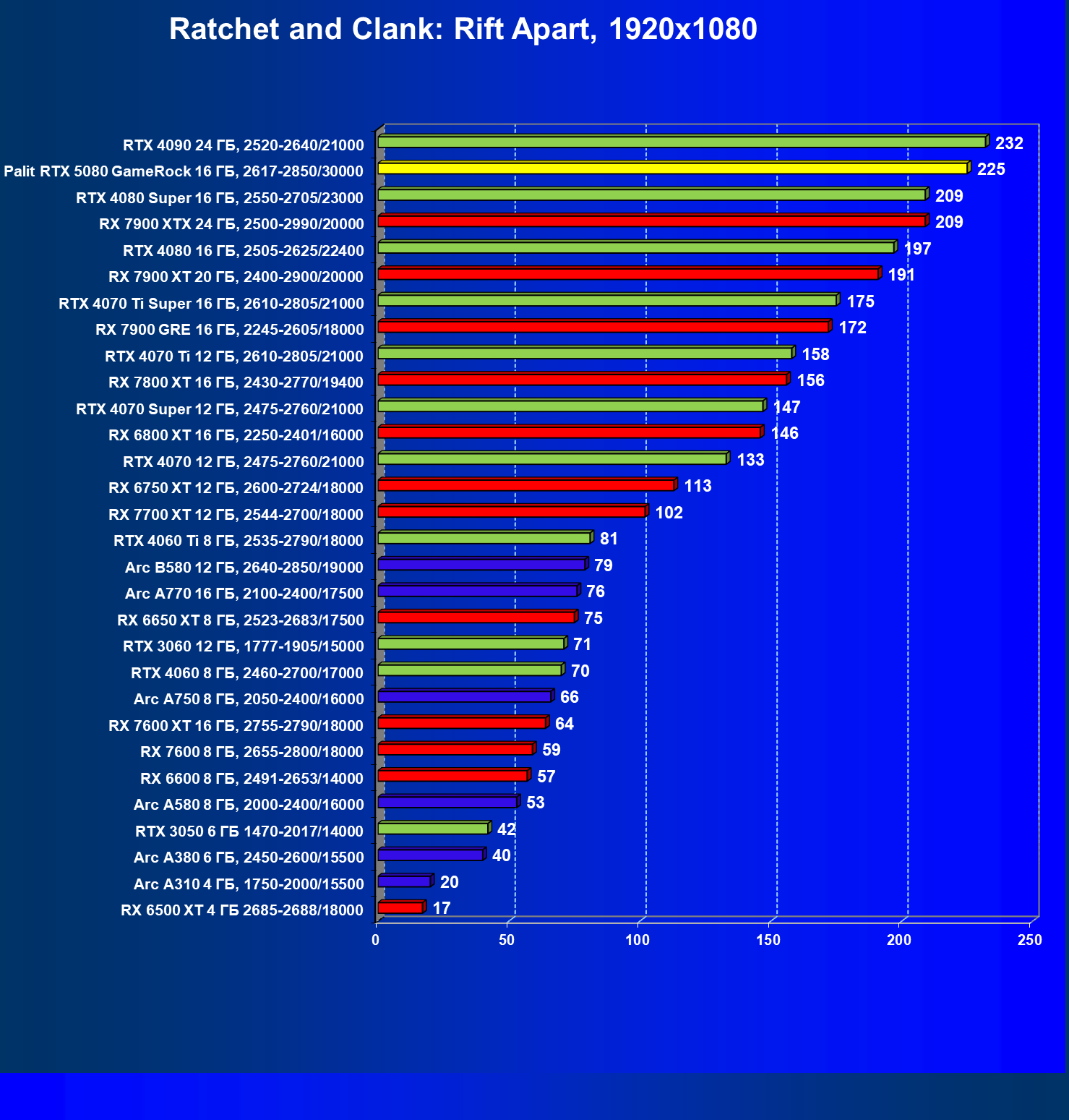
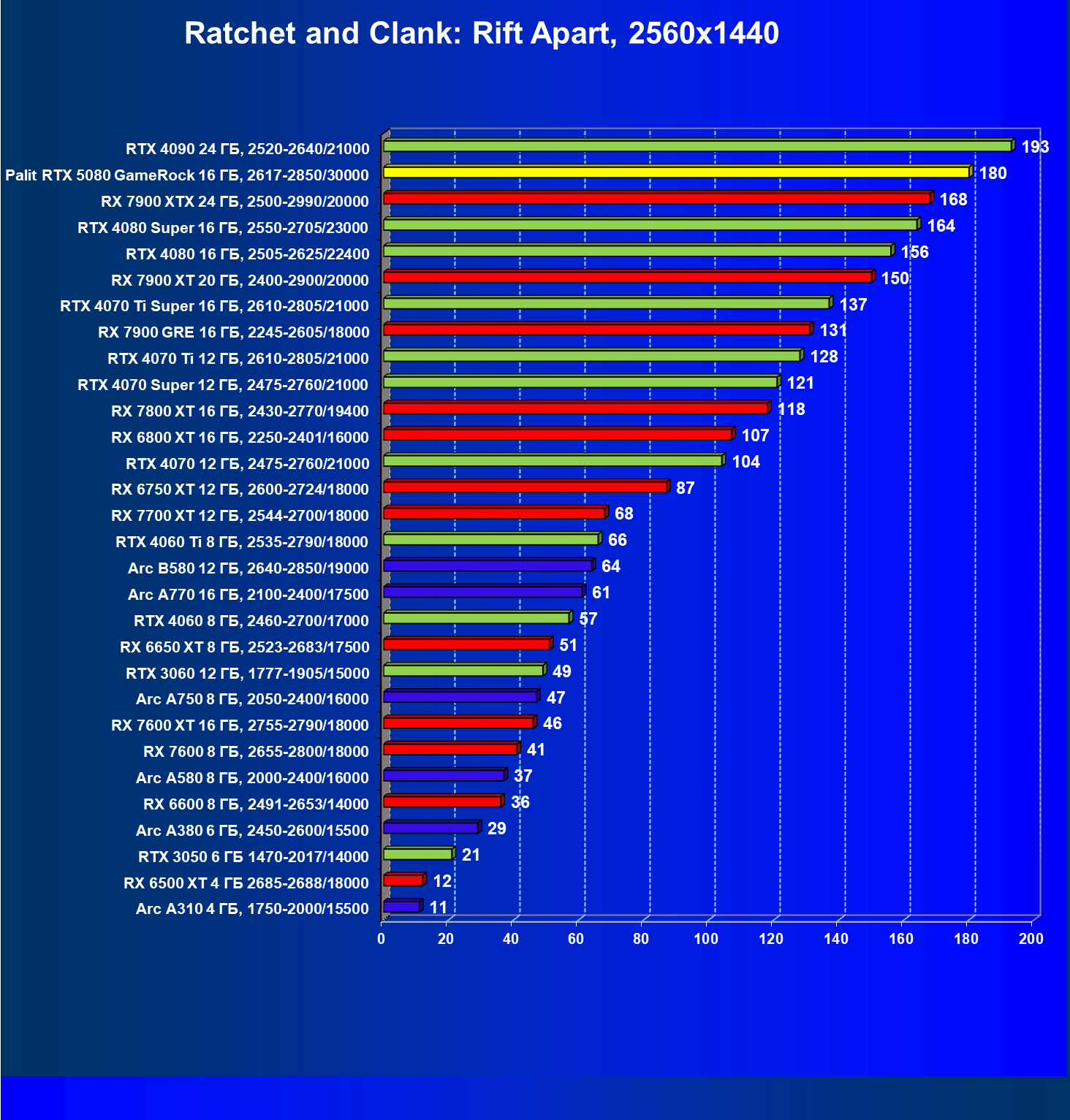
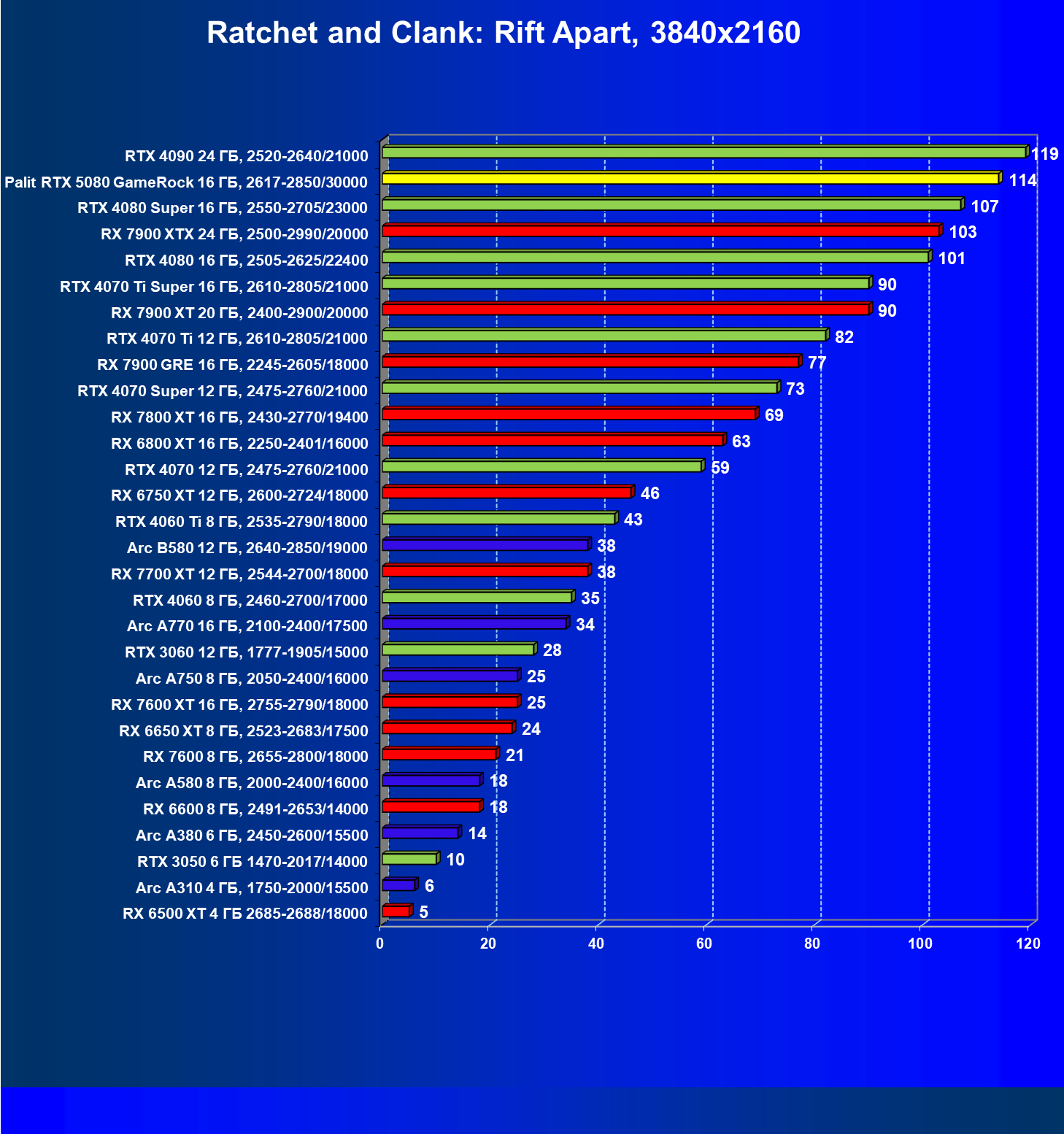
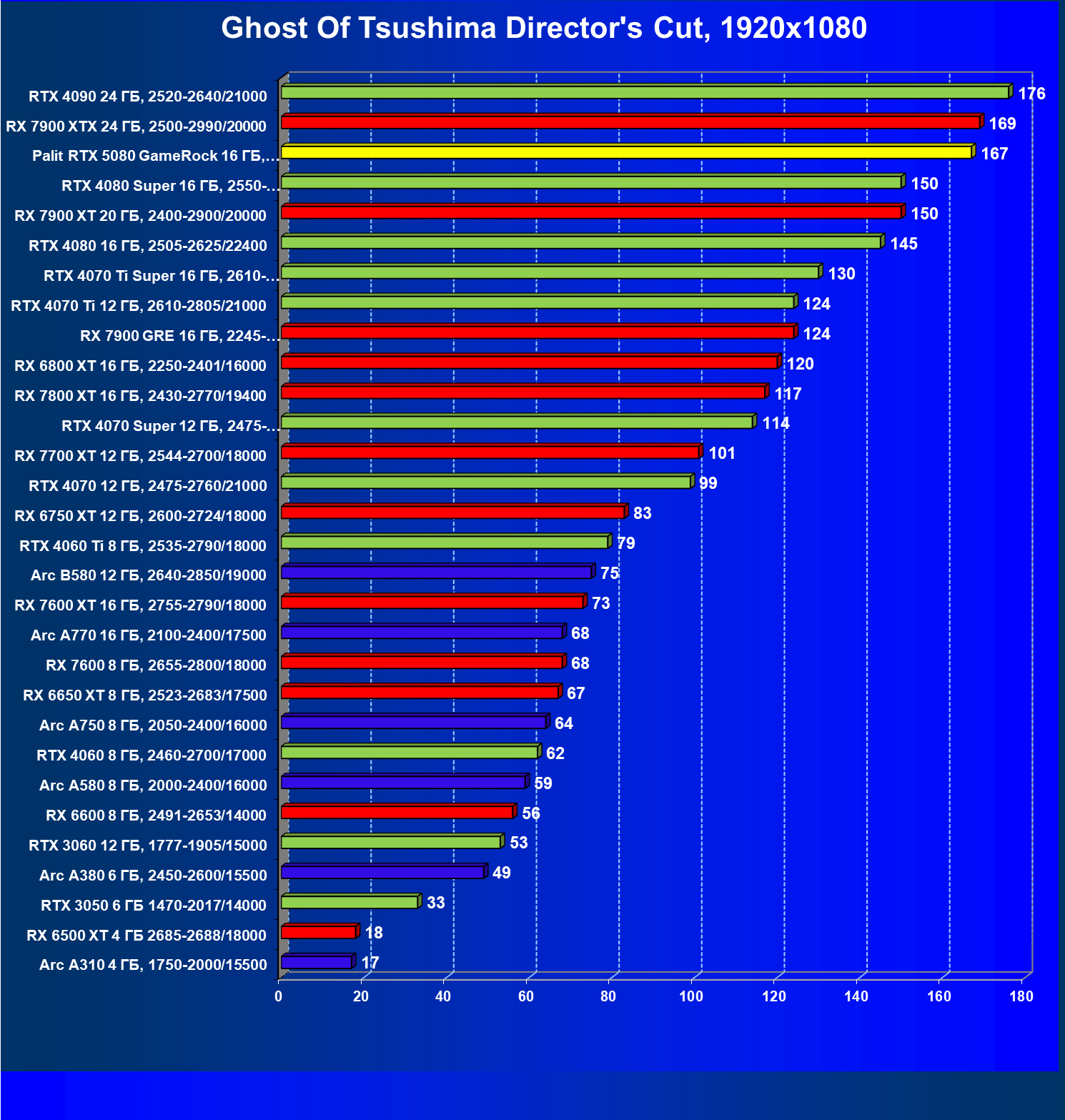
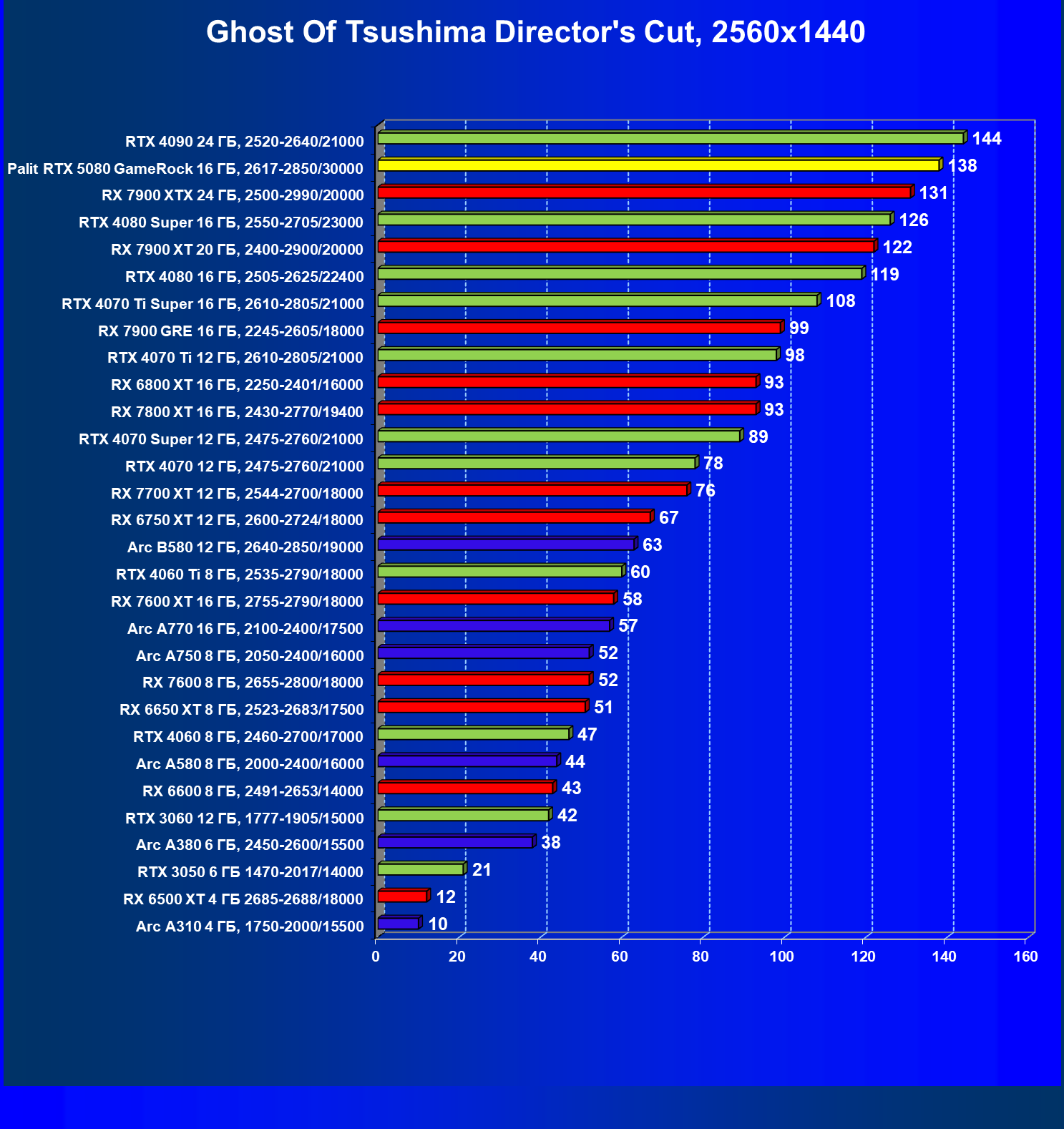
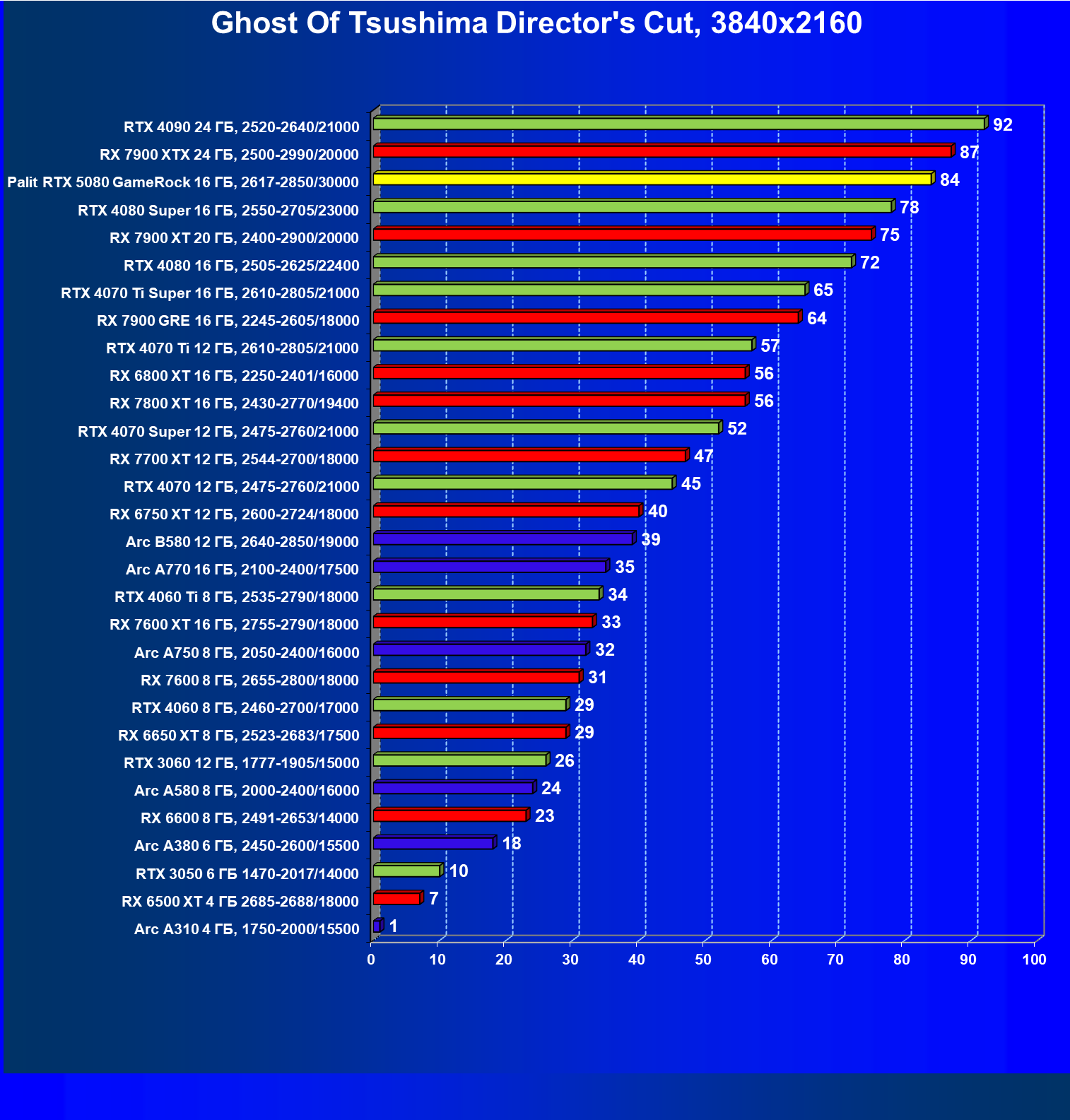
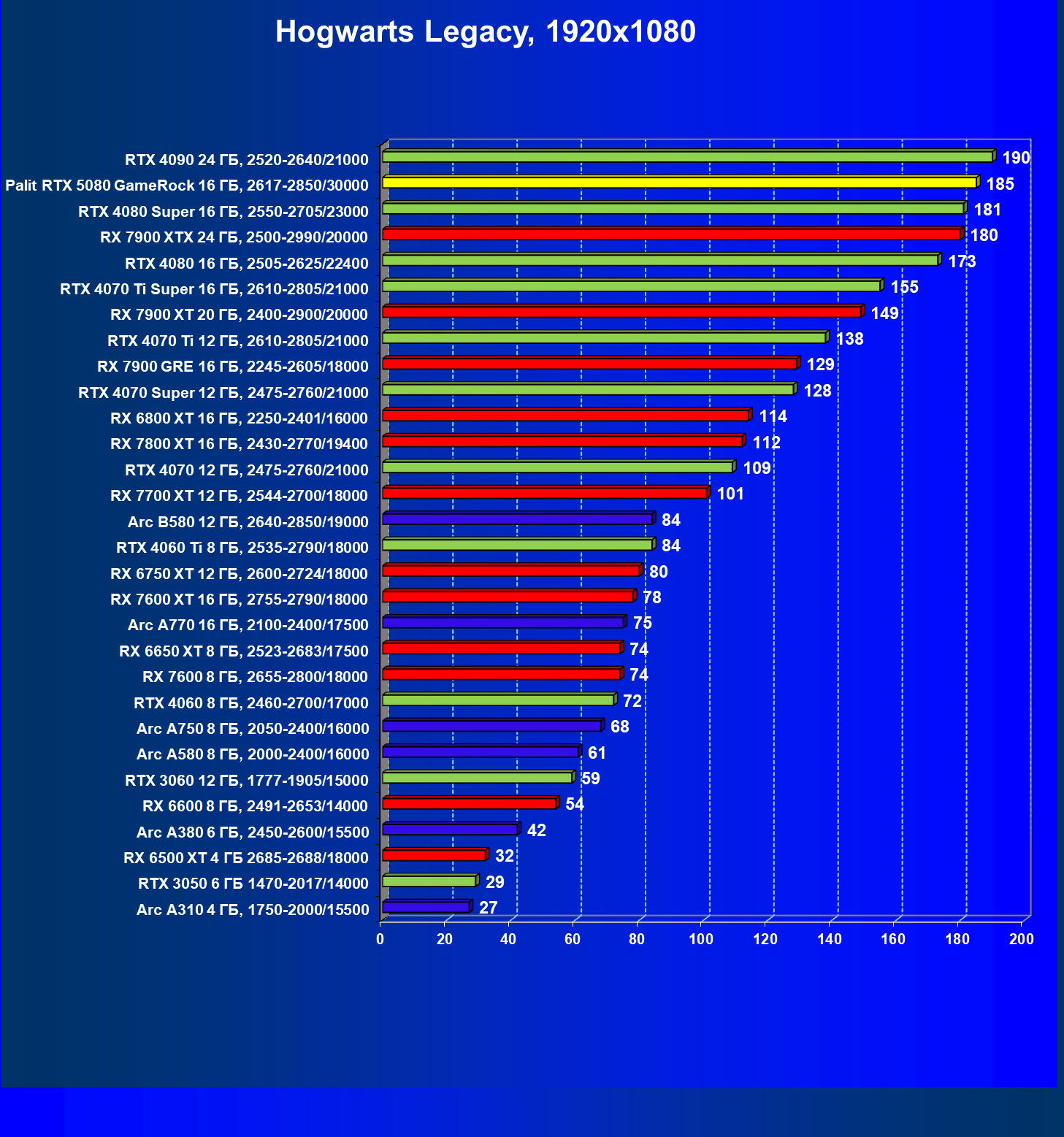
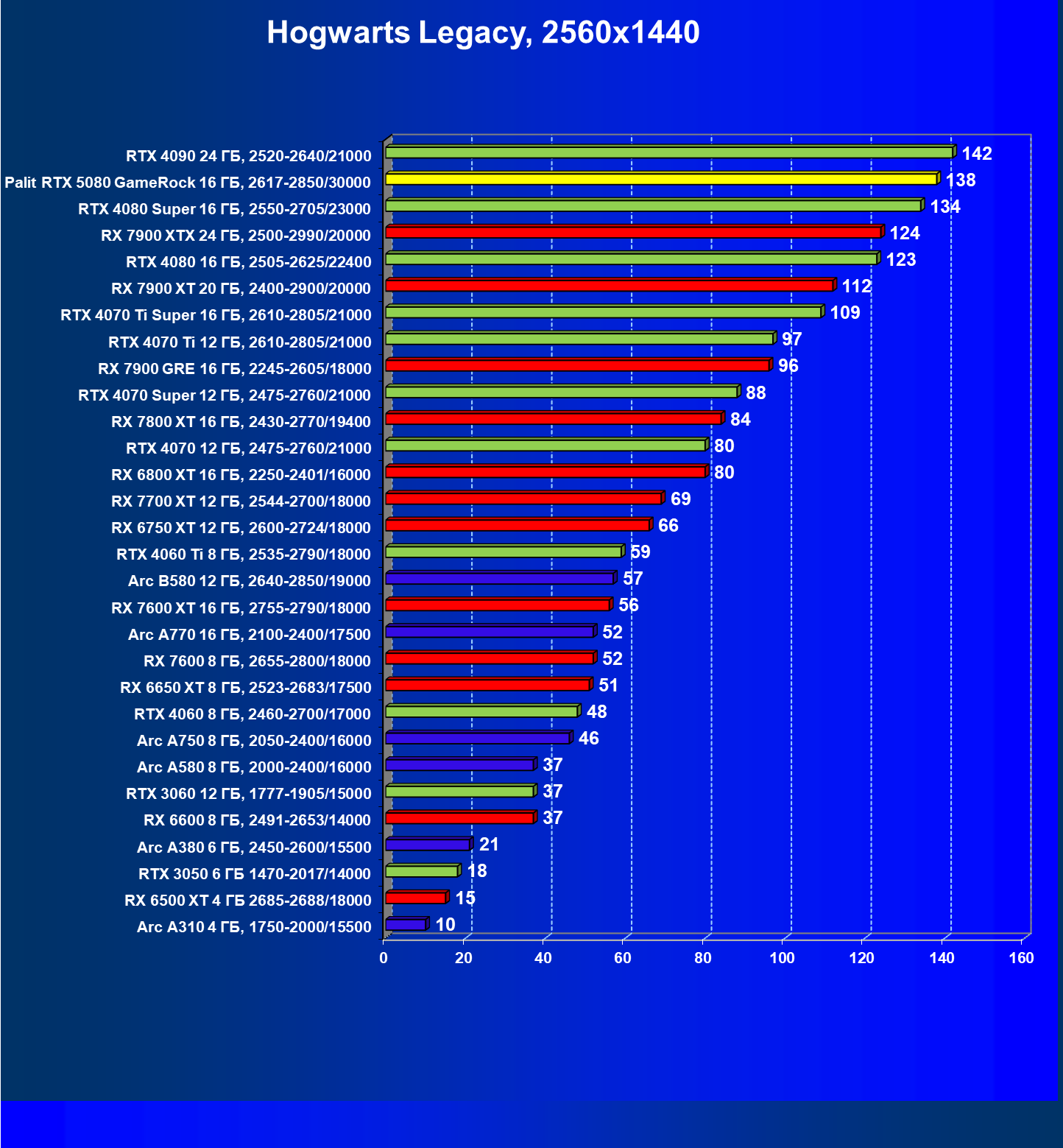

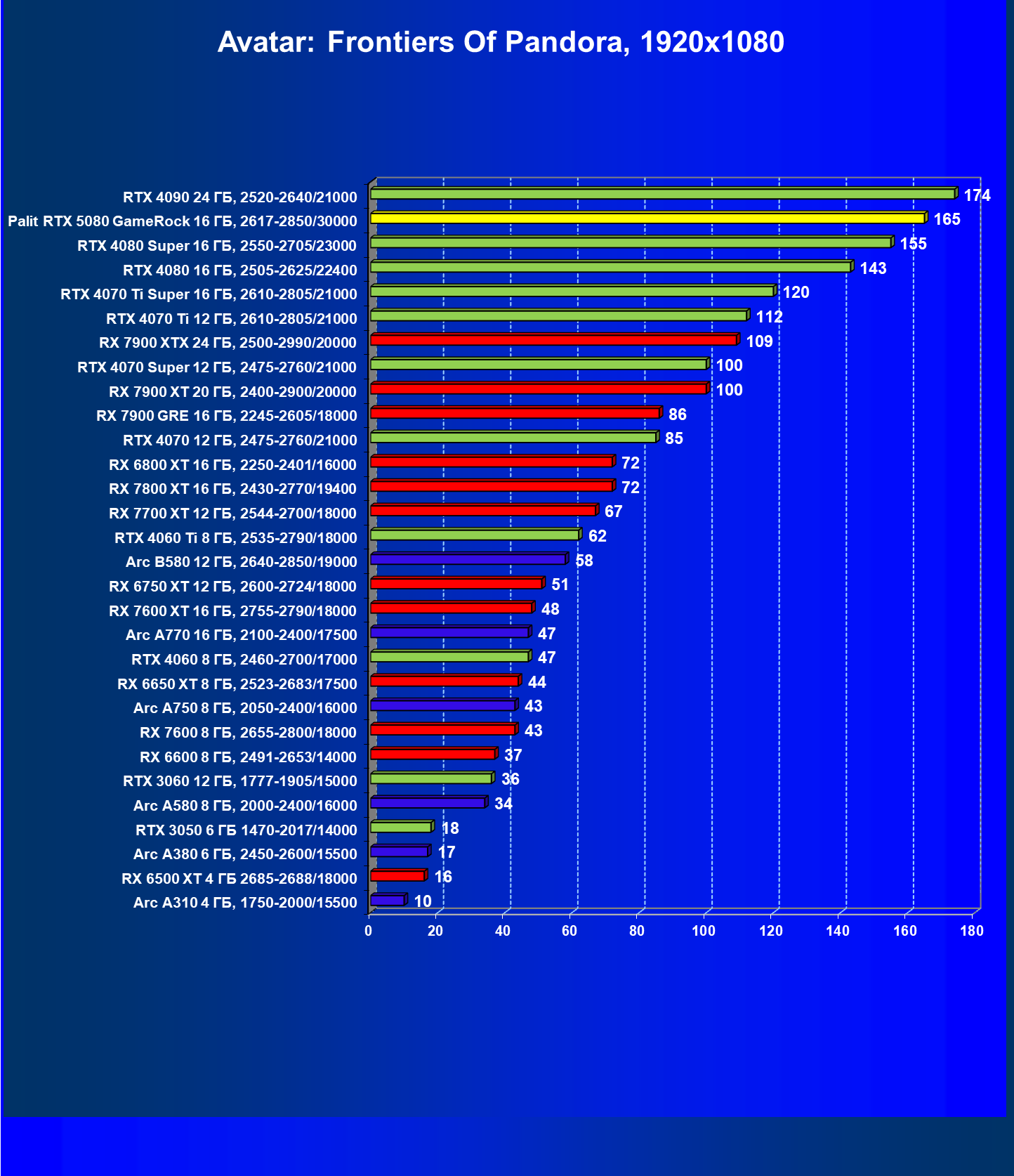
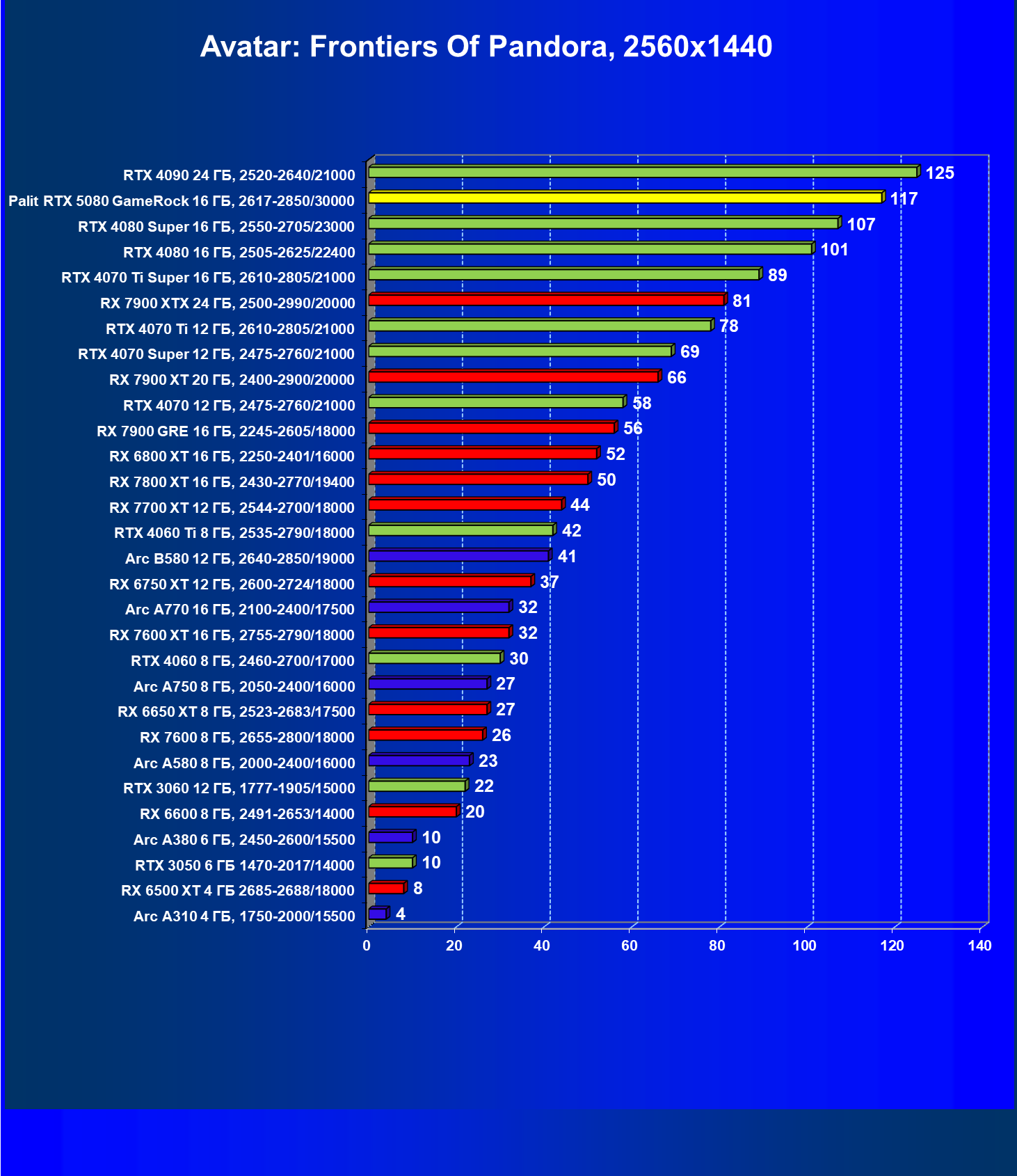
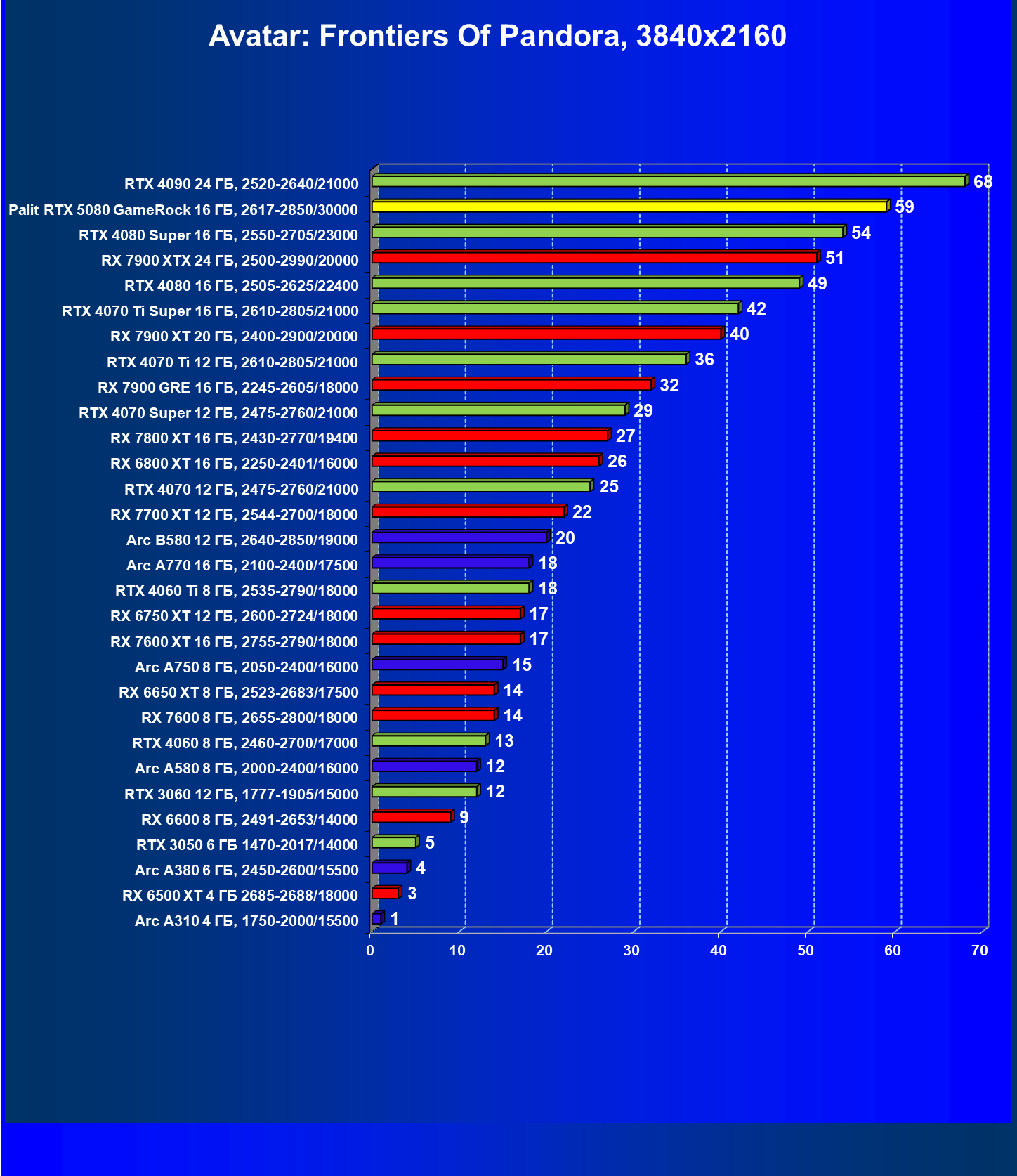
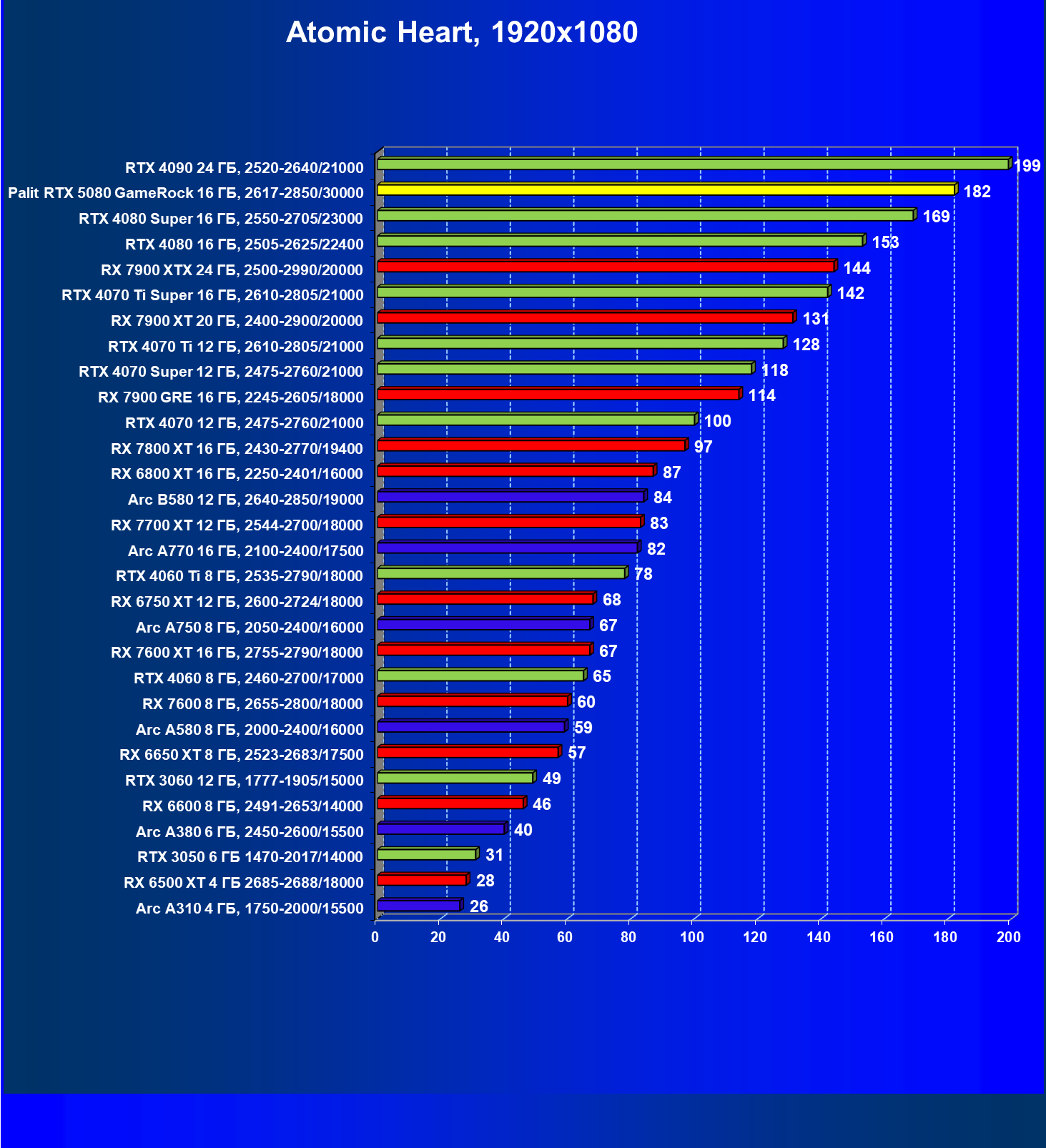
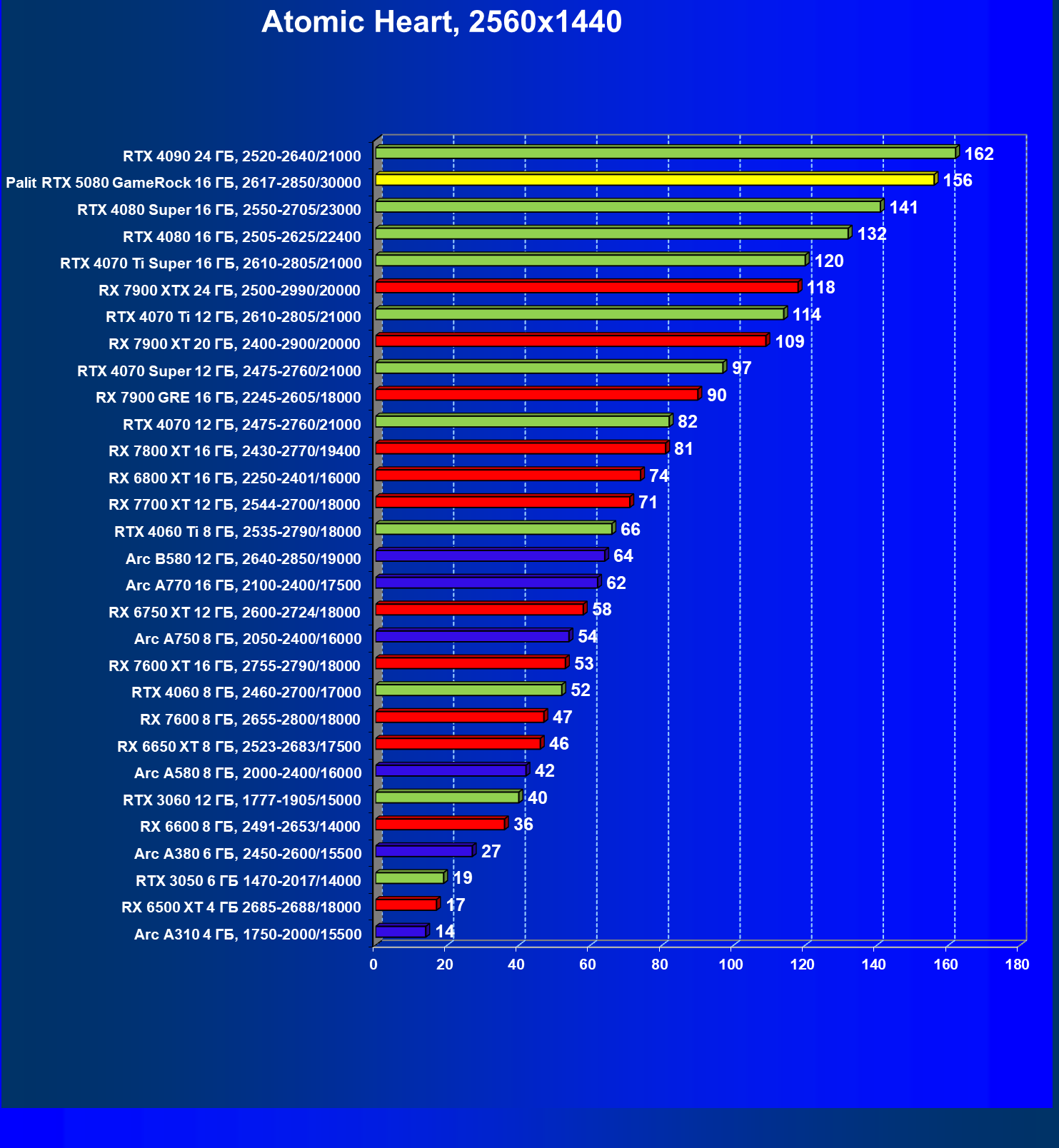
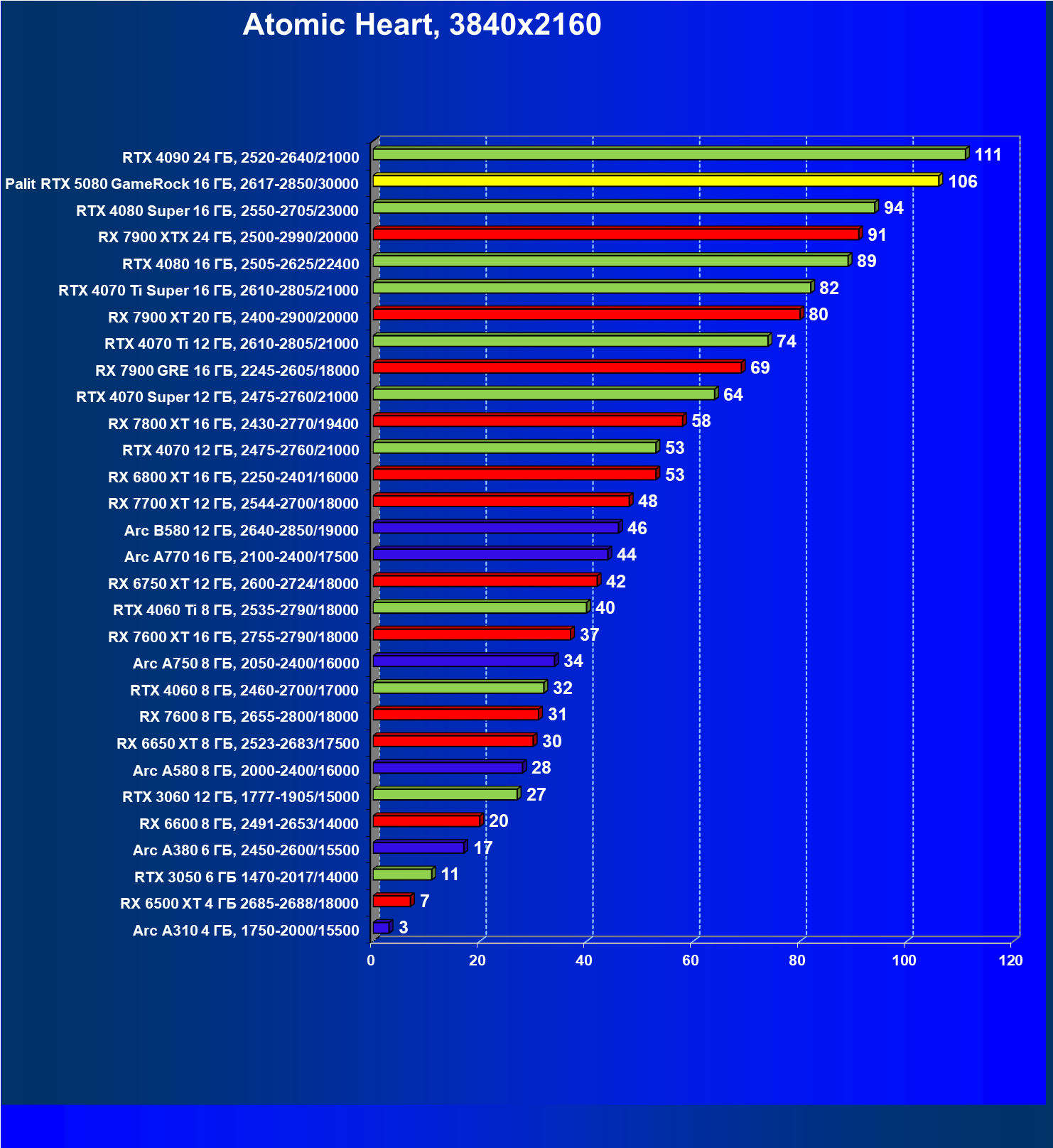
Результаты тестов со включенной аппаратной трассировкой лучей и/или DLSS/FSR/XeSS в разрешениях 1920×1080, 2560×1440 и 3840×2160
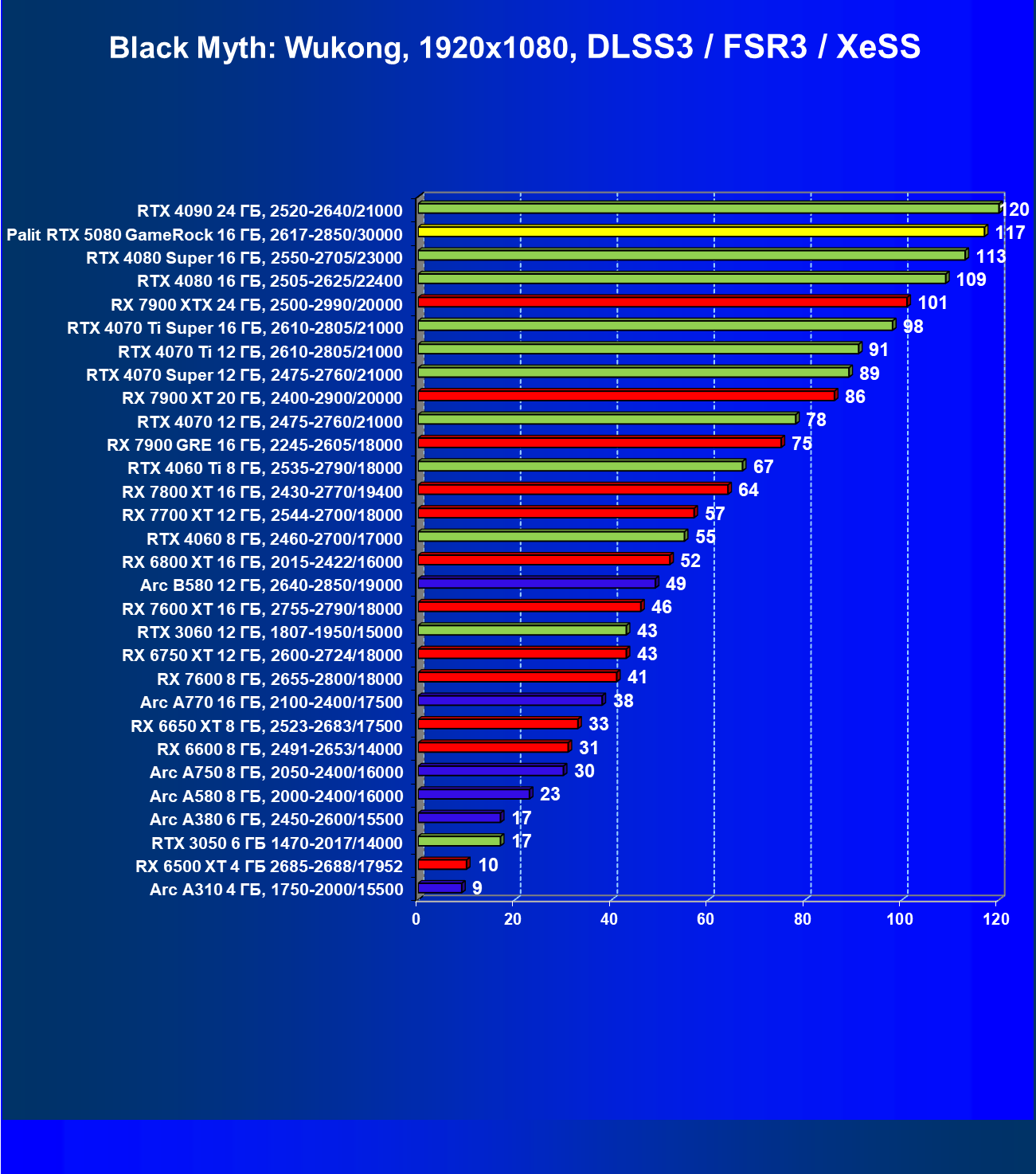
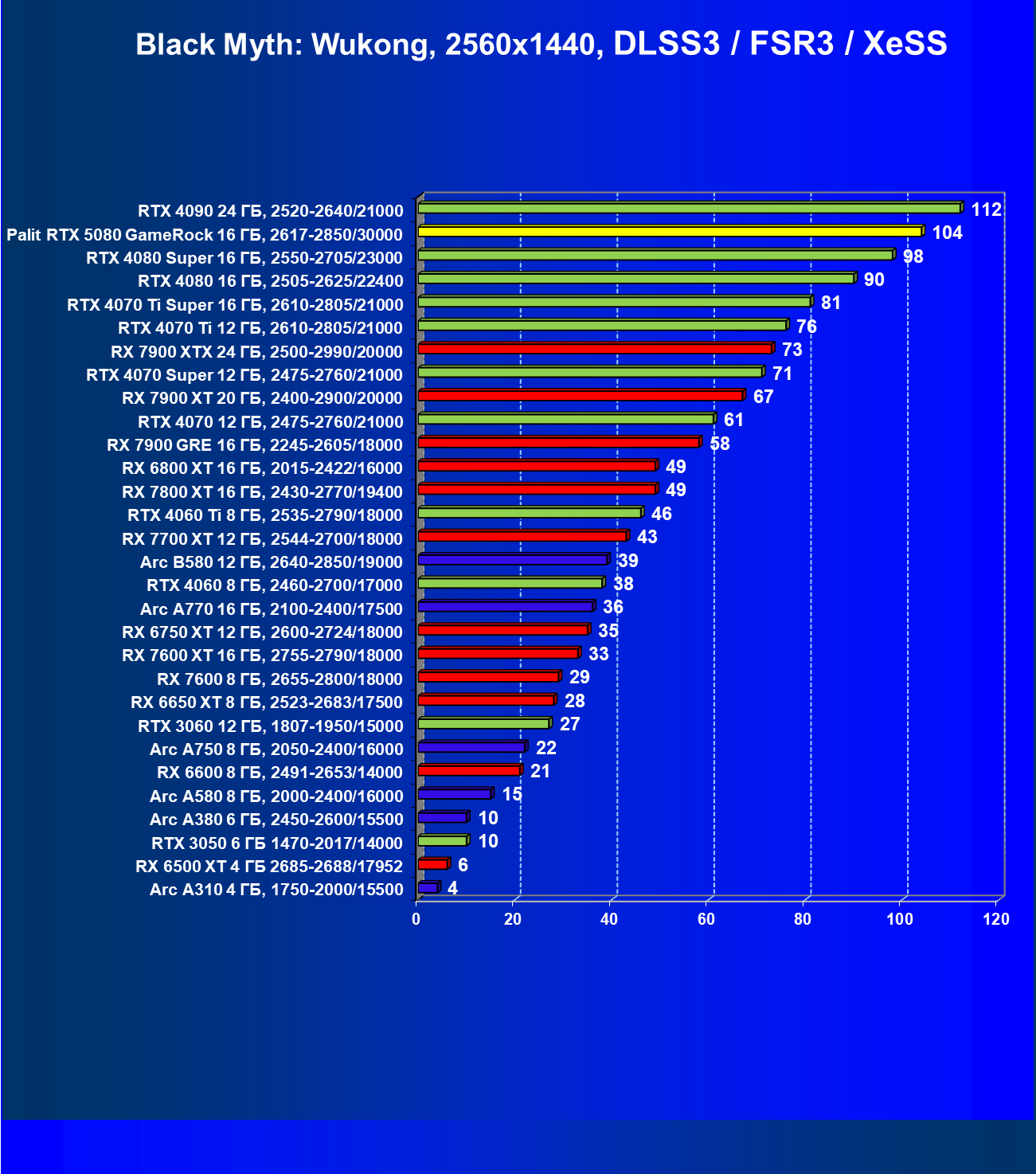
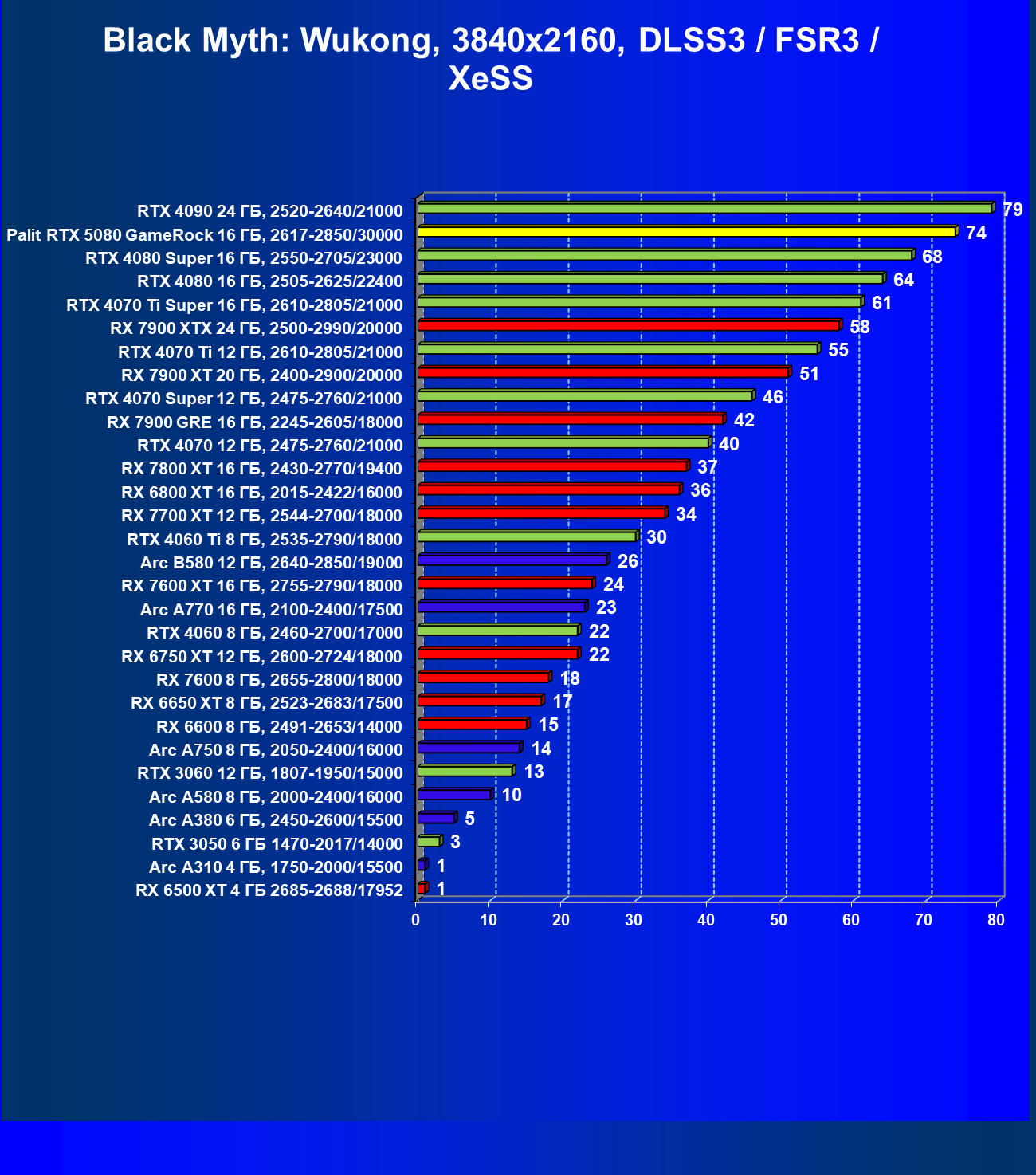
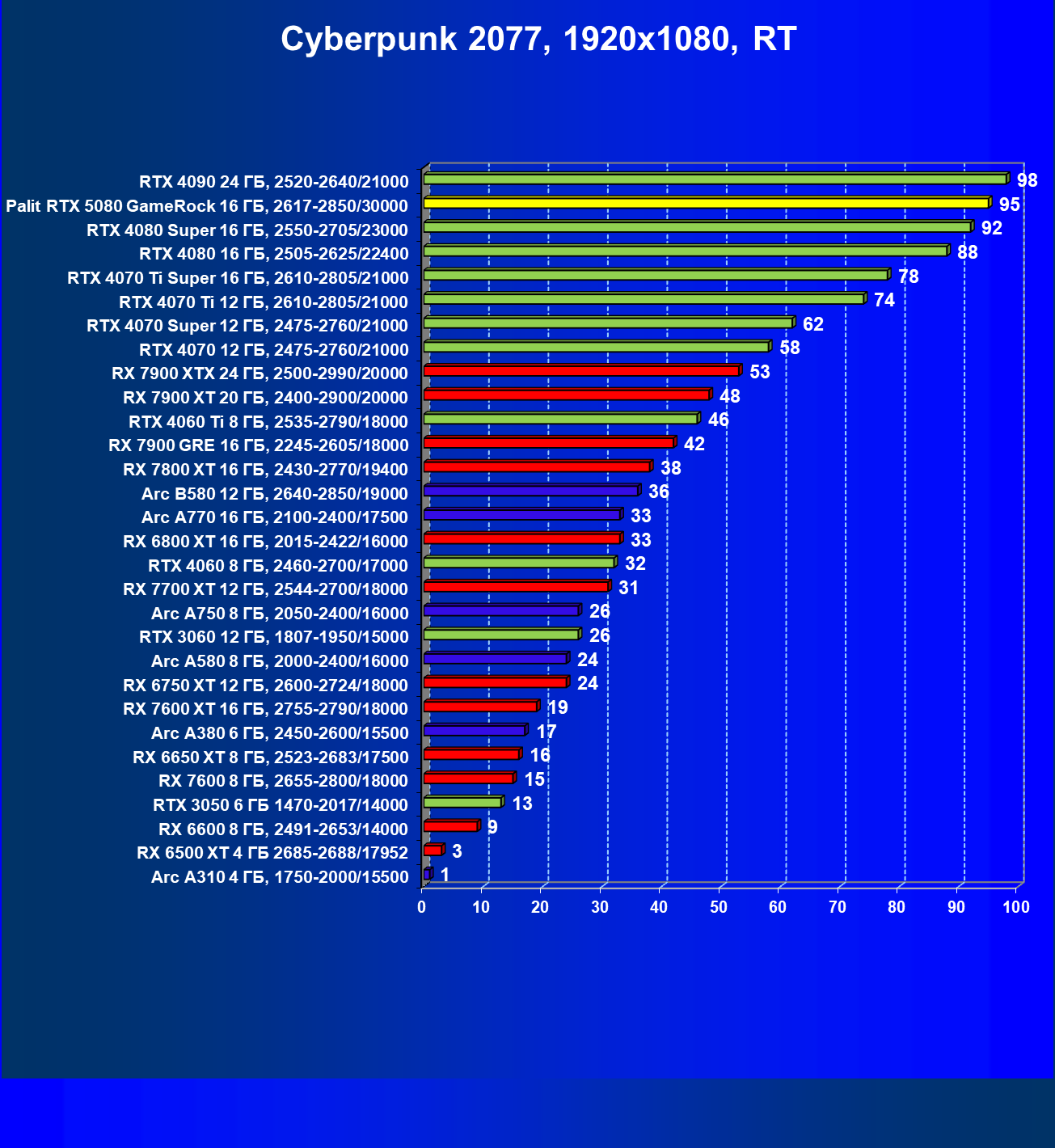
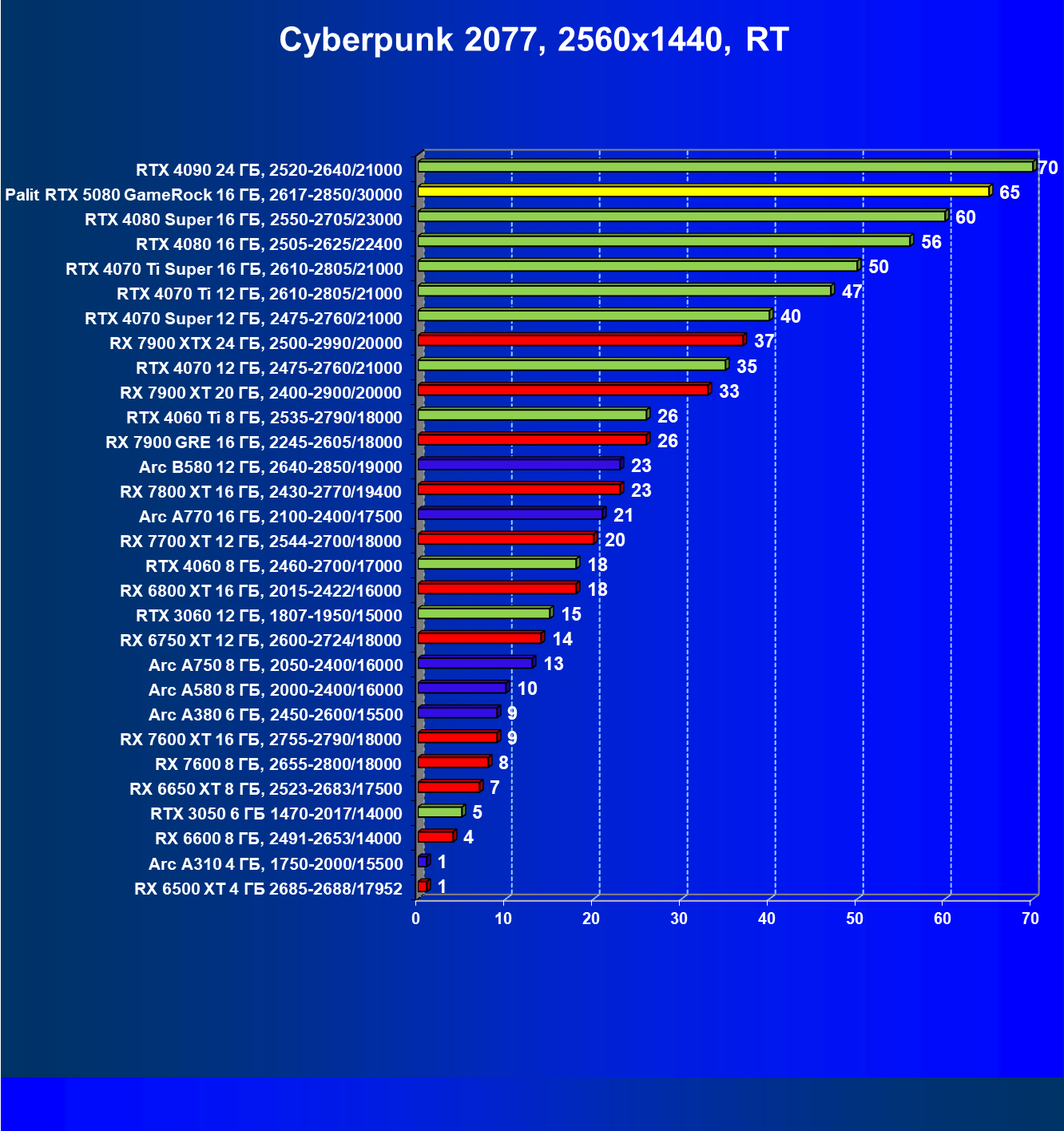
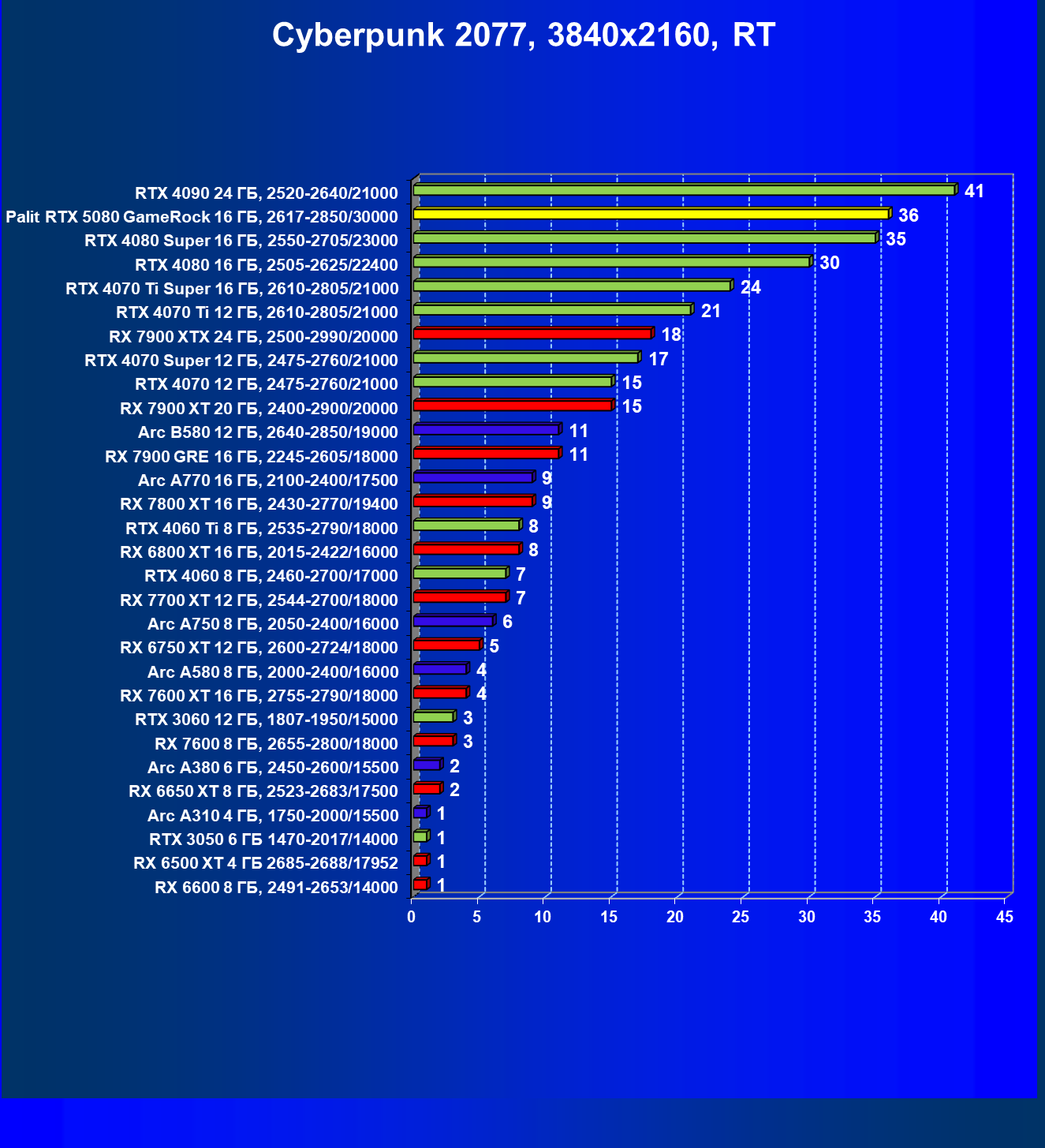
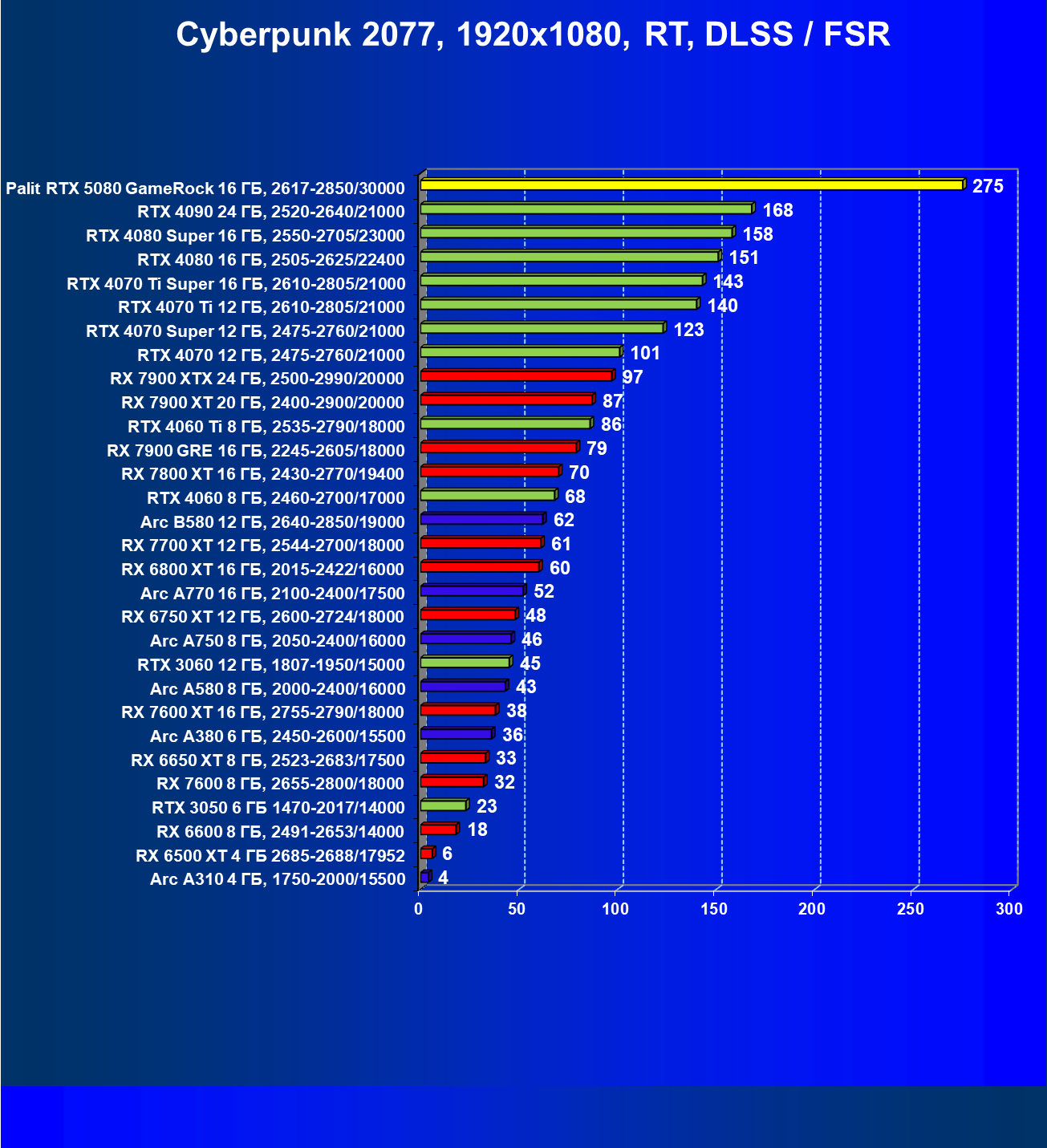
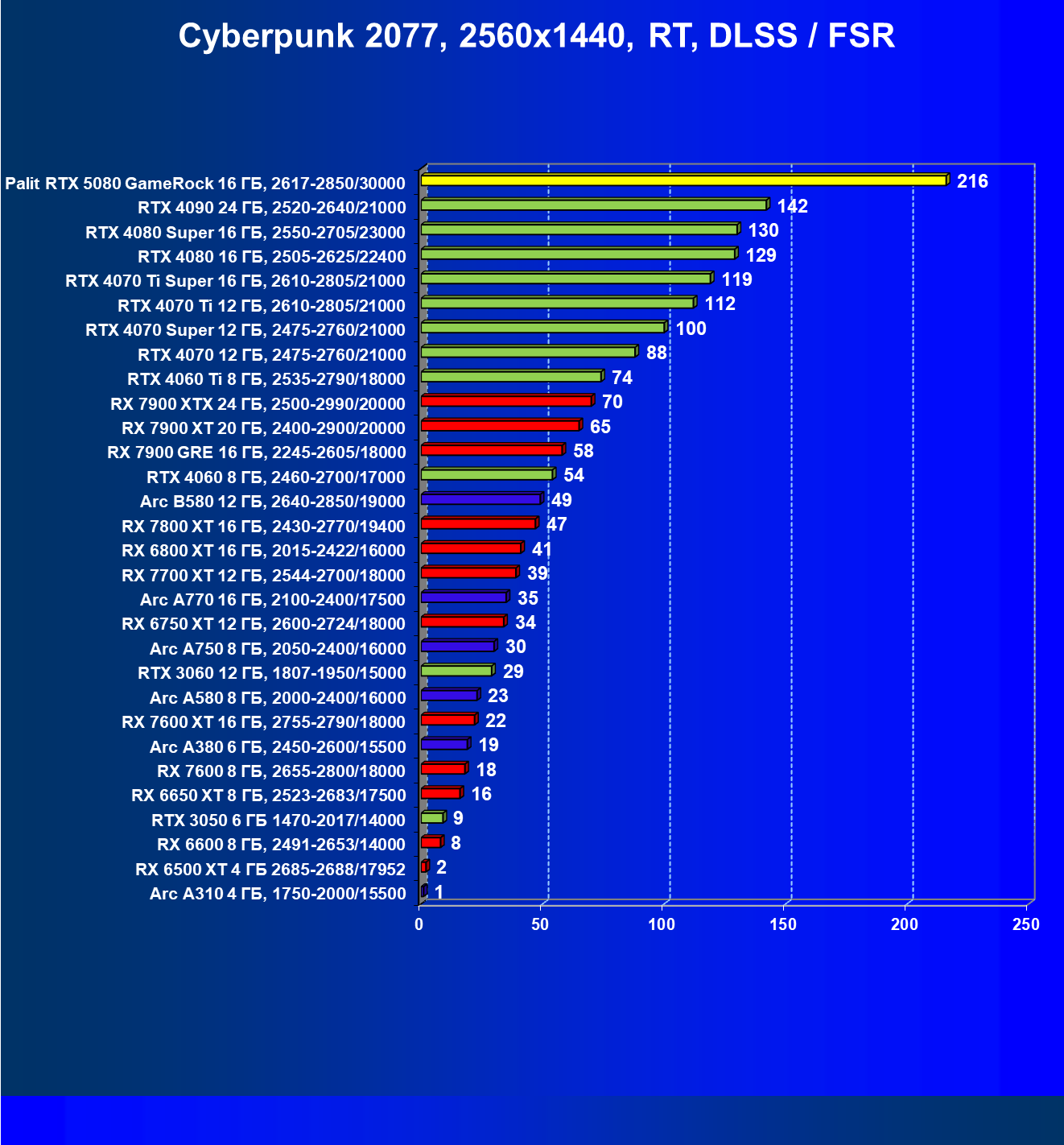
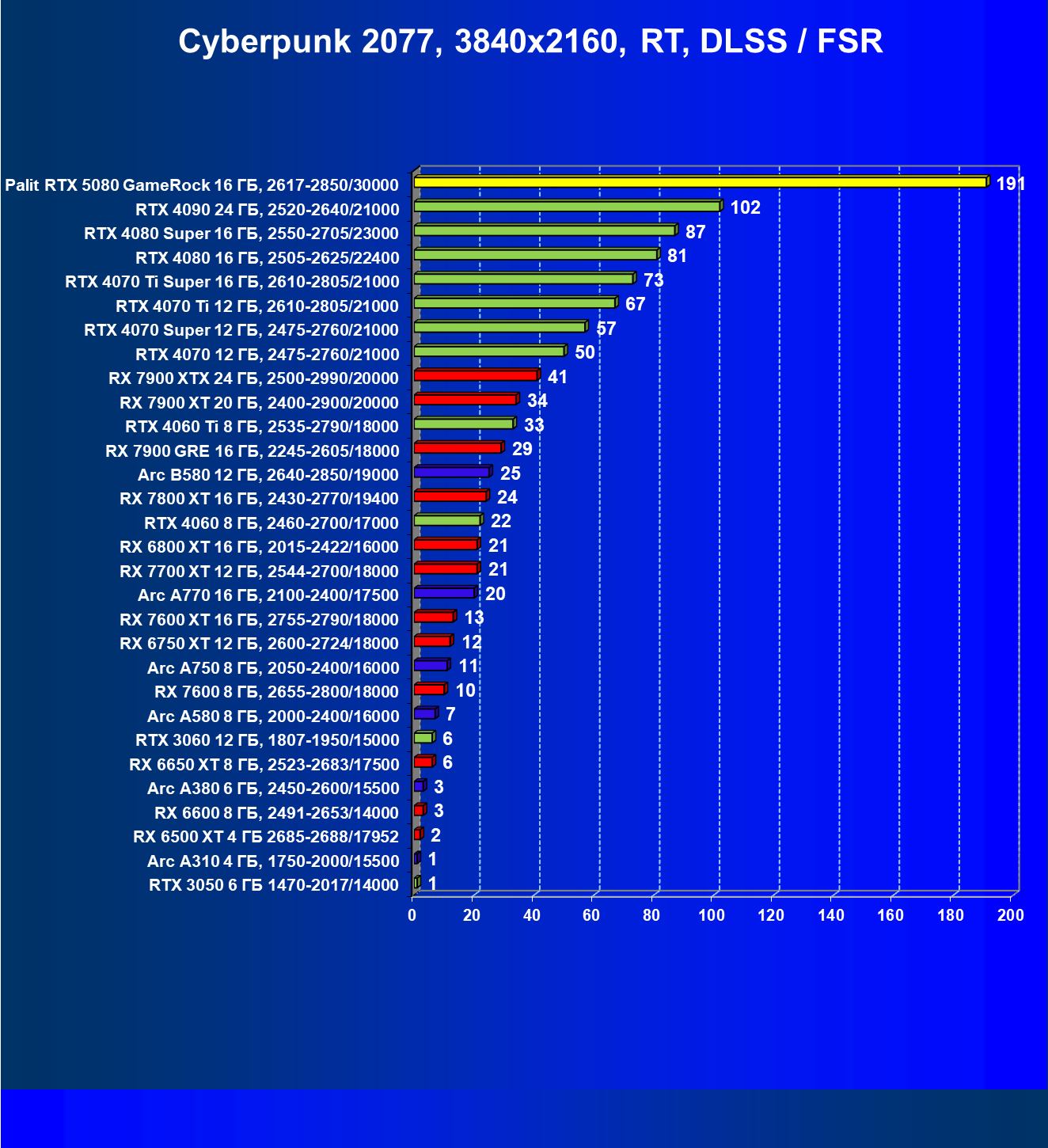
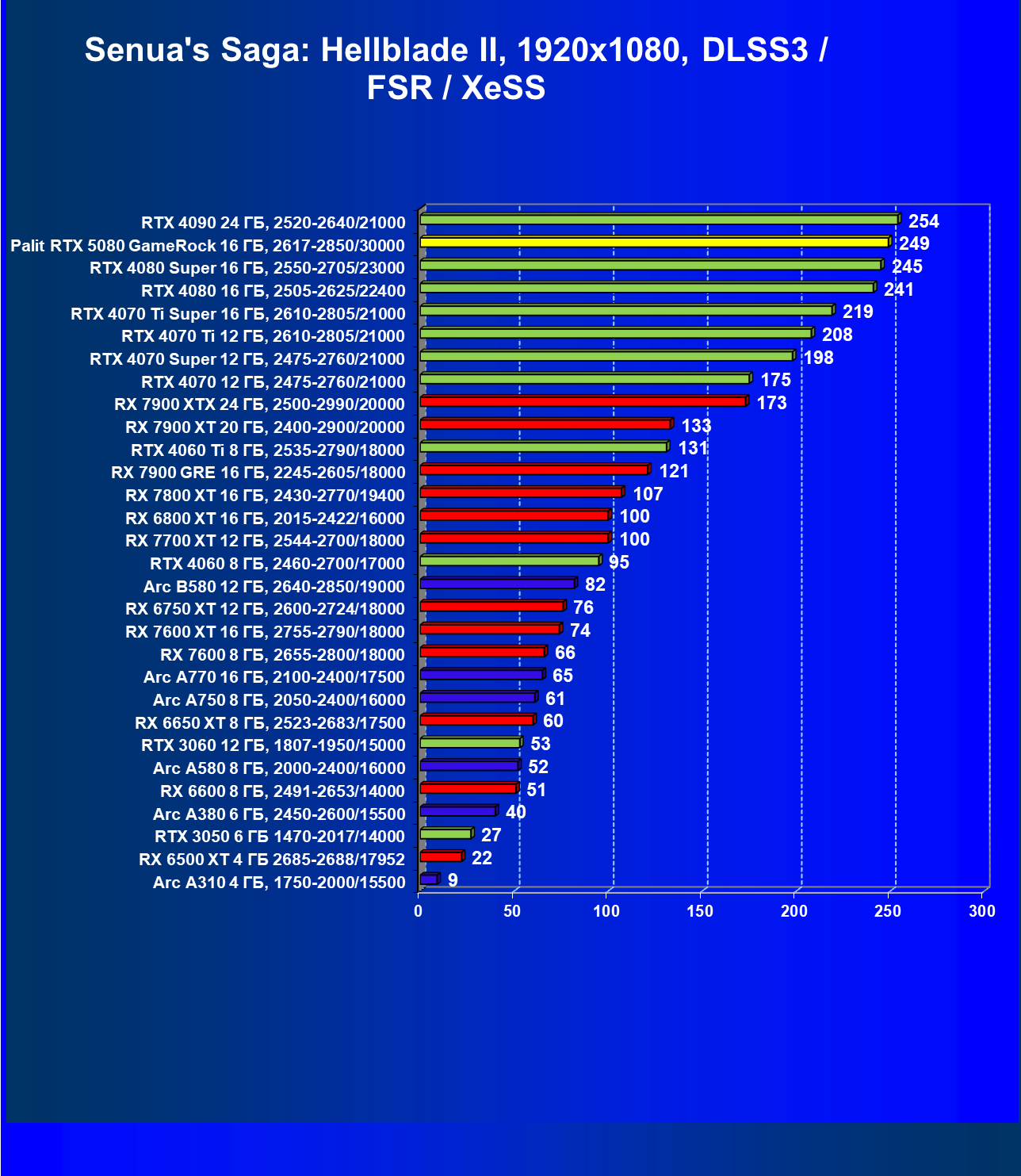
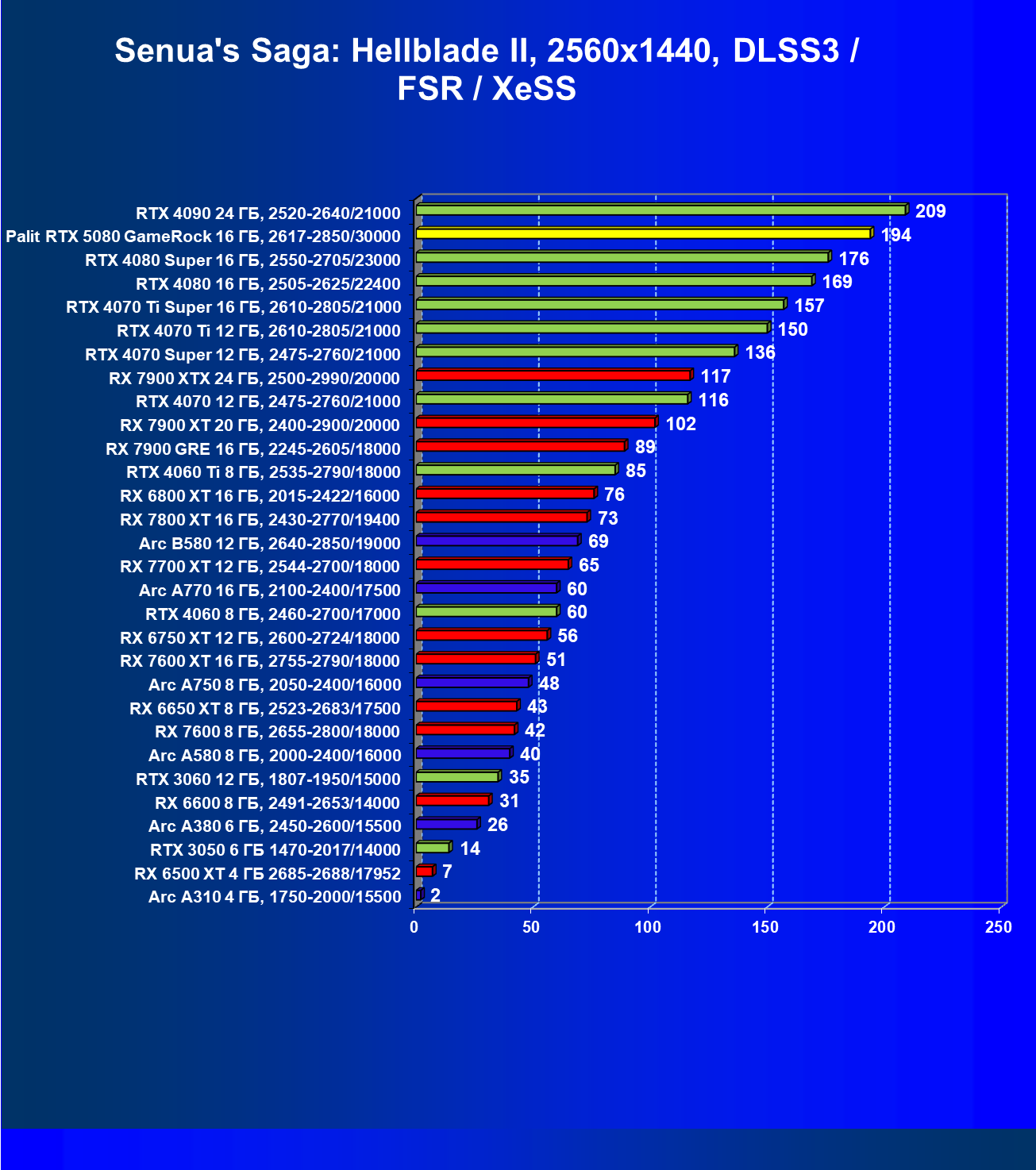
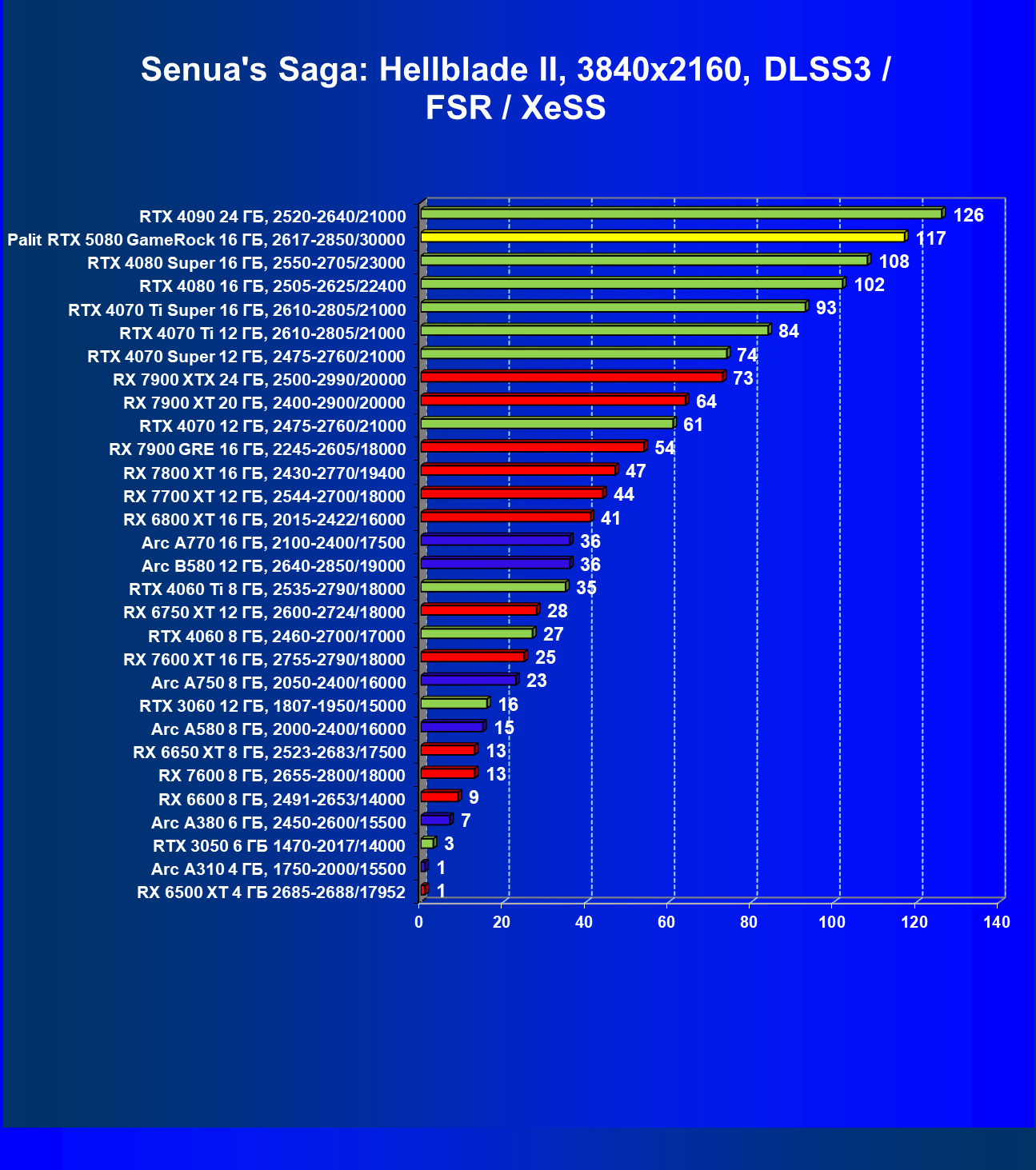
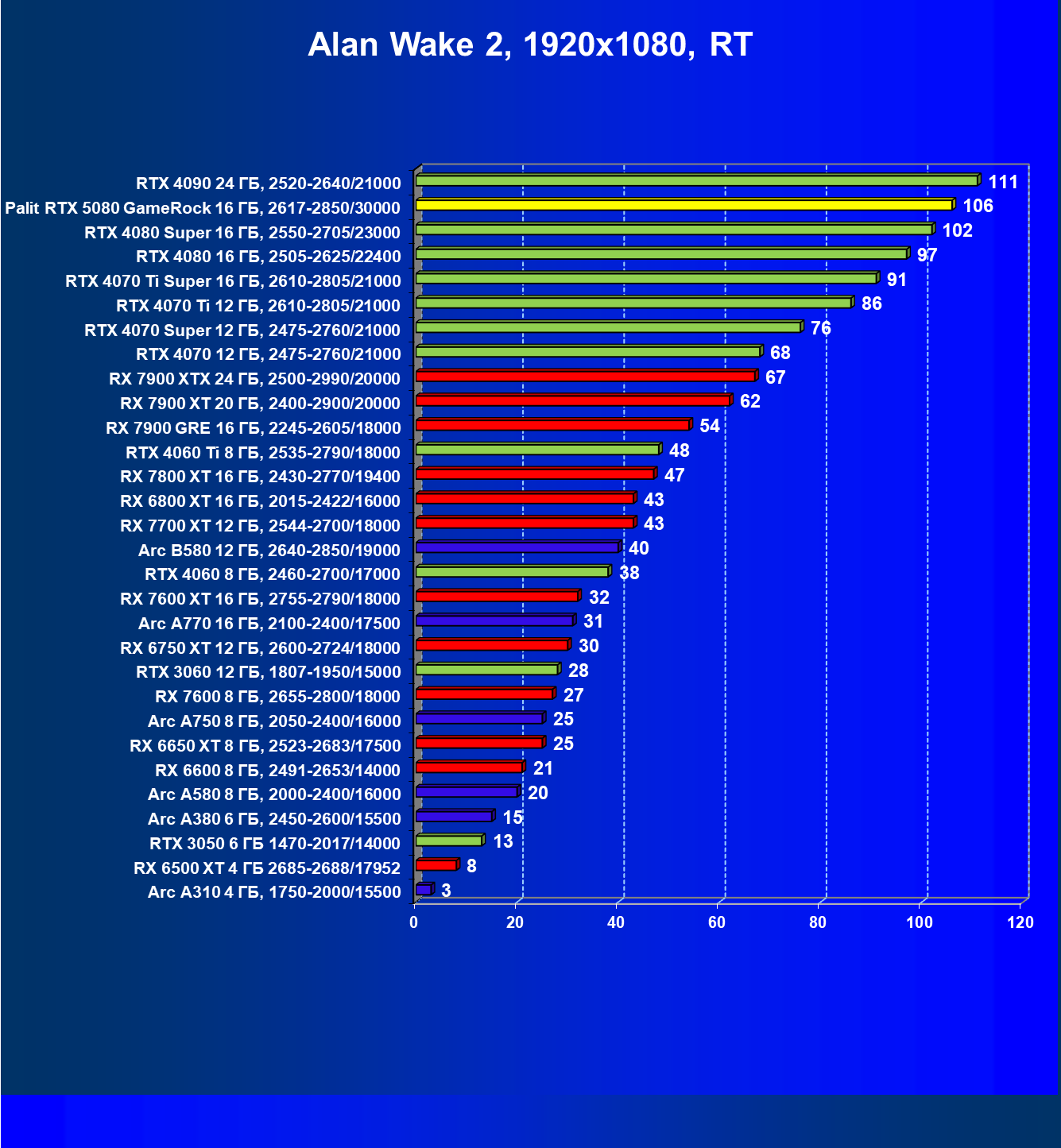
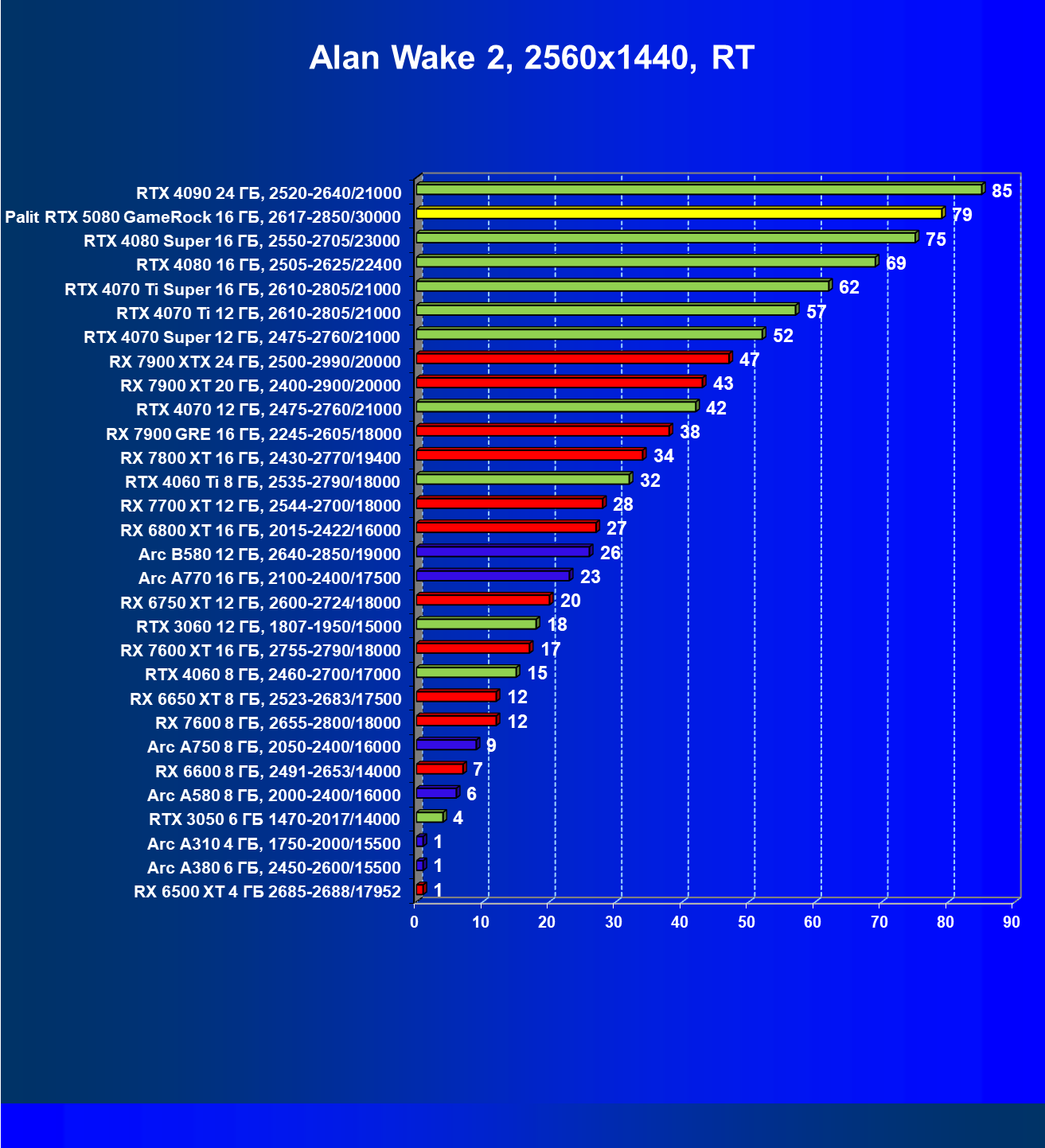
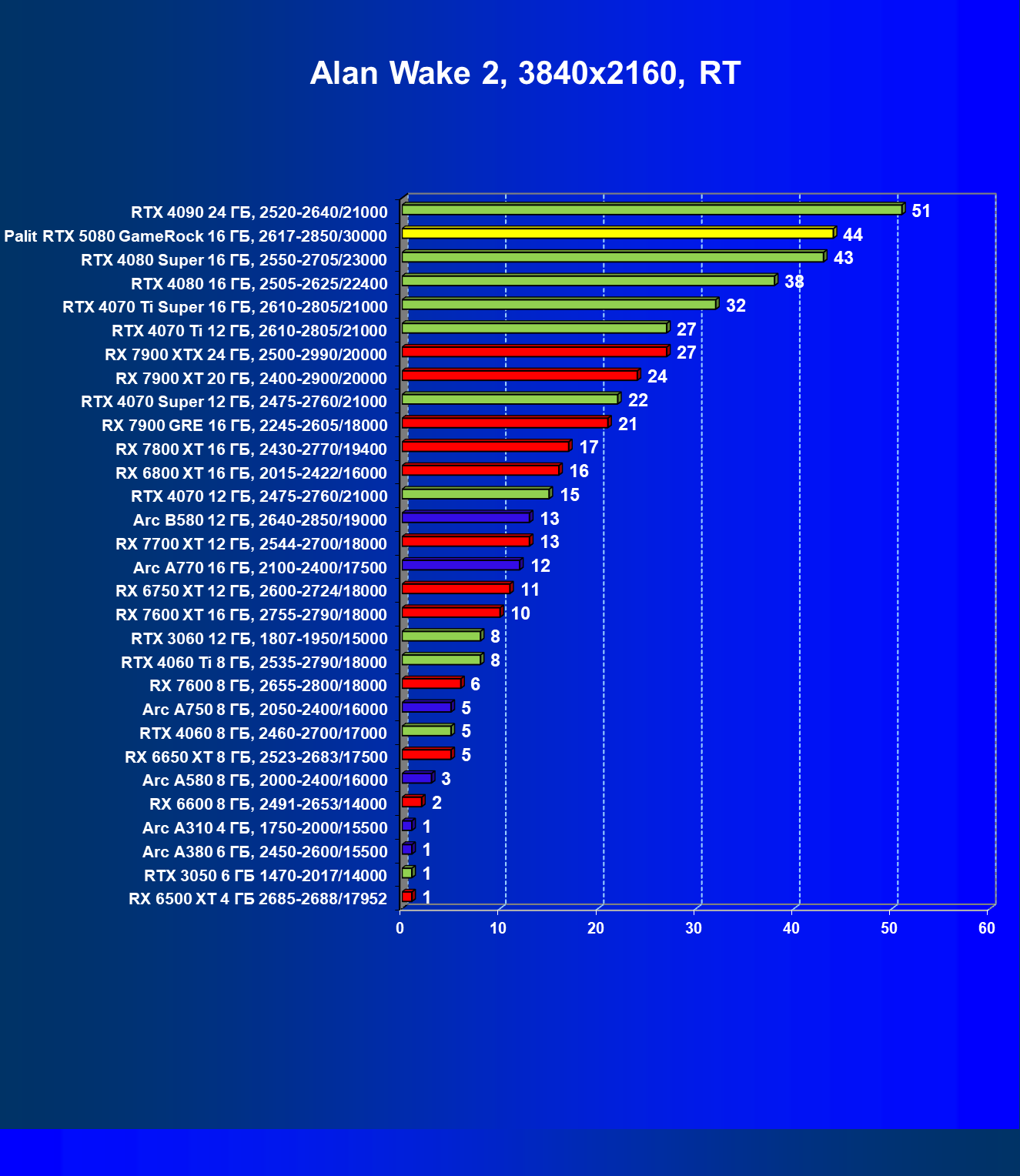
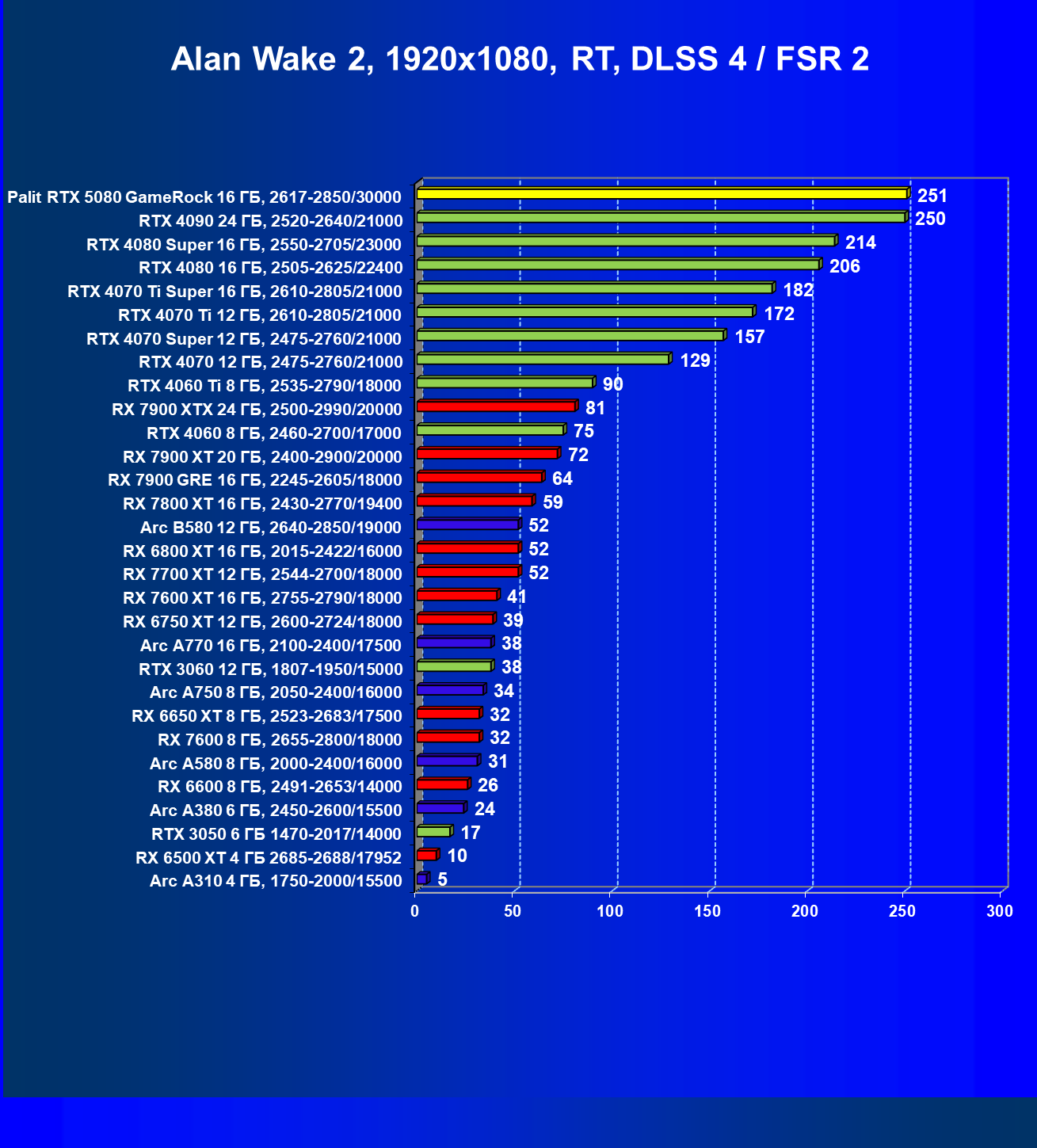
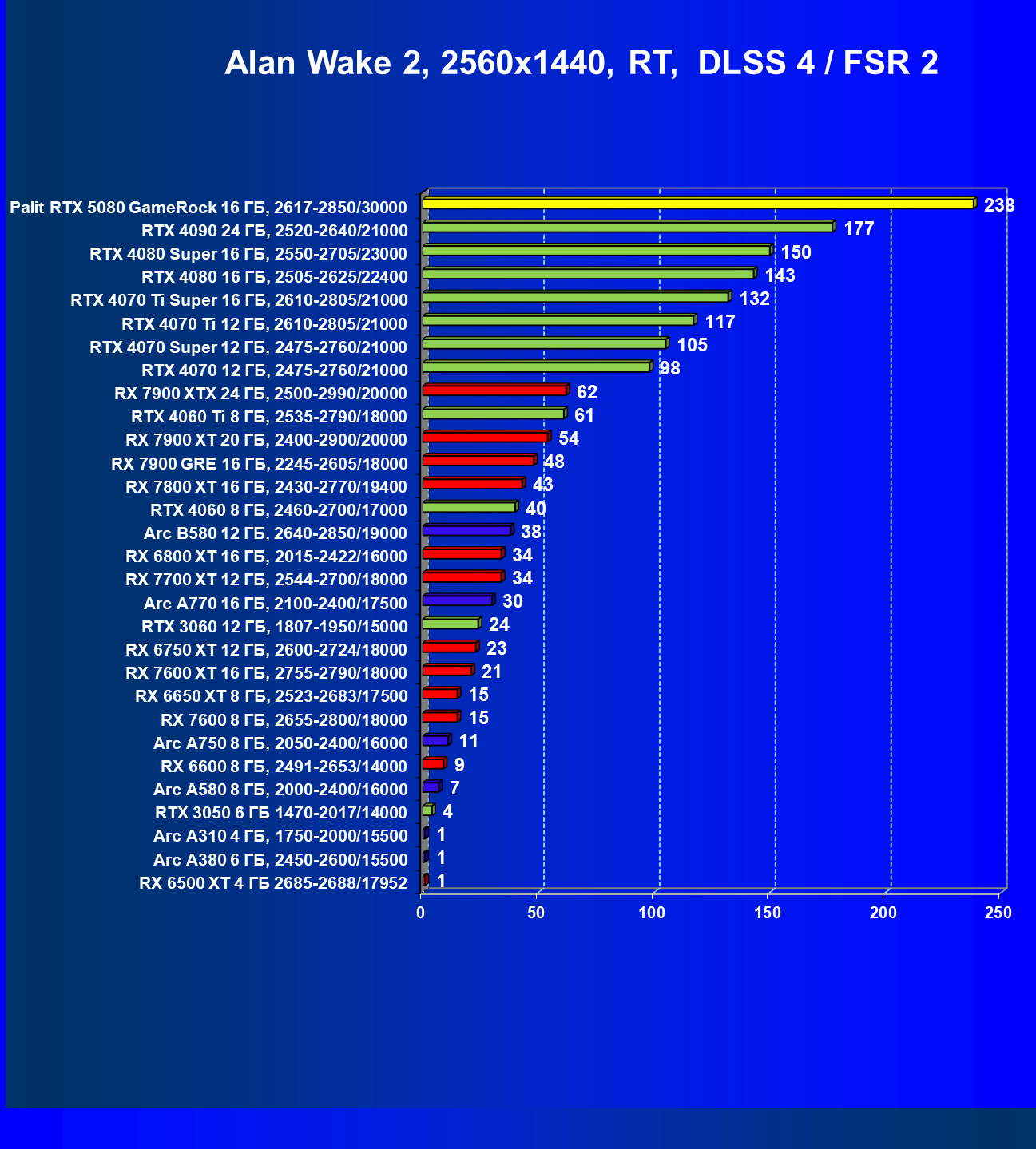
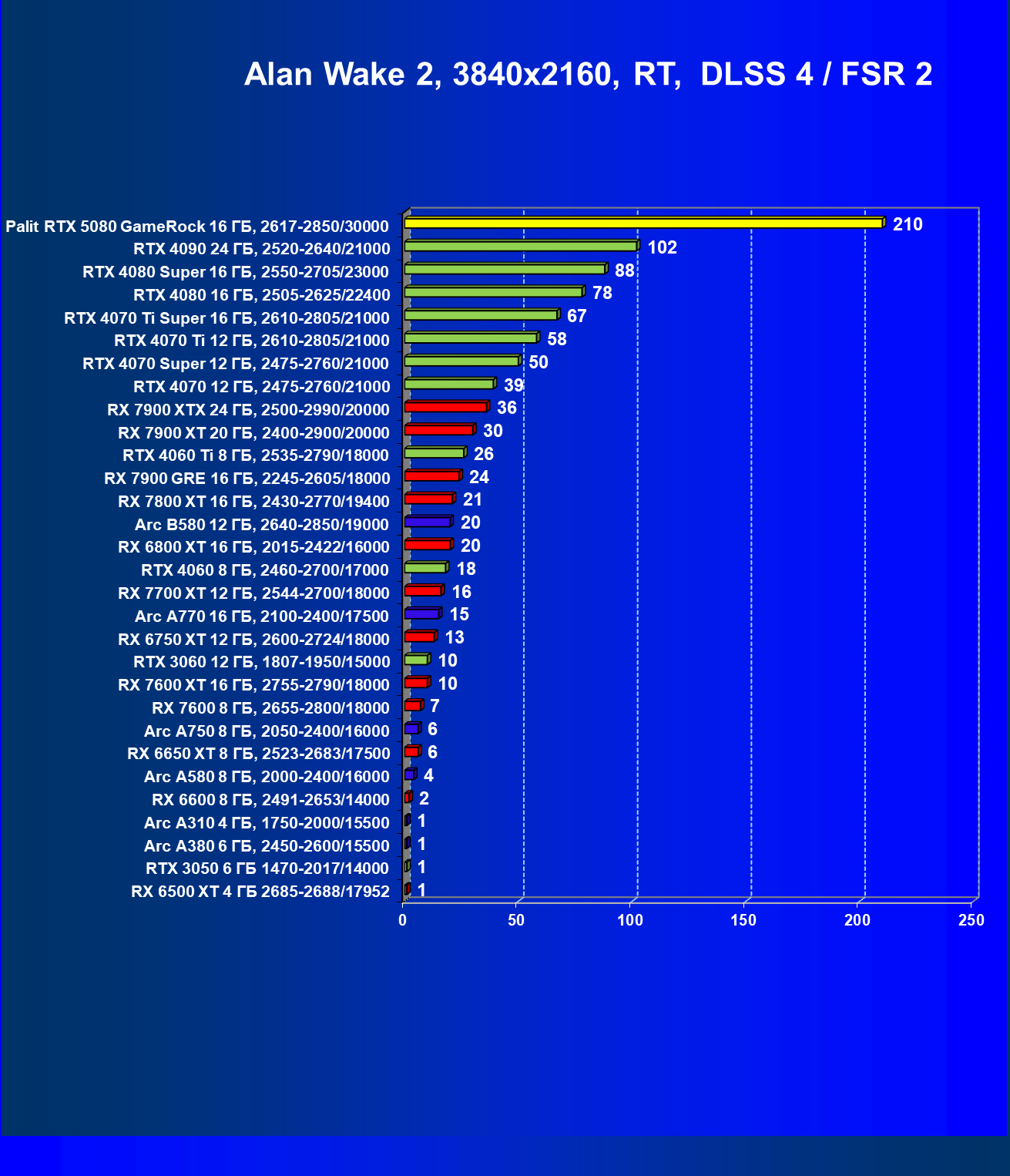
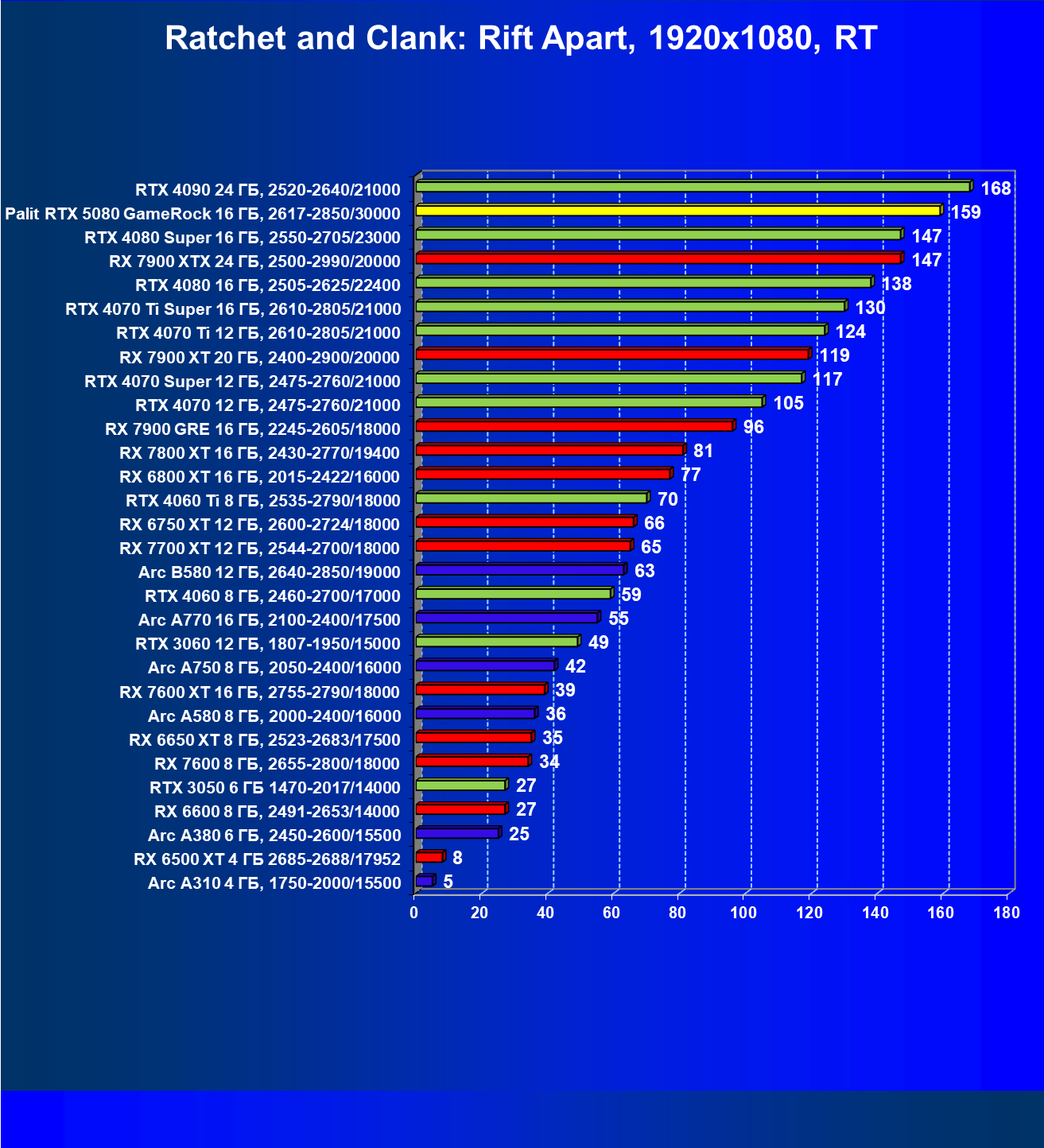
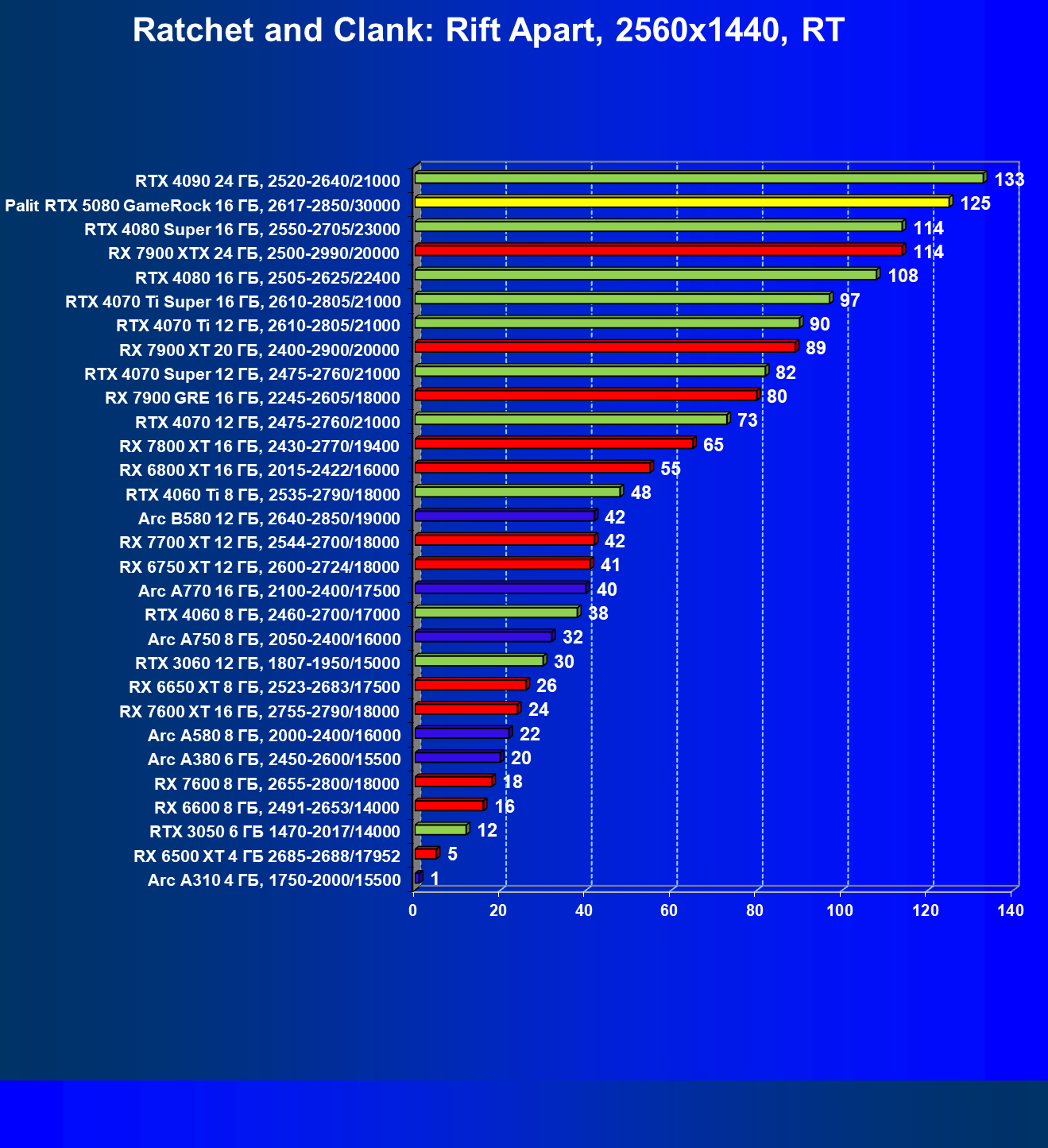
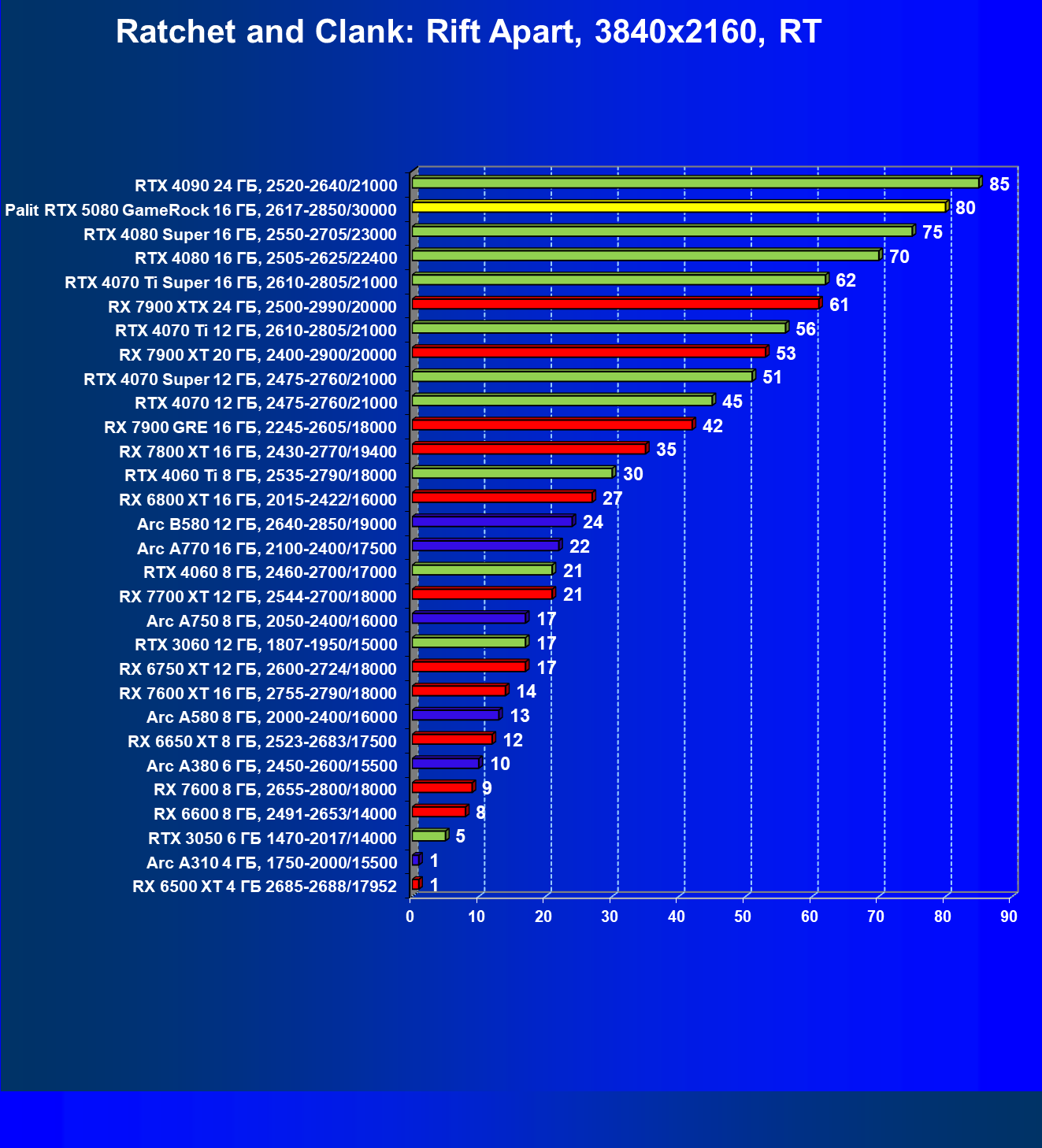
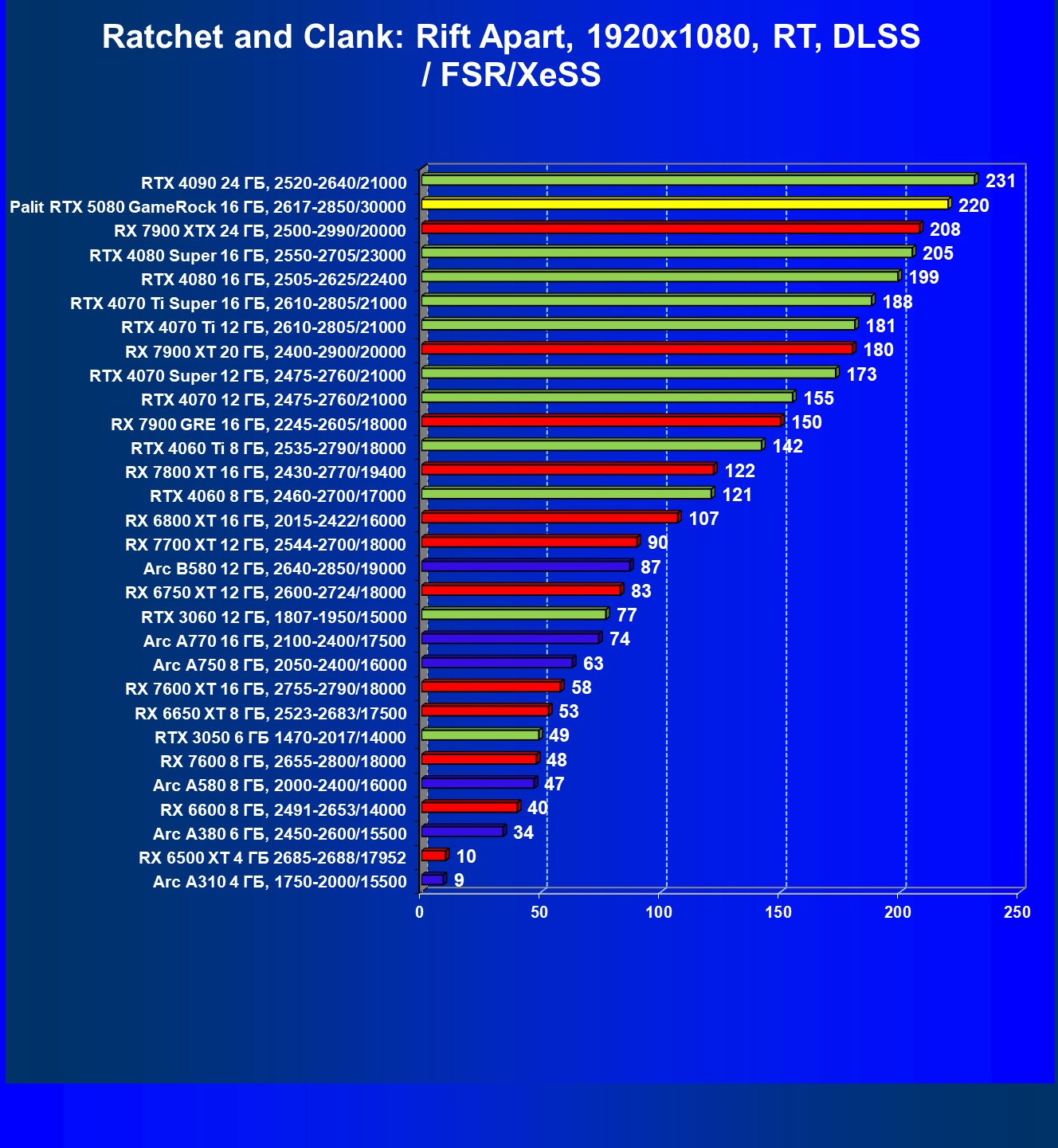
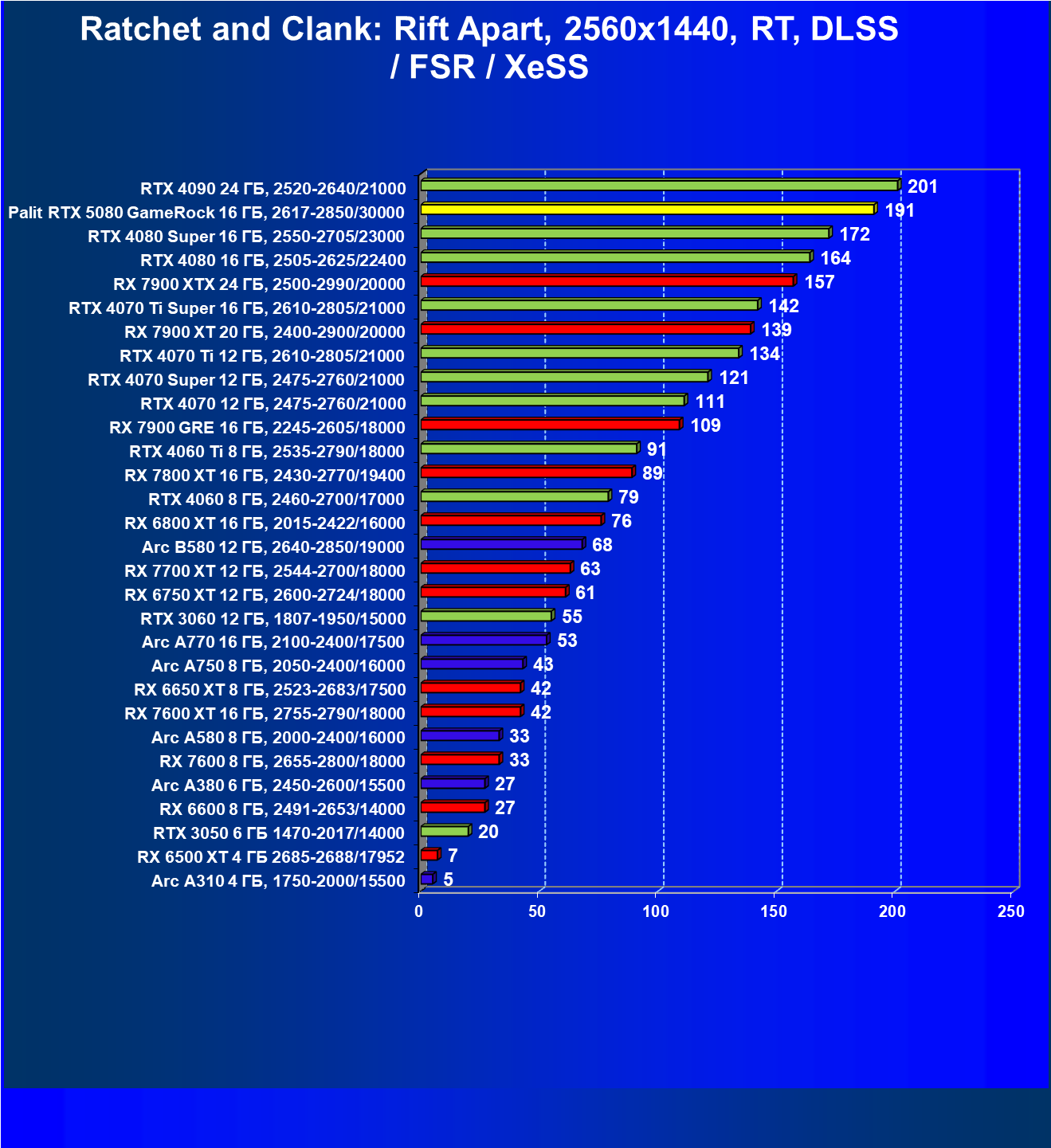
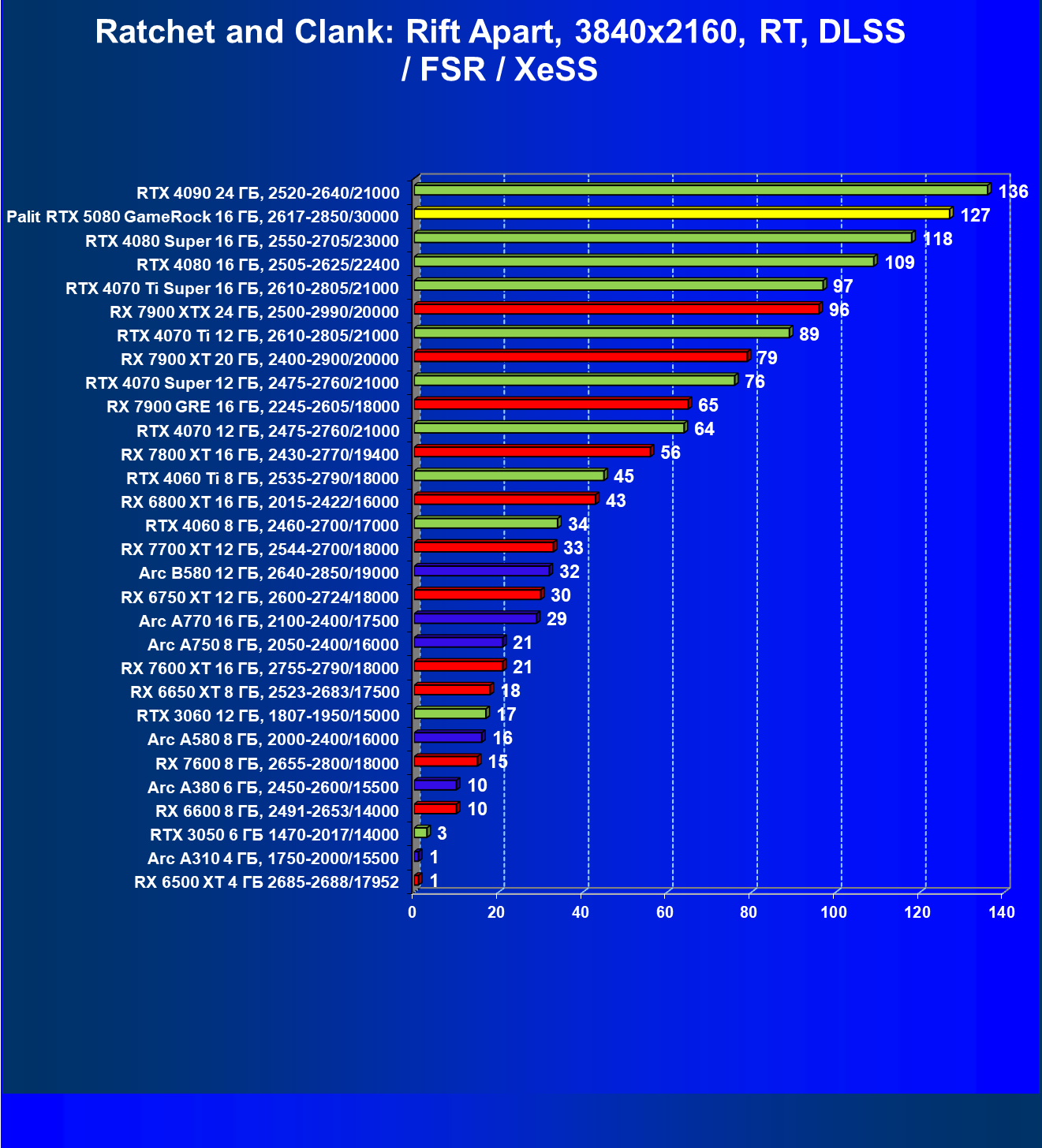

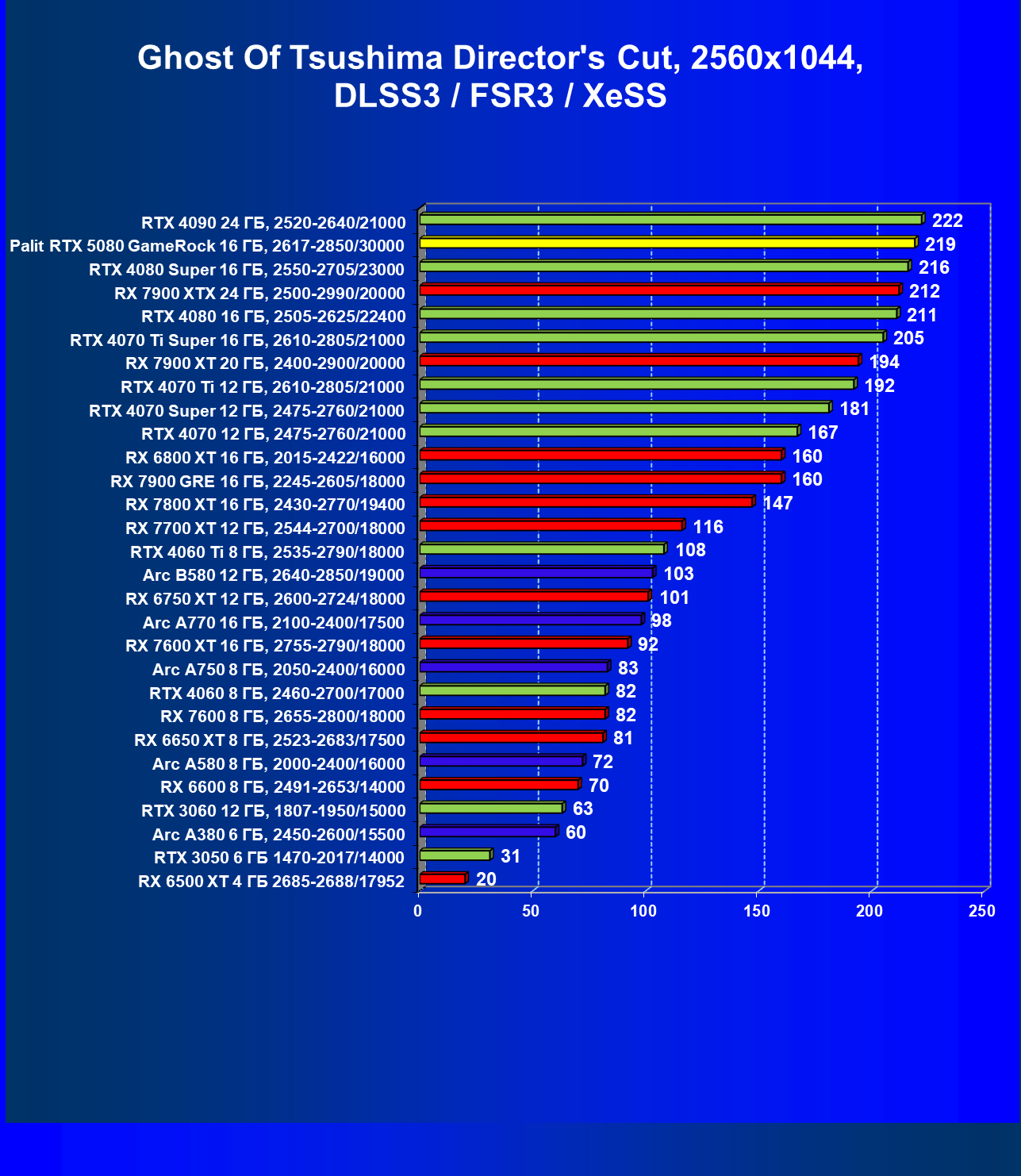
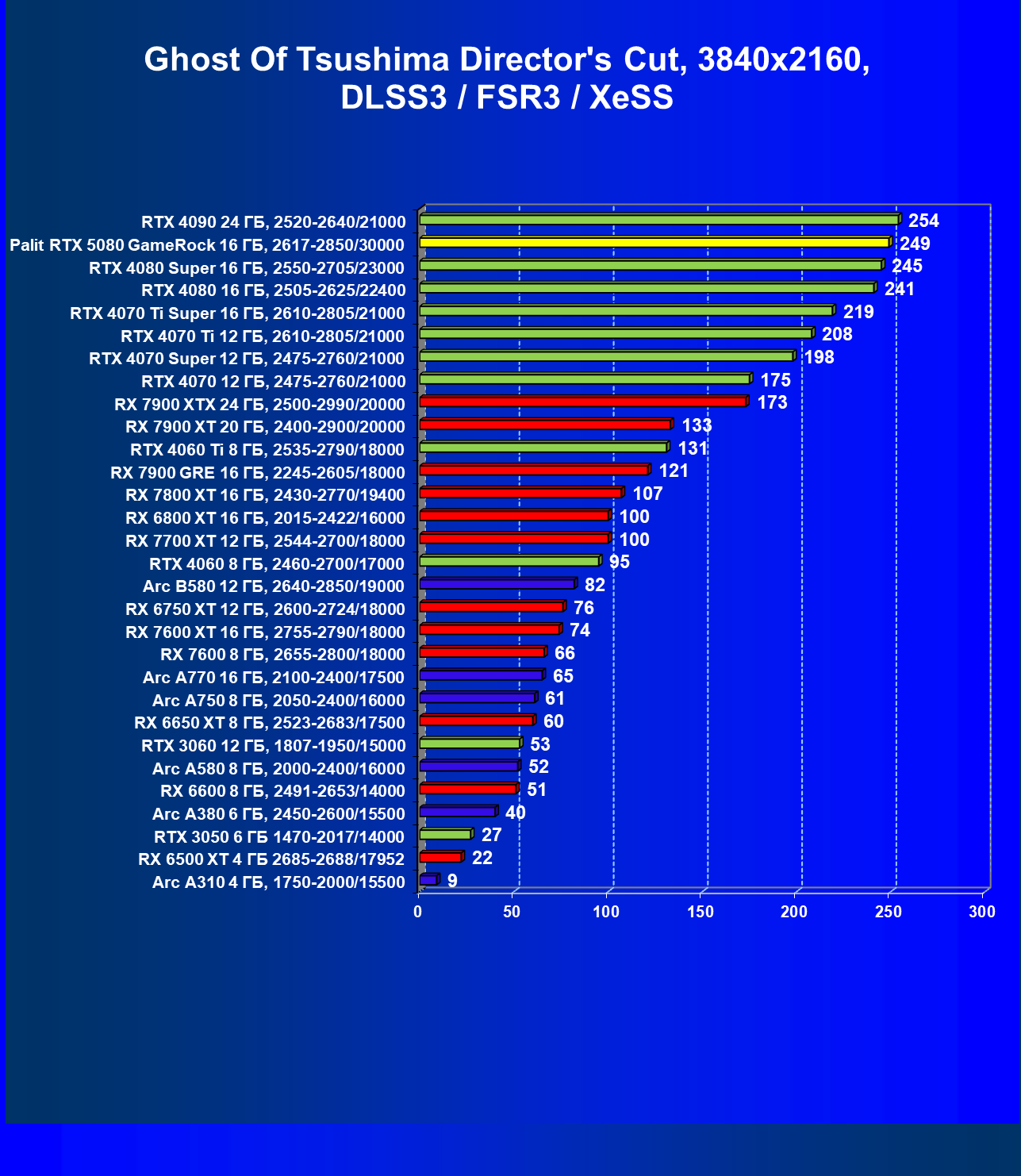
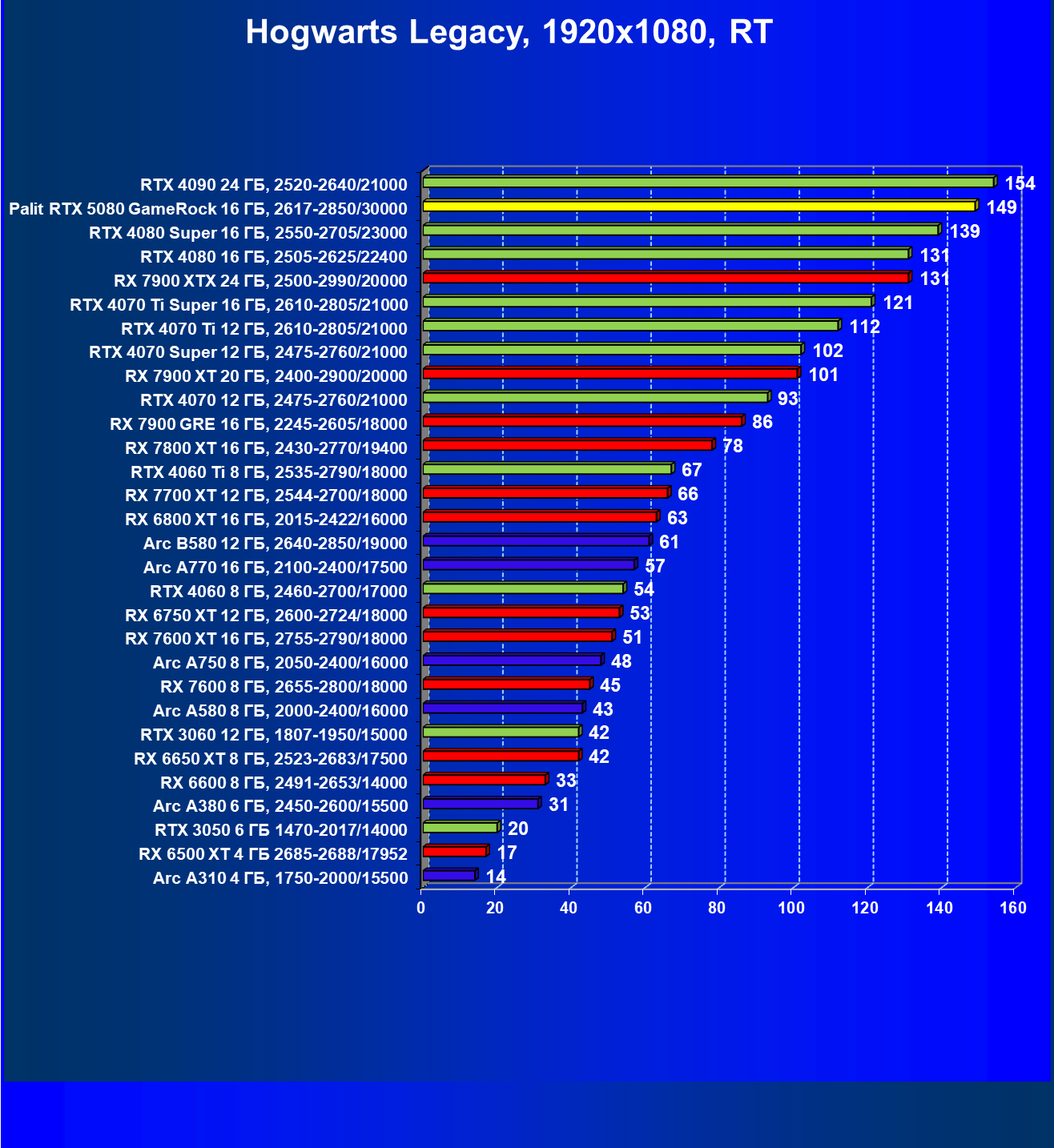
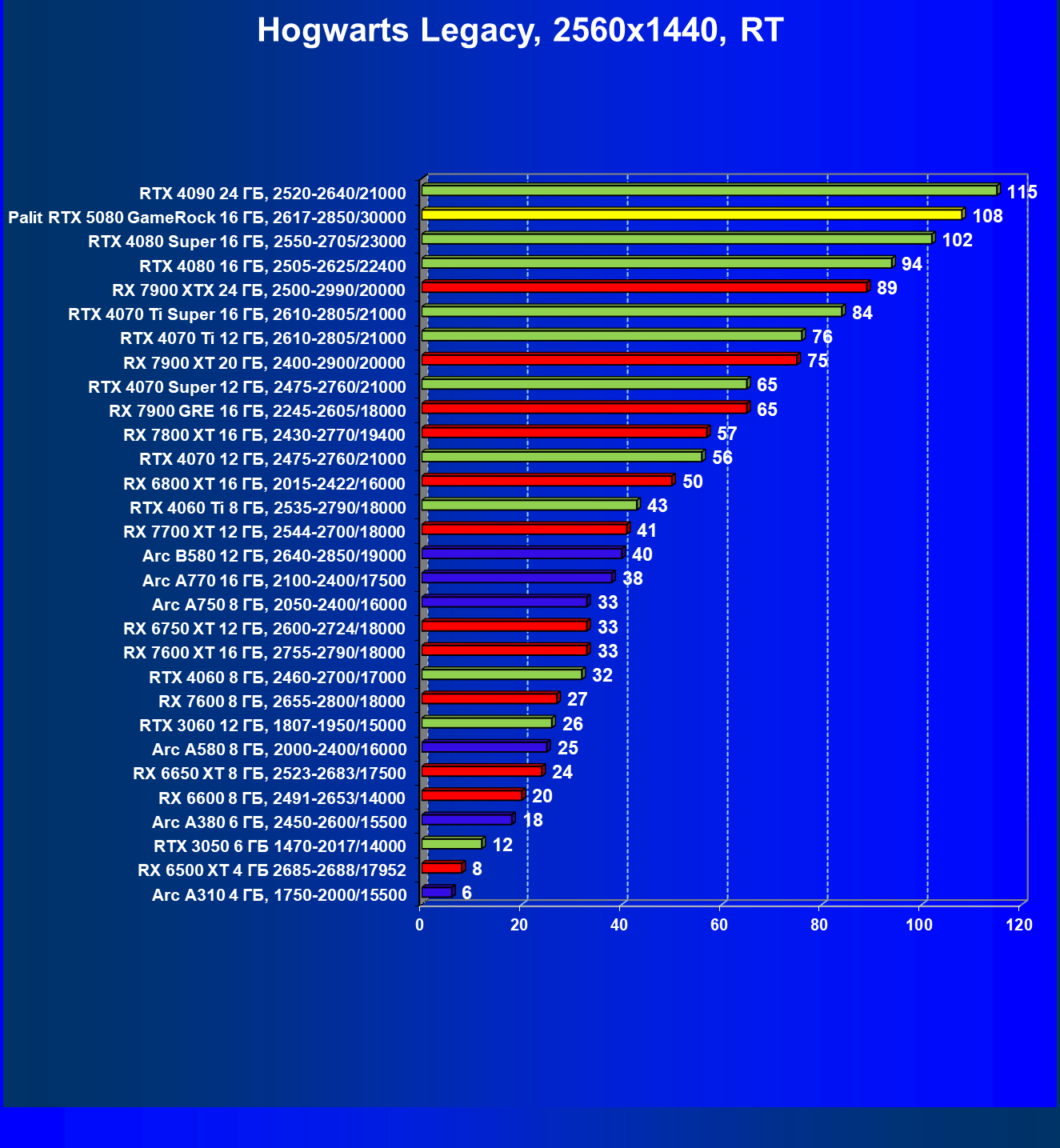
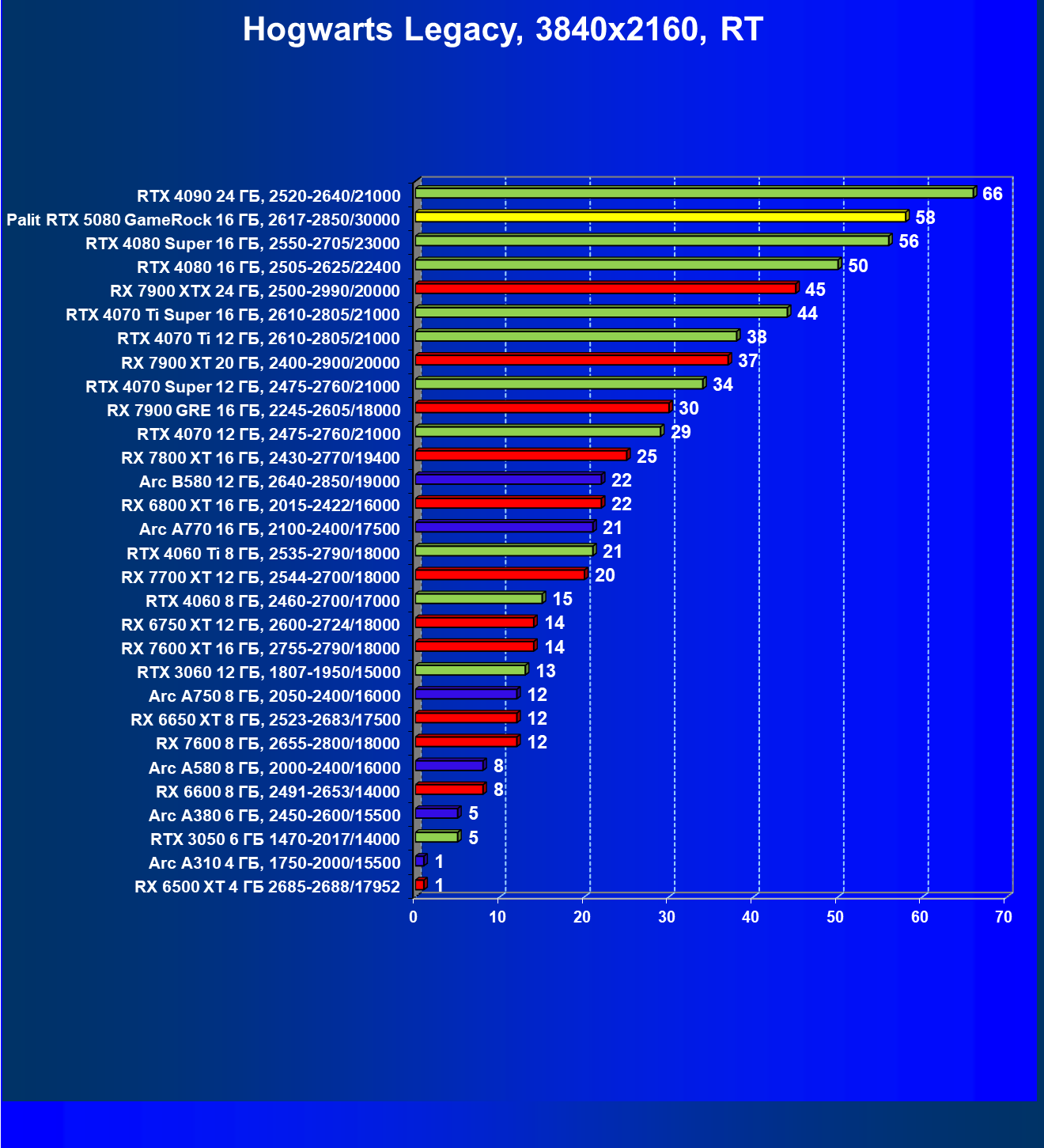
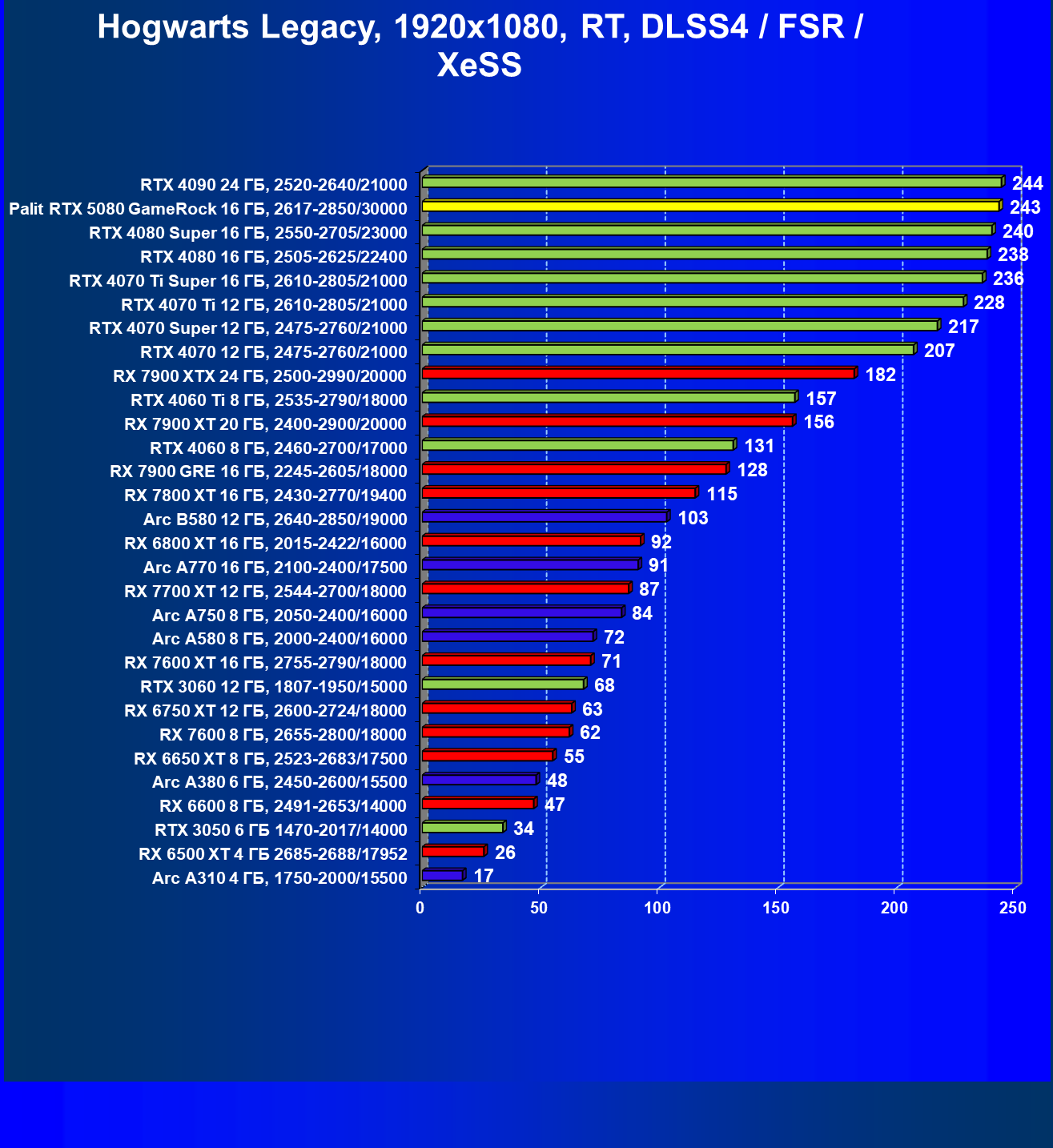
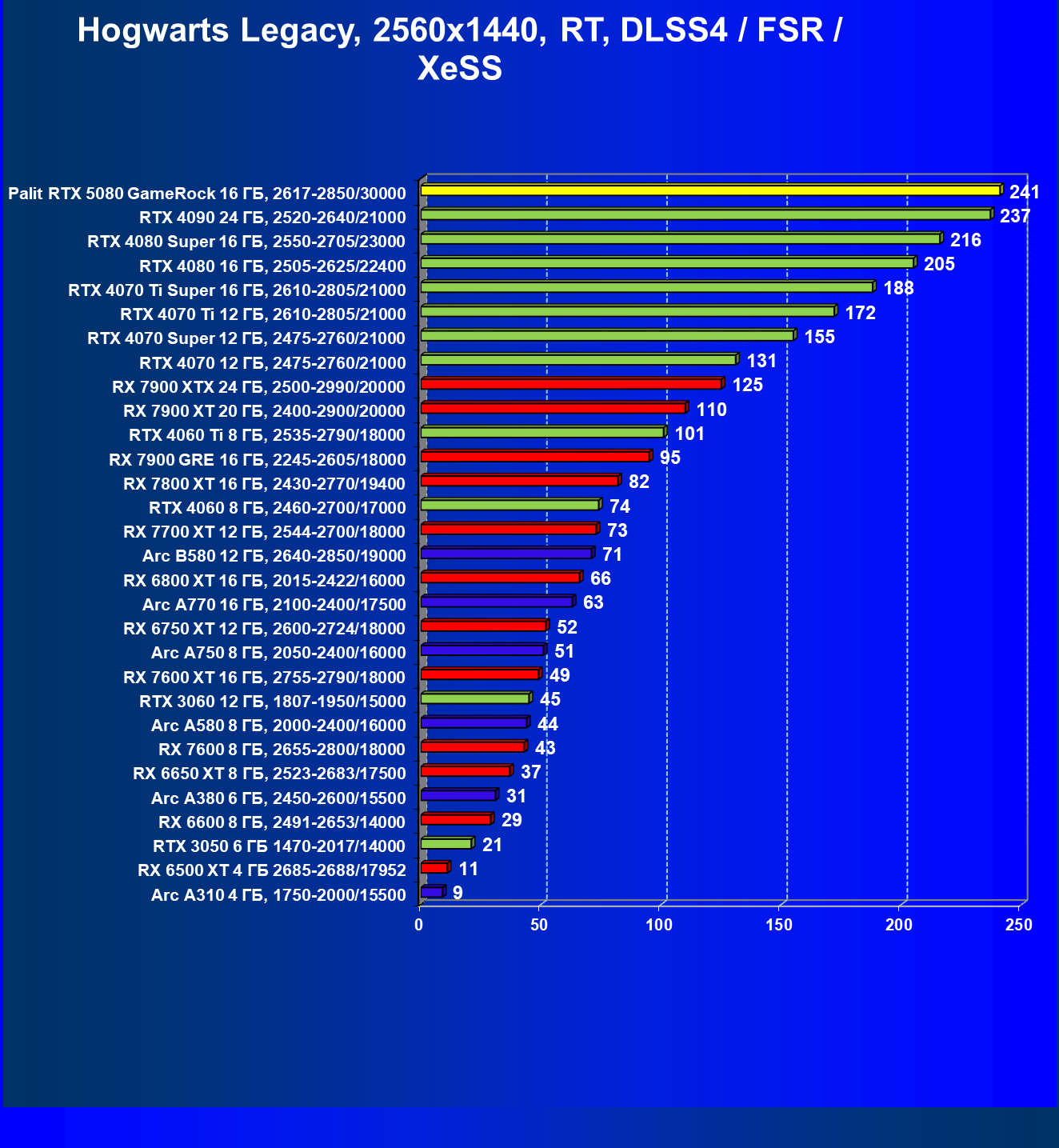

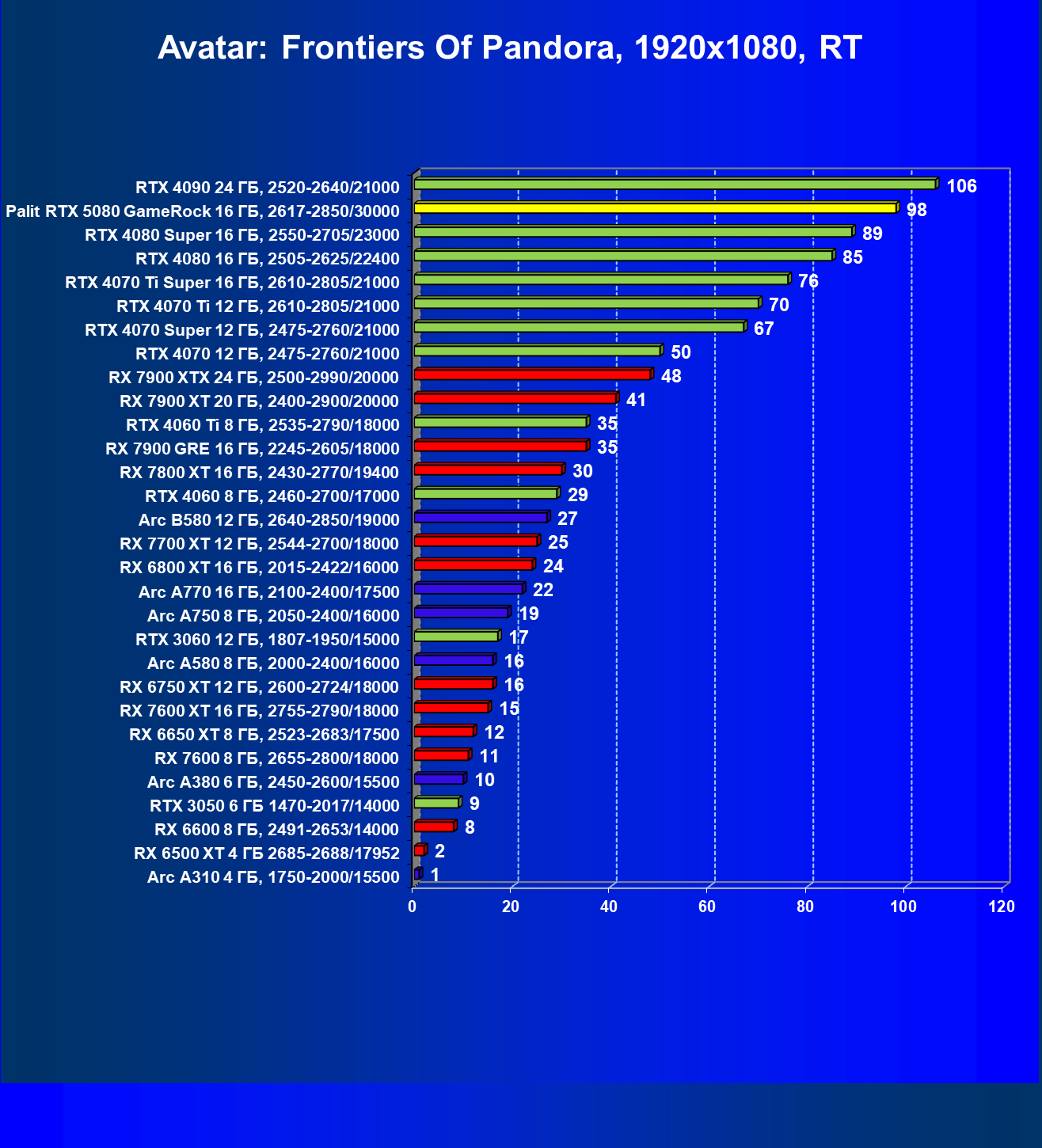
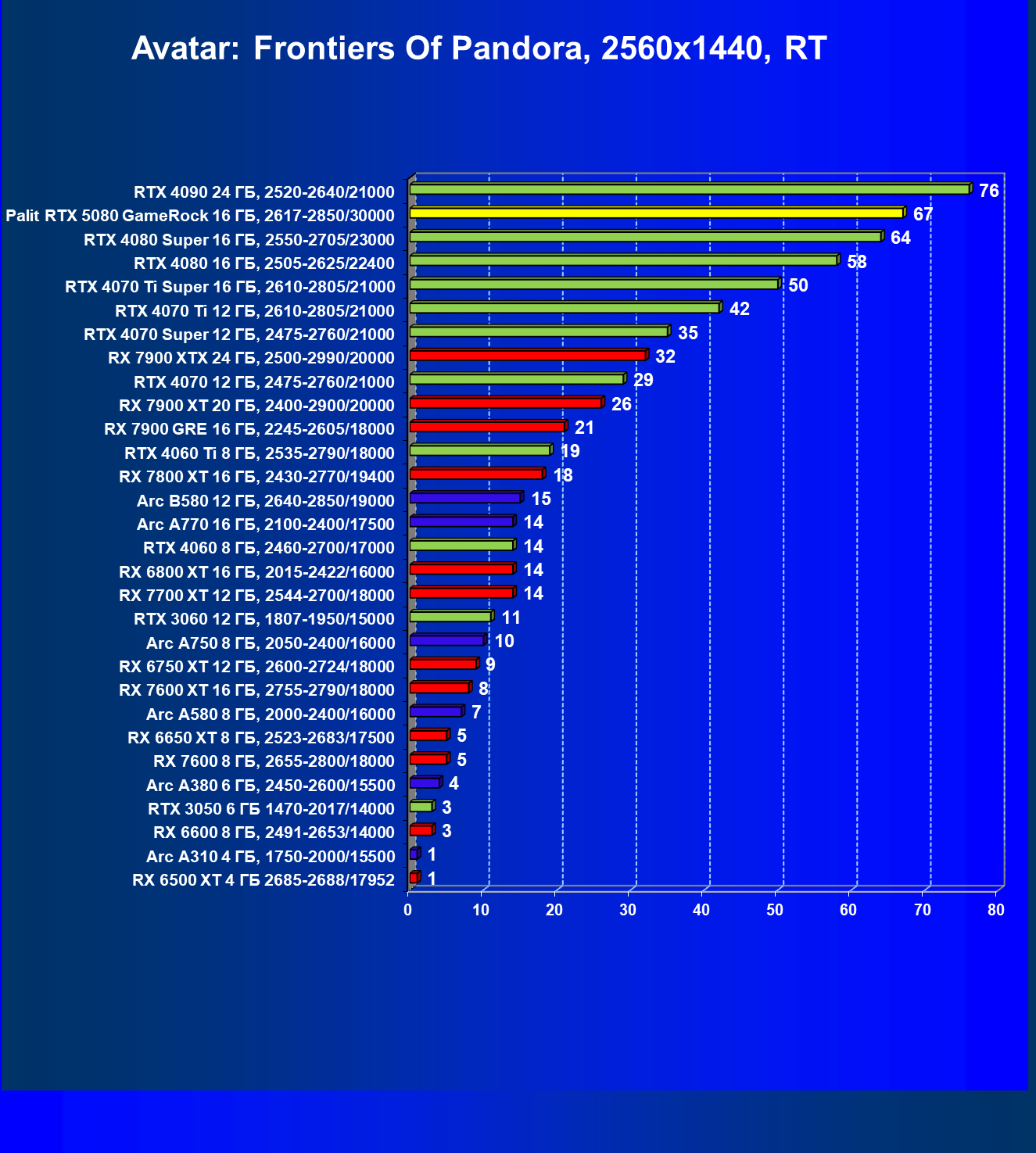
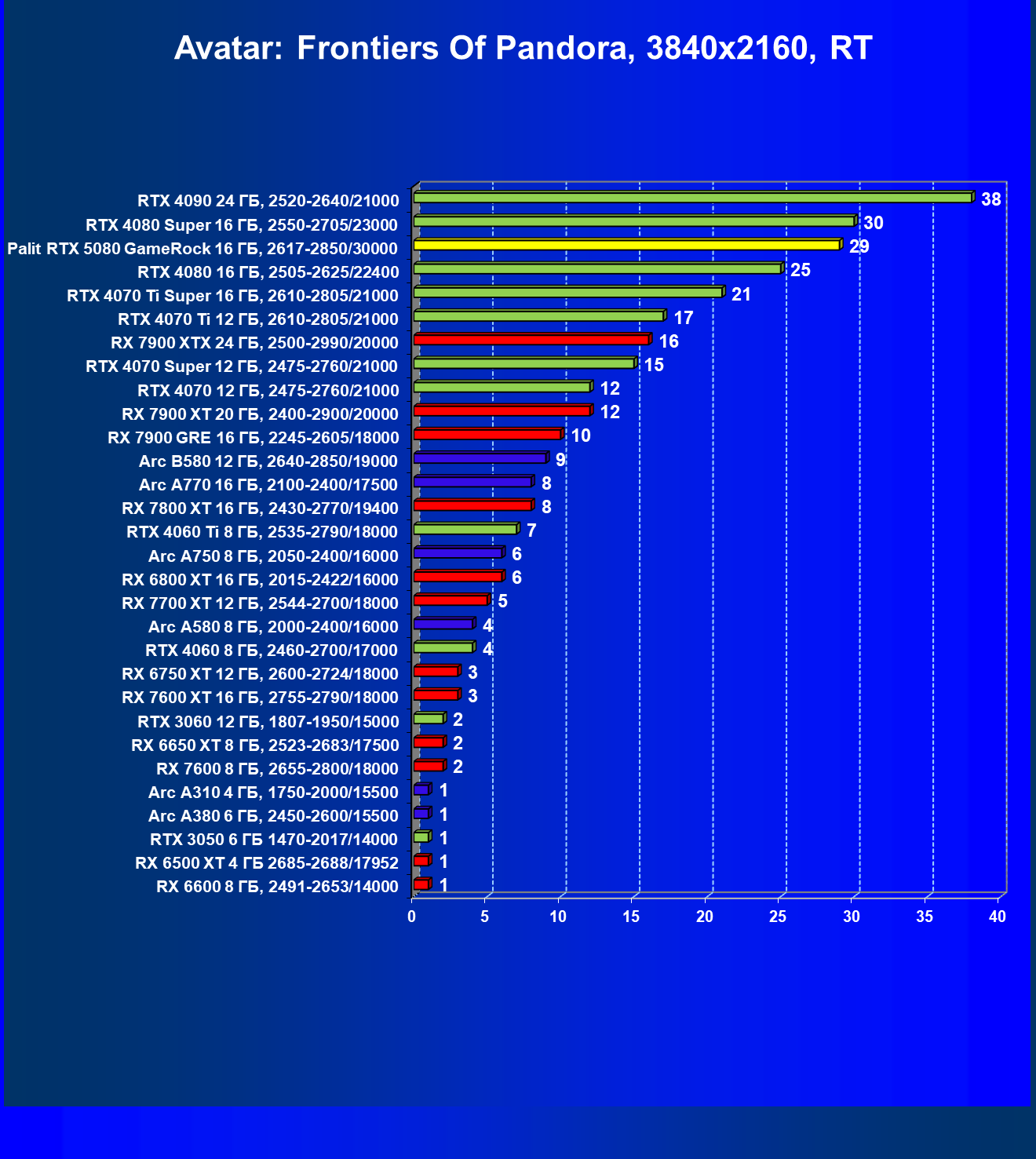
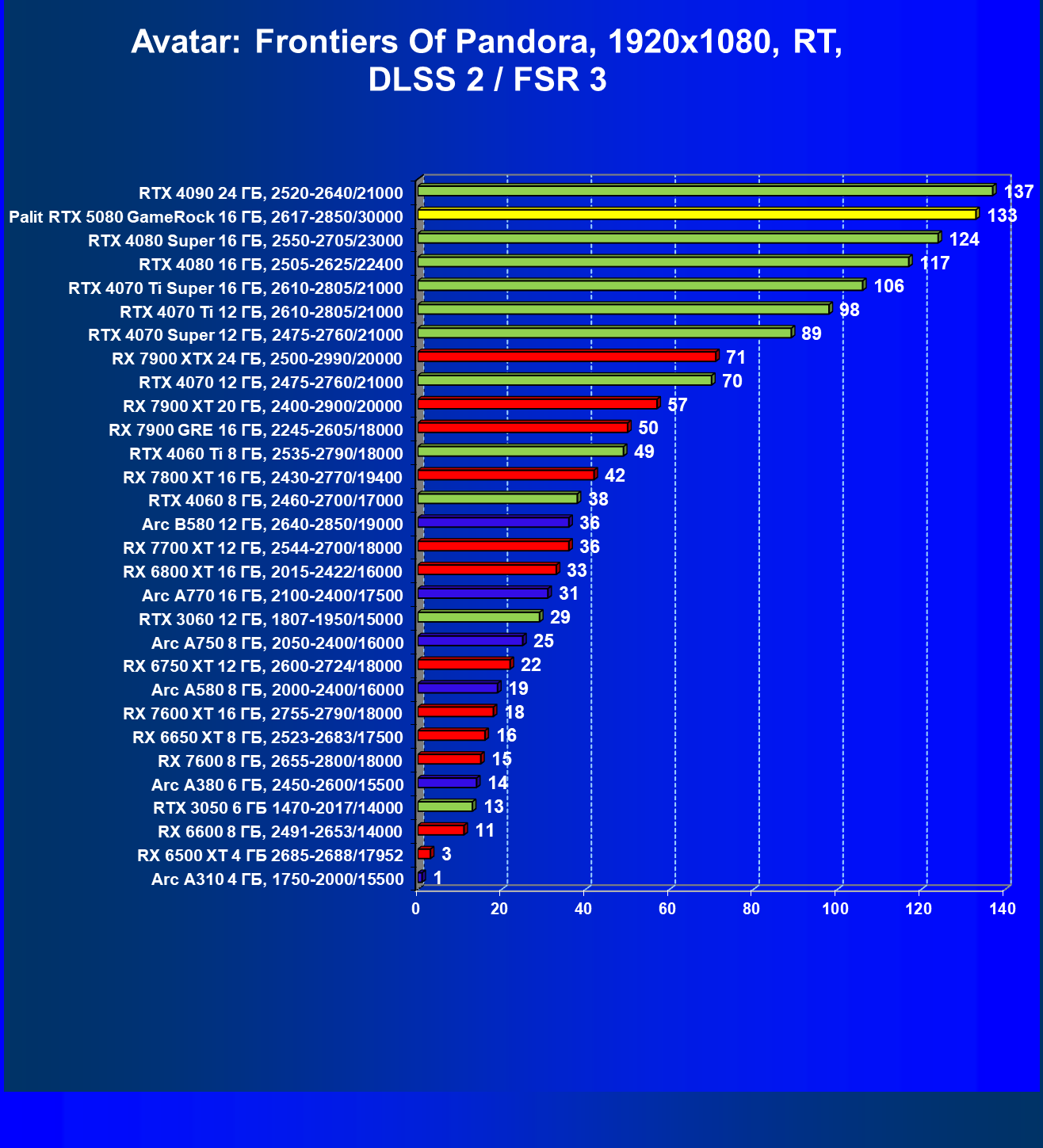
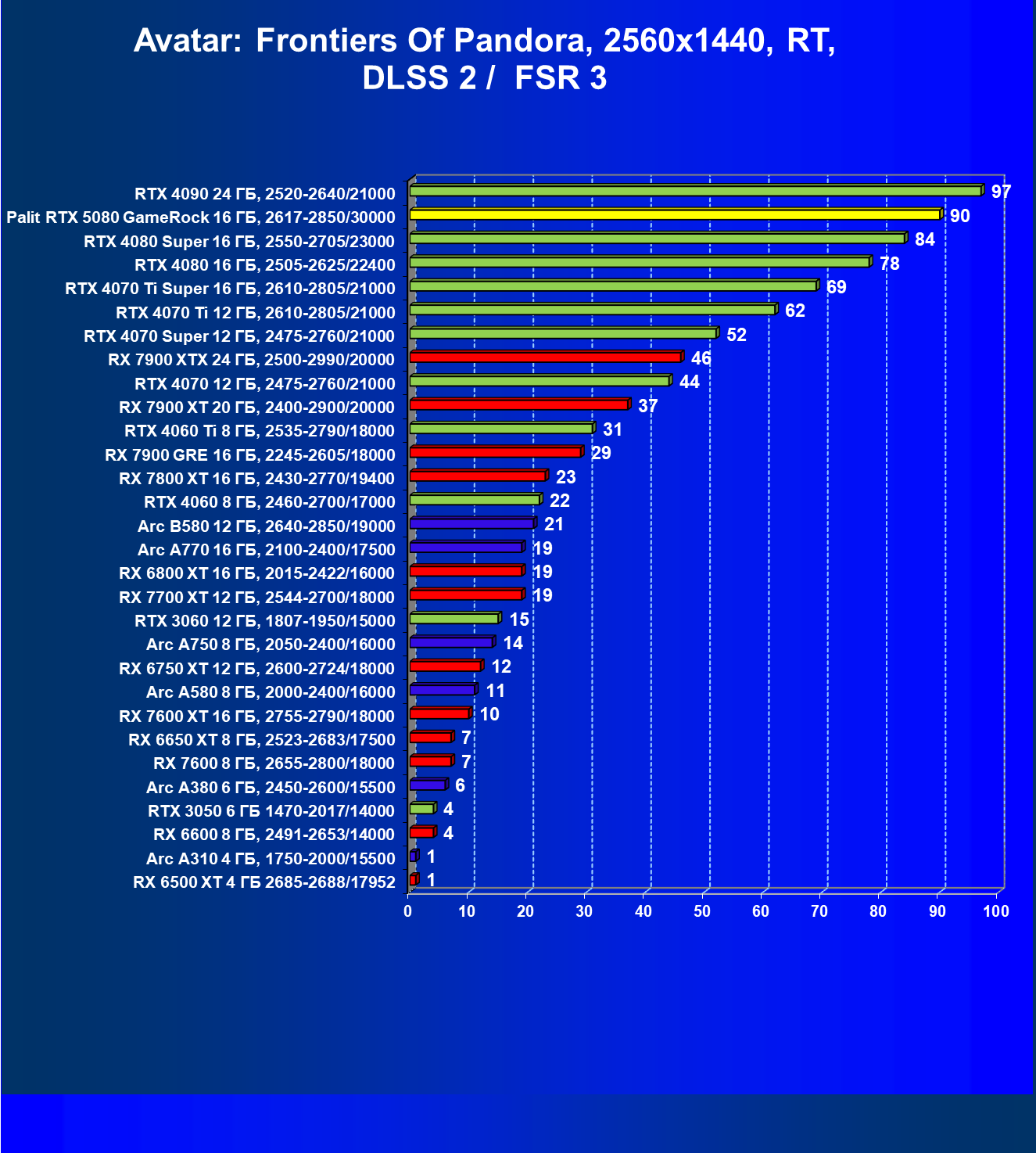
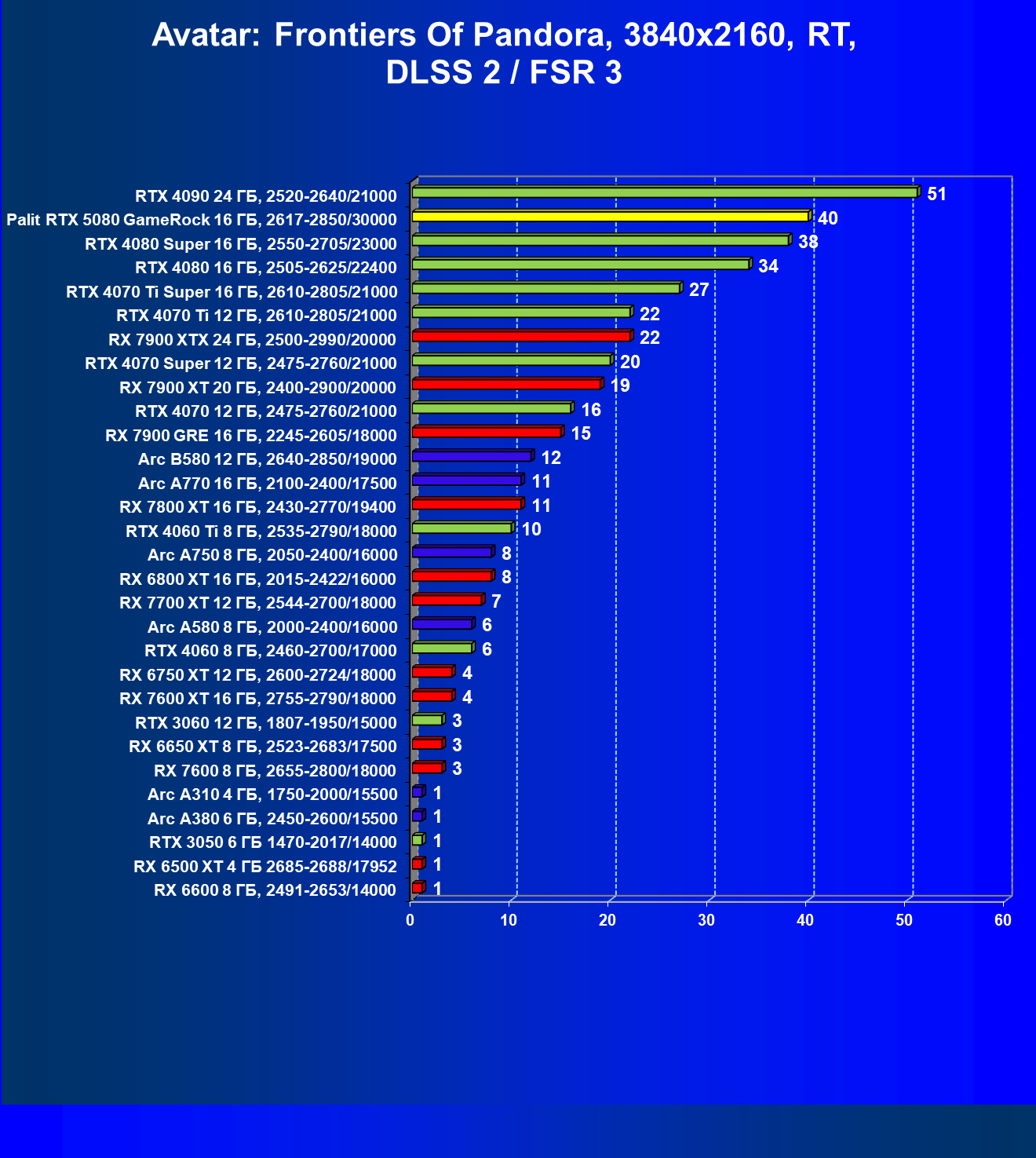
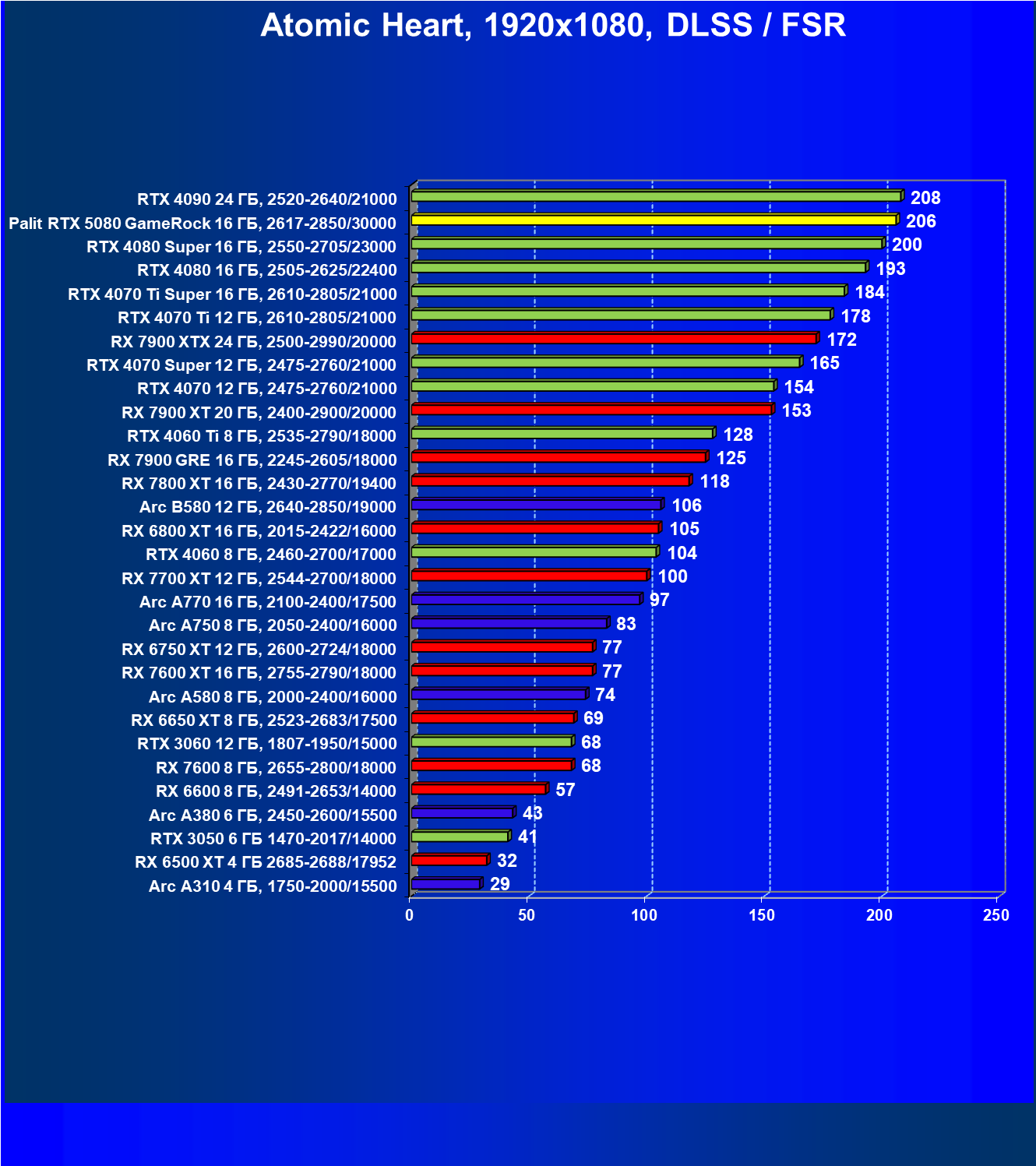
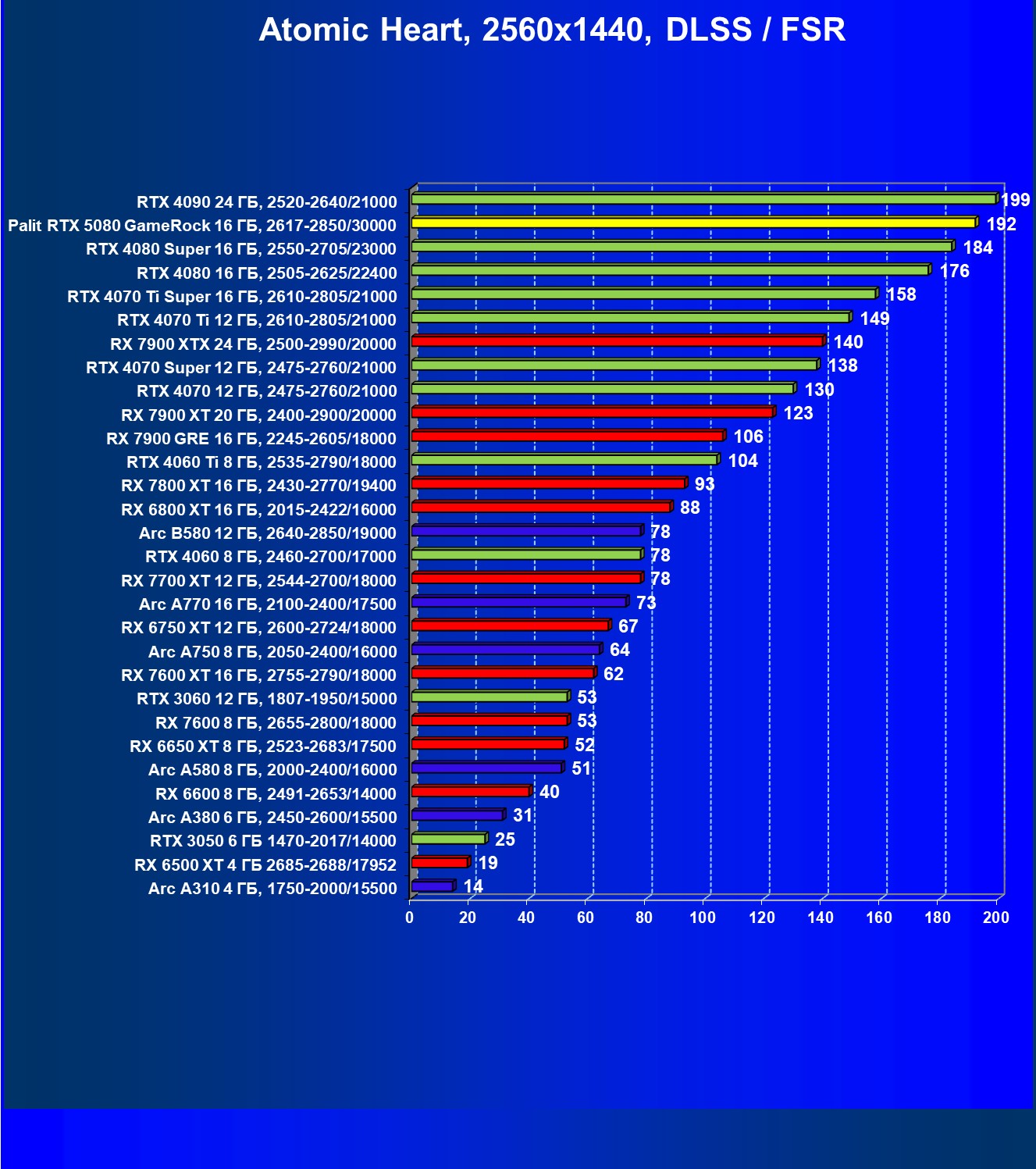
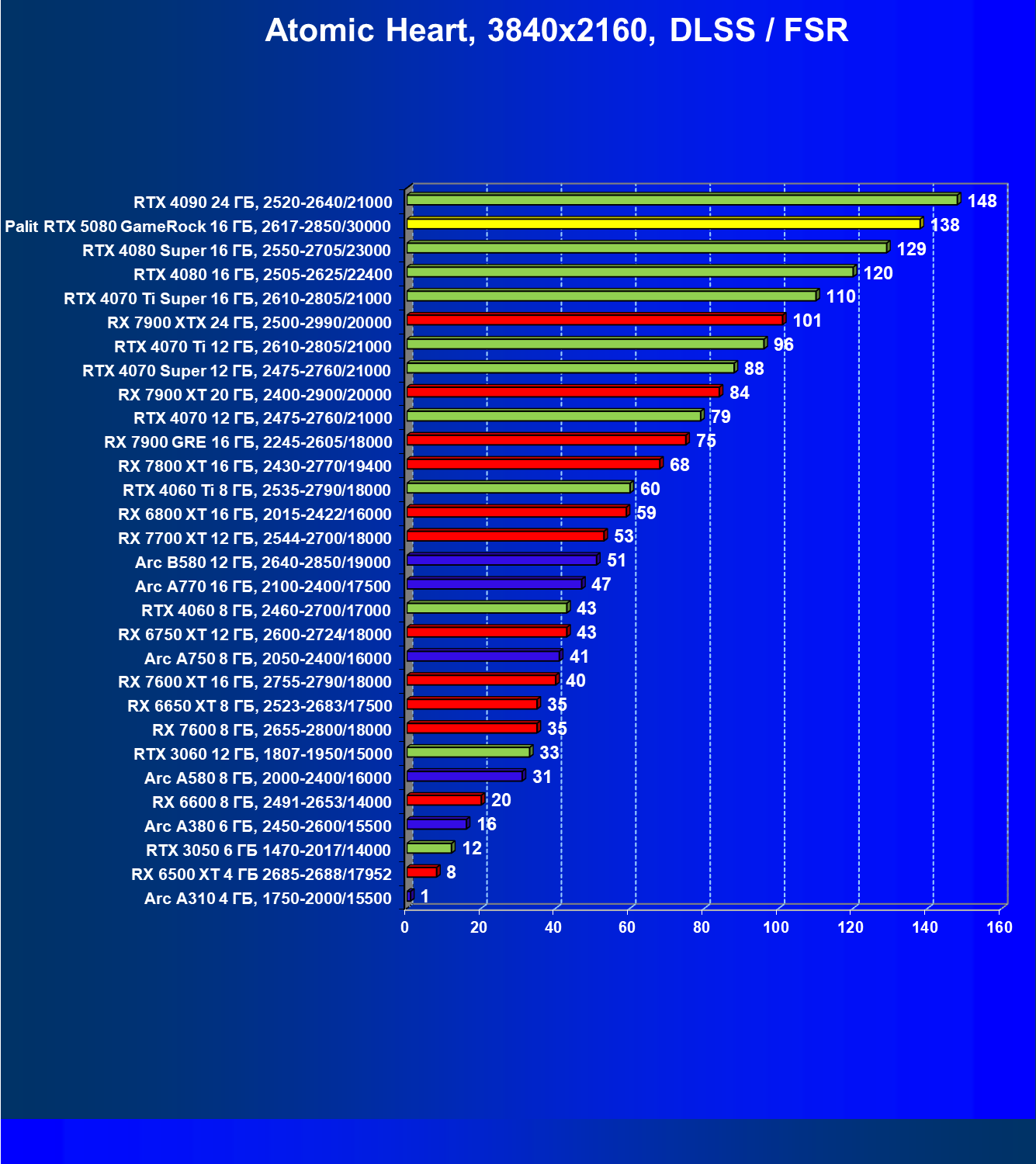
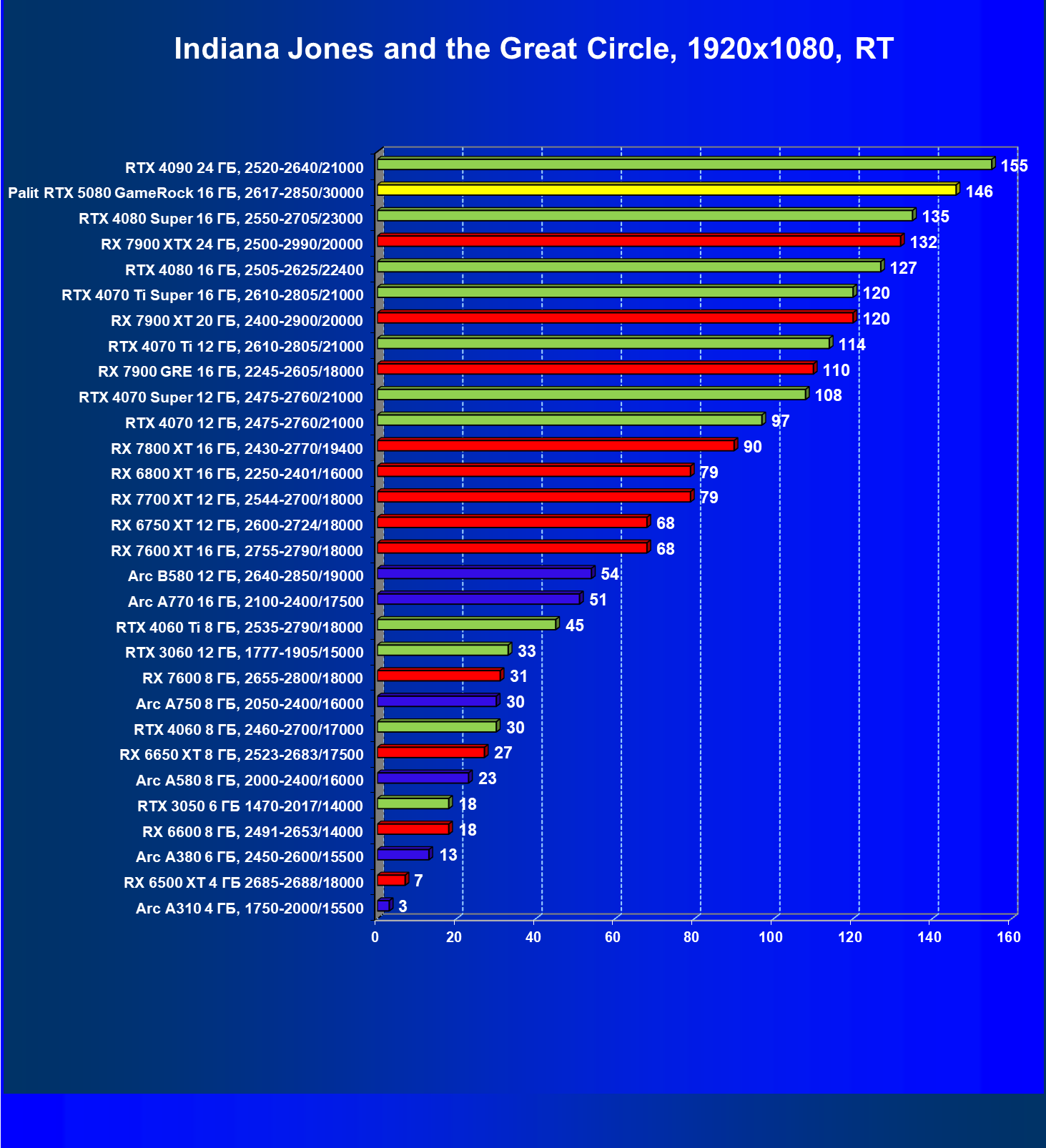

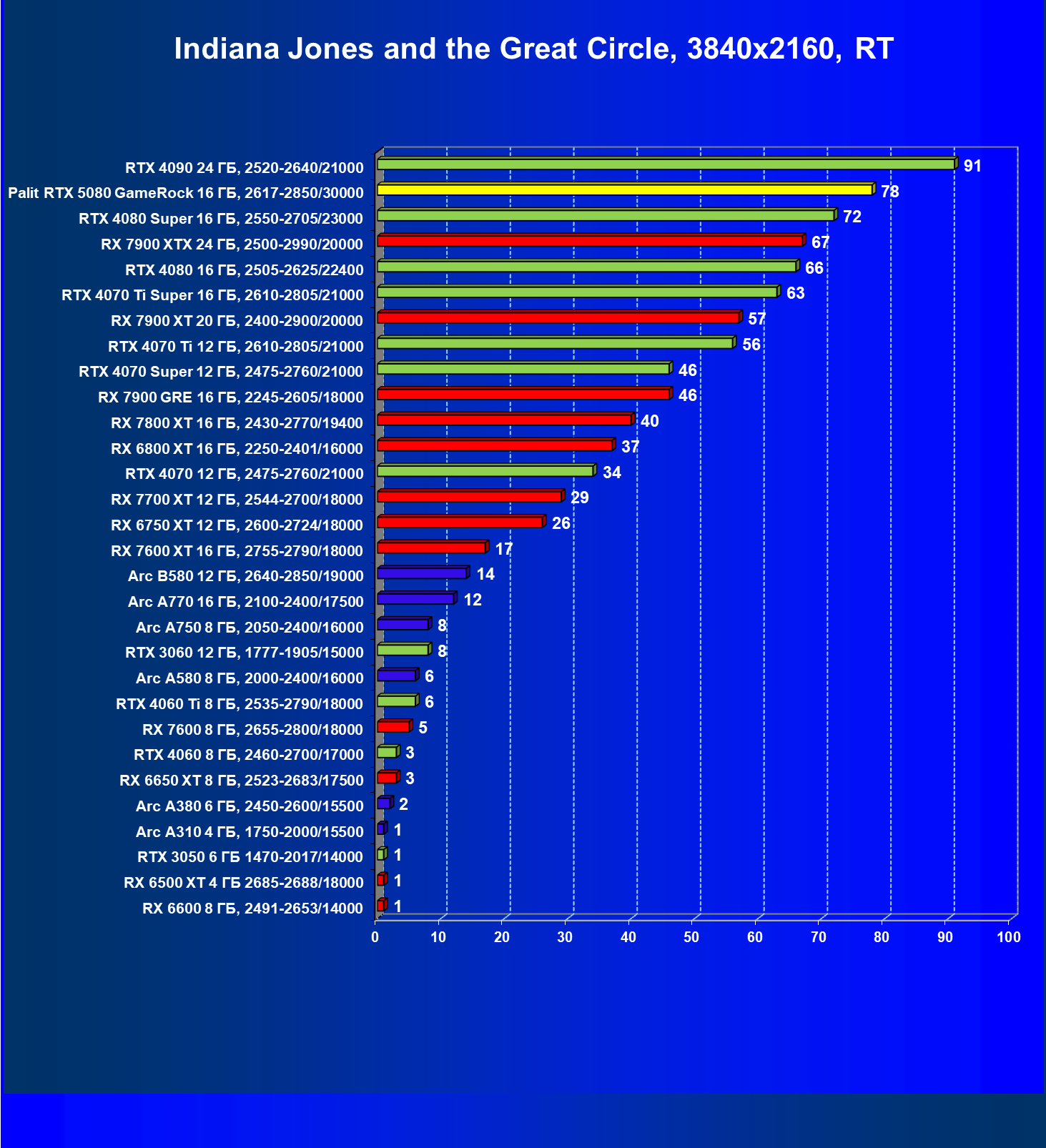
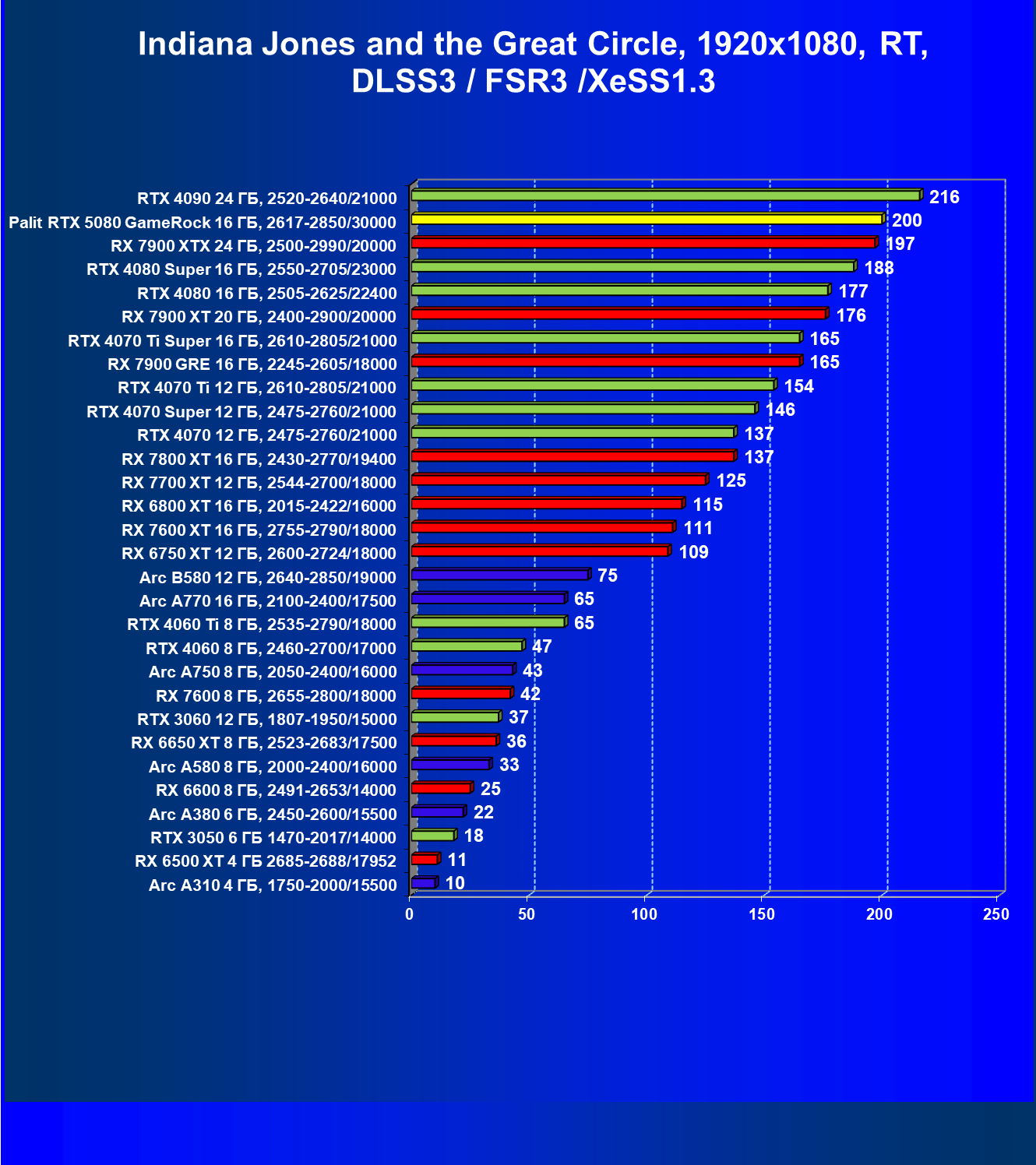


Результаты тестов с включенной аппаратной трассировкой лучей и DLSS/FSR/XeSS в разрешении 7680×4320 (8К)
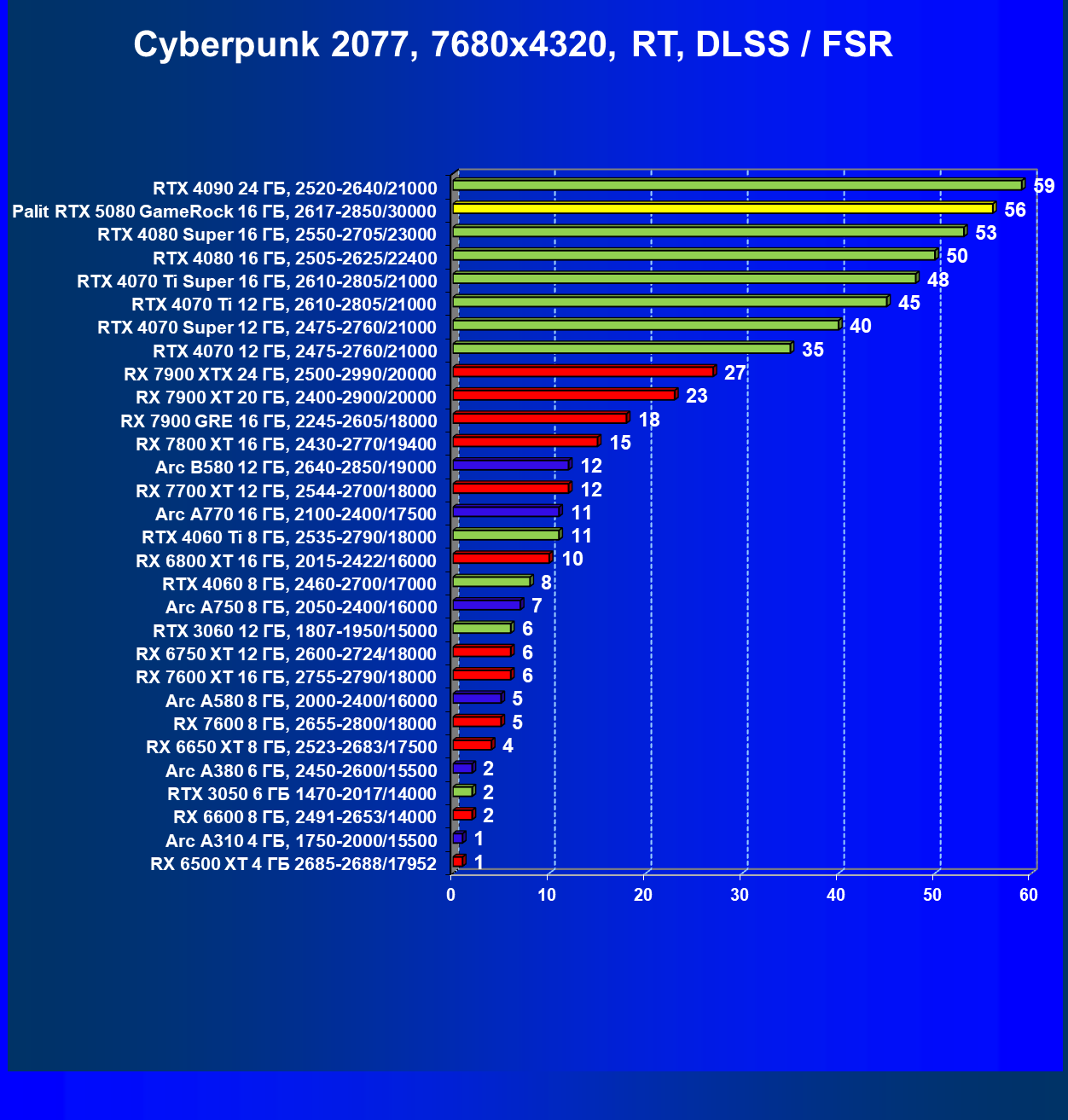
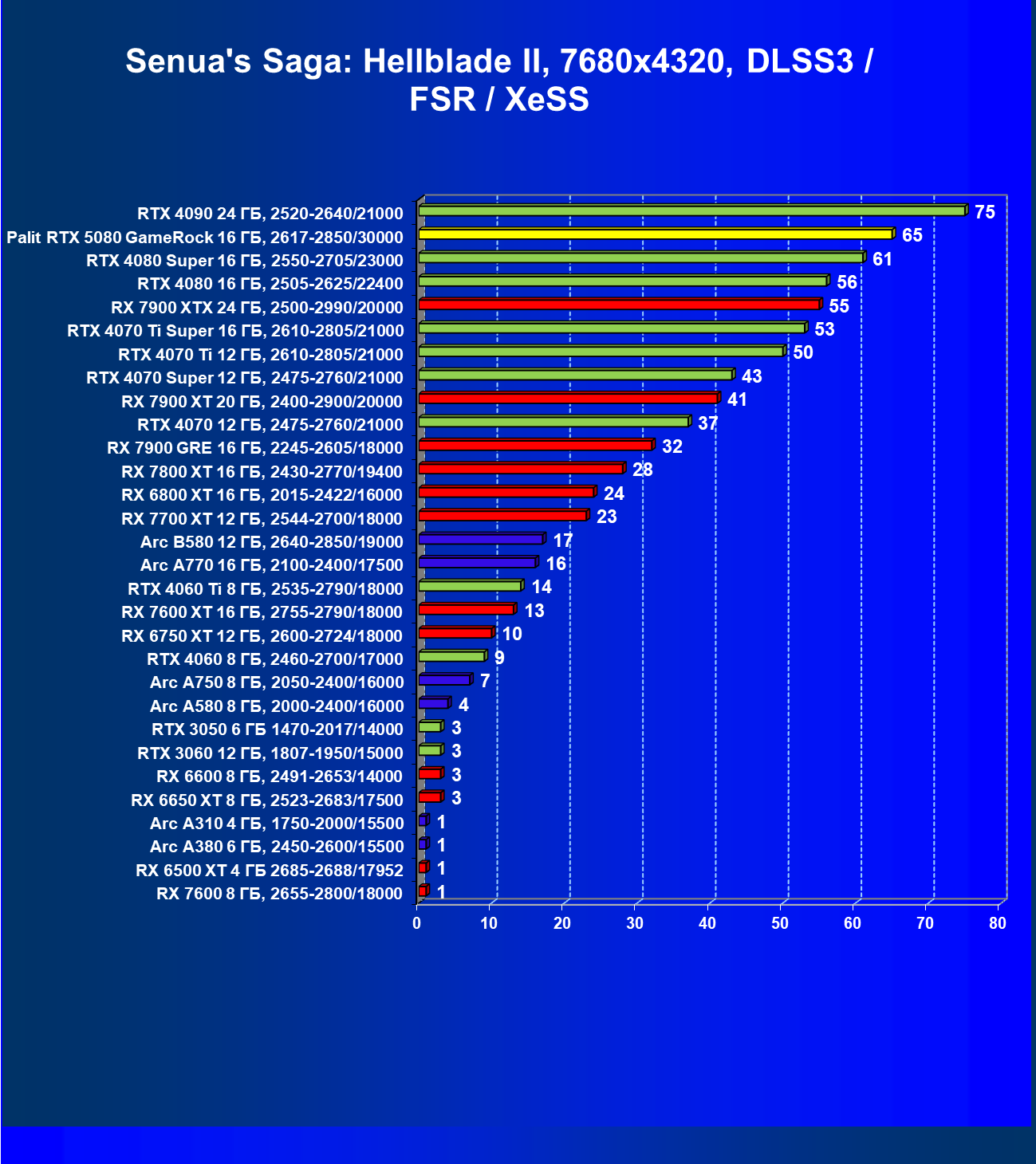
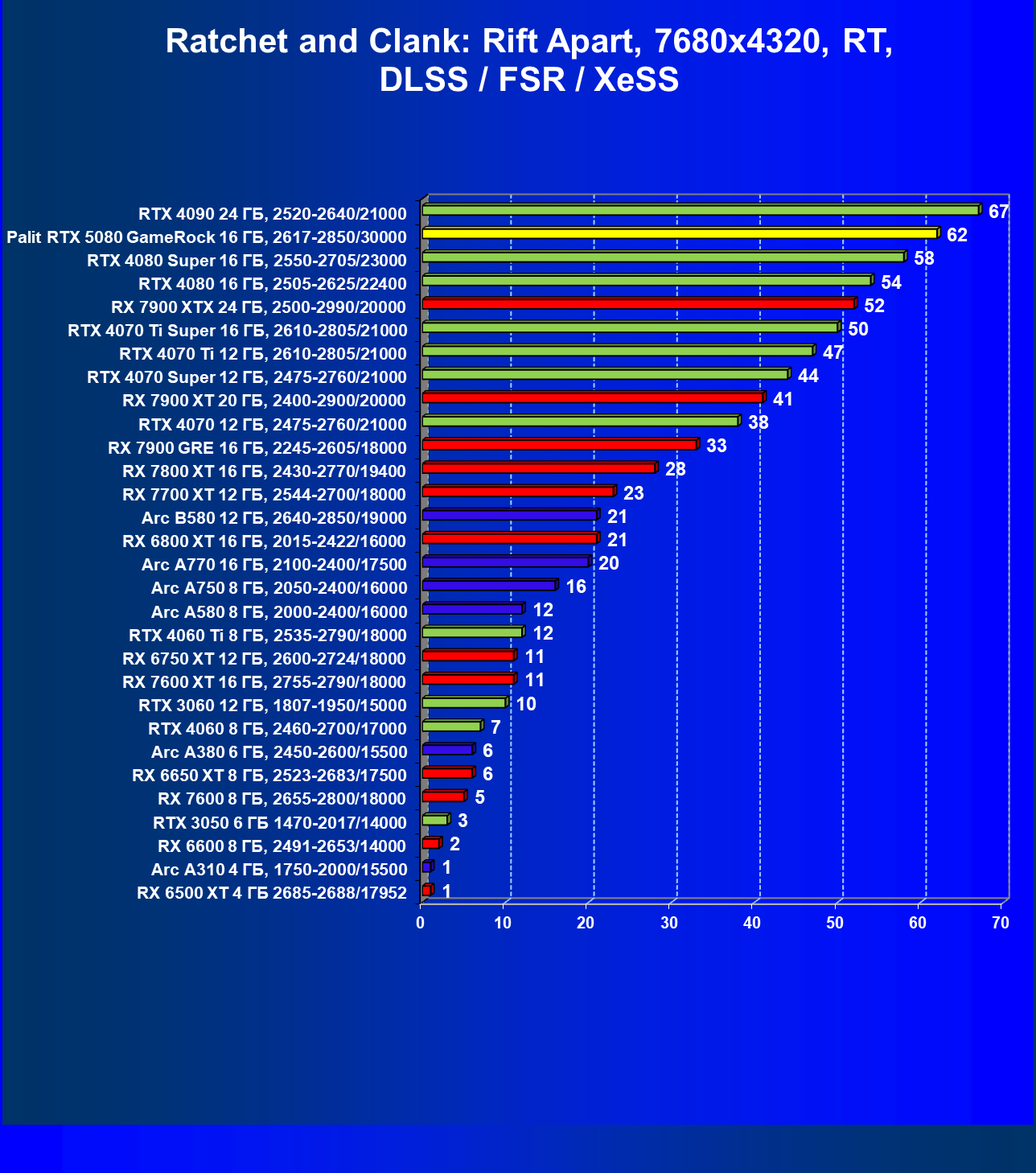
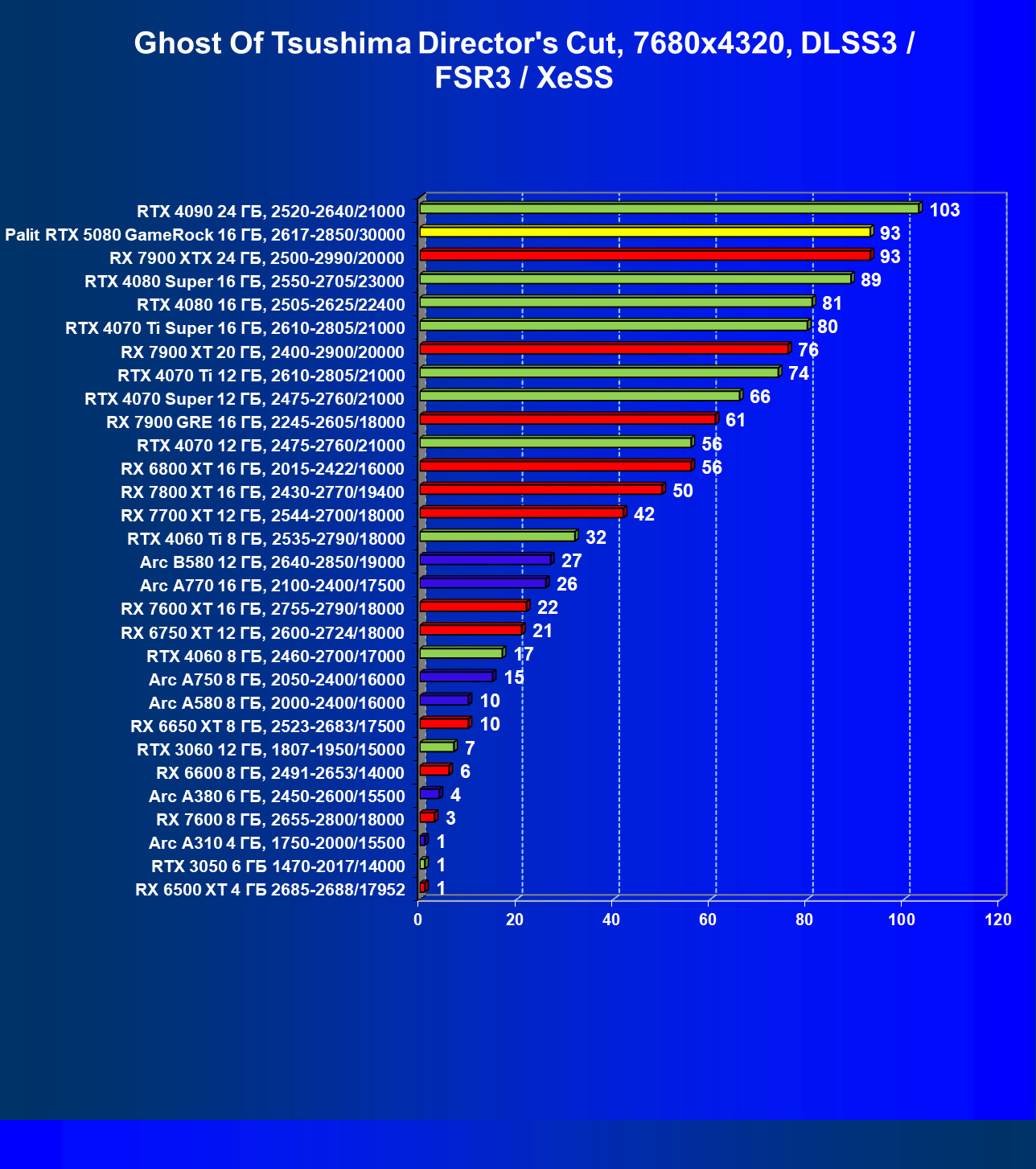
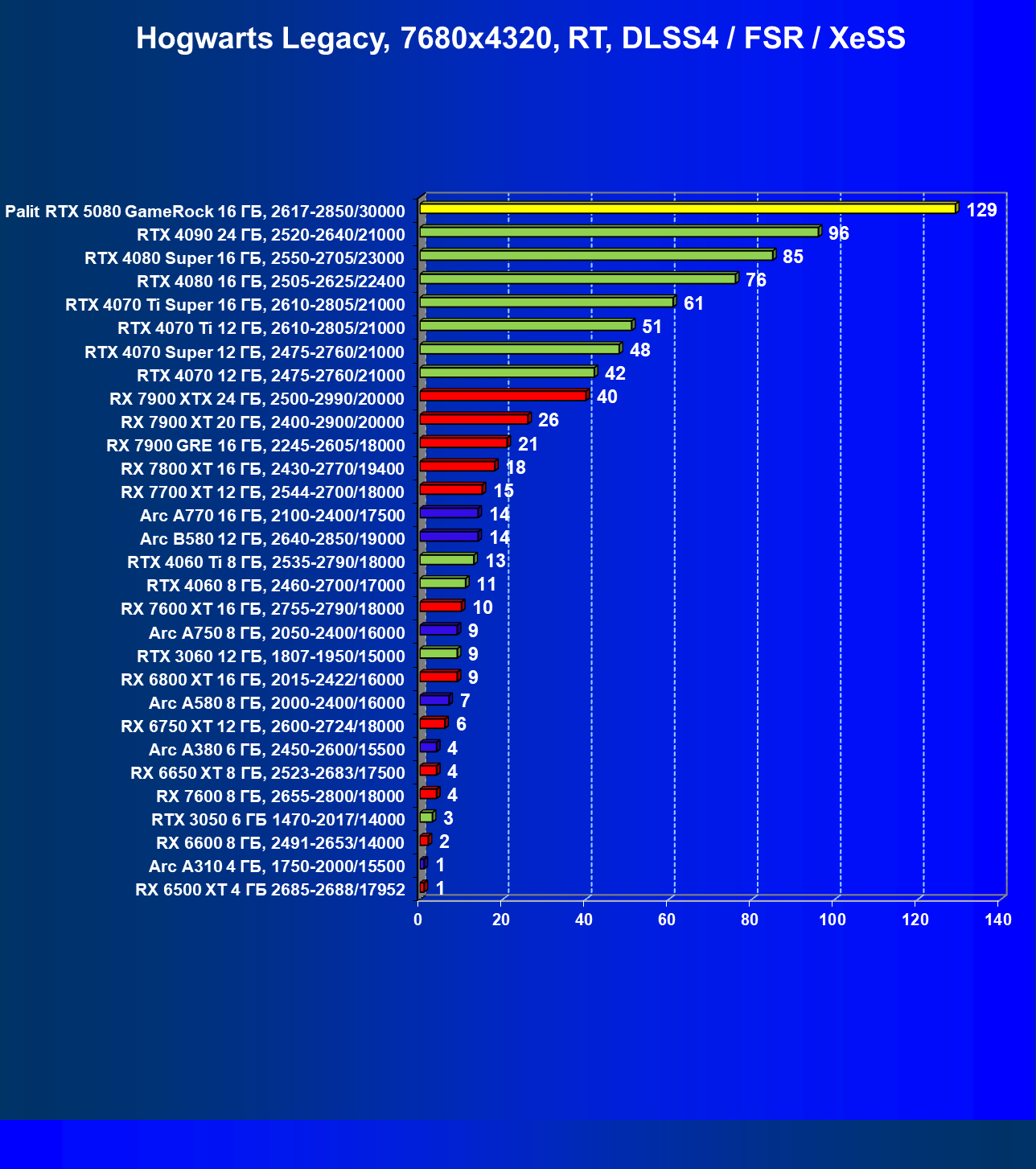
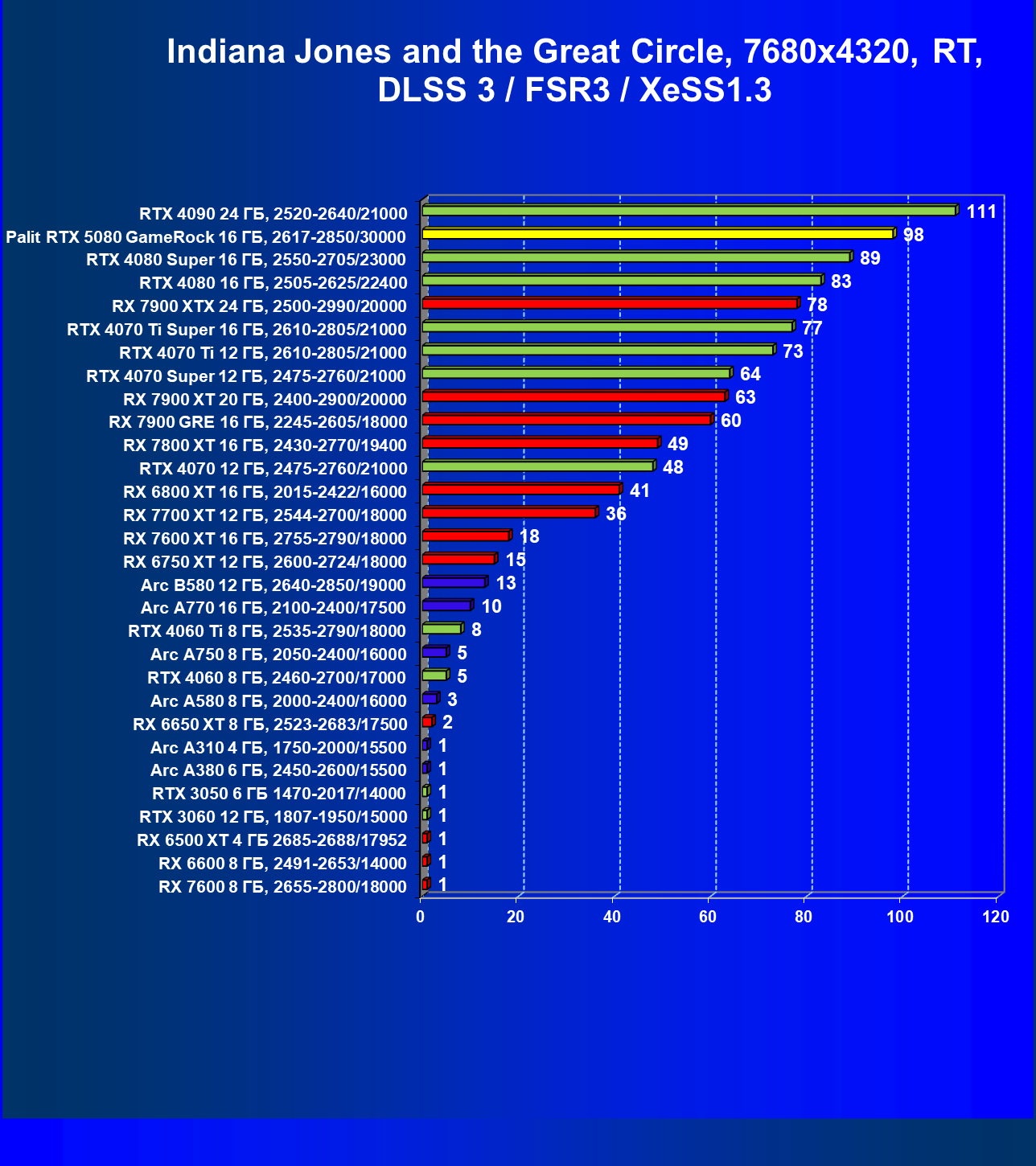

Рейтинг iXBT.com
Рейтинг ускорителей iXBT.com демонстрирует нам функциональность видеокарт друг относительно друга и представлен в двух вариантах:
- Вариант рейтинга iXBT.com без включения RT
Рейтинг составлен по всем тестам без использования технологий трассировки лучей. Этот рейтинг нормирован по наиболее слабому ускорителю из группы карт — Arc A310 (то есть сочетание скорости и функций Arc A310 приняты за 100%). Рейтинги ведутся по 30 регулярно исследуемым нами акселераторам в рамках проекта Лучшая видеокарта месяца. В данном случае из общего списка выбрана группа карт для анализа, в которую входят GeForce RTX 5080 и его конкуренты.
Рейтинг приведен для разрешения 4K.
| № | Модель ускорителя | Рейтинг iXBT.com | Рейтинг полезности | Цена, руб. |
|---|---|---|---|---|
| 01 | RTX 4090 24 ГБ, 2520—2640/21000 | 5365 | 188 | 286 000 |
| 02 | Palit RTX 5080 GameRock 16 ГБ, 2617—2850/30000 | 4899 | 272 | 180 000 |
| 03 | RTX 4080 Super 16 ГБ, 2550—2705/23000 | 4484 | 356 | 126 000 |
| 04 | RX 7900 XTX 24 ГБ, 2500—2990/20000 | 4412 | 398 | 111 000 |
| 05 | RTX 4080 16 ГБ, 2505—2625/22400 | 4152 | 338 | 123 000 |
В среднем в разрешении 4K новинка в лице GeForce RTX 5080 опережает GeForce RTX 4080 Super на 9,2%, GeForce RTX 4080 — на 18%, а Radeon RX 7900 XTX — на 11%. При этом GeForce RTX 5080 отстает от флагмана предыдущего поколения GeForce RTX 4090 на 8,6%.
Можно сказать, что современные флагманы наиболее интересны в тяжелых режимах с включением RT, их производительность в «классических» играх давно избыточна, но это всё равно не отменяет голые факты: такой прирост откровенно маловат для карт одного позиционирования в разных поколениях, он скорее соответствует разнице с ускоренными вариантами типа Super или Ti внутри одного поколения.
- Вариант рейтинга iXBT.com с включением RT/DLSS/FSR/XeSS
Рейтинг составлен по 10 тестам, в которых используется технология трассировки лучей и одновременно технология Nvidia DLSS, AMD FSR или Intel XeSS. Этот рейтинг нормирован по самому слабому ускорителю в данной группе — Arc A310 (то есть сочетание скорости и функций Arc A310 приняты за 100%).
Рейтинг приведен для разрешения 4K.
| № | Модель ускорителя | Рейтинг iXBT.com | Рейтинг полезности | Цена, руб. |
|---|---|---|---|---|
| 01 | Palit RTX 5080 GameRock 16 ГБ, 2617—2850/30000 | 12134 | 674 | 180 000 |
| 02 | RTX 4090 24 ГБ, 2520—2640/21000 | 10783 | 377 | 286 000 |
| 03 | RTX 4080 Super 16 ГБ, 2550—2705/23000 | 9184 | 729 | 126 000 |
| 04 | RTX 4080 16 ГБ, 2505—2625/22400 | 8542 | 694 | 123 000 |
| 07 | RX 7900 XTX 24 ГБ, 2500—2990/20000 | 6208 | 559 | 111 000 |
Новинка GeForce RTX 5080 уверенно заняла первое место в группе, но объясняется это тем, что в трех из десяти тестовых игр уже имеется поддержка DLSS4 с многокадровой генерацией (multiframe generation, MFG), что позволяет картам поколения GeForce RTX 50 сильно, иногда в разы опережать предшественников по производительности. О сопутствующих потерях в качестве мы поговорим в отдельном детальном материале в ближайшее время, но можем сразу сказать, что пока никаких серьезных проблем в таких играх мы не обнаружили.
Итак, сухие цифры. GeForce RTX 5080 в данном наборе игр в разрешении 4K в среднем обошел GeForce RTX 4090 на 12,5%, GeForce RTX 4080 Super — на 32,1%, GeForce RTX 4080 — на 42%, Radeon RX 7900 XTX — на 95,4%(!). Вот здесь уже ощущается смена поколений, прирост очень и очень существенный. Но не стоит забывать, что этот прирост обусловлен использованием DLSS4, а не чисто аппаратными возможностями GeForce RTX 5080.
Поэтому мы дополнительно протестировали GeForce RTX 5080 при использовании только DLSS 2/3, без DLSS4 (генерацию одного дополнительного кадра в играх с поддержкой DLSS 3 это не убирает, но позволяет сравнить GeForce RTX 50 и GeForce RTX 40 в равных условиях). Тут картина уже иная: GeForce RTX 5080 получает рейтинг iXBT.com 10065 и опережает GeForce RTX 4080 Super на 9,6%, GeForce RTX 4080 — на 17,8%, Radeon RX 7900 XTX — на 62%, но при этом отстает от GeForce RTX 4090 на 6,6%. Согласитесь, это тоже больше похоже на карту «GeForce RTX 4080 Ti Super» (или еще у Nvidia есть полузабытый суффикс Ultra), чем на следующее поколение. Остается принять как данность, что видеокарты — это программно-аппаратный комплекс, то есть программная часть в нем не менее важна, а сейчас она вообще стала самой важной.

Рейтинг полезности
Рейтинг полезности тех же карт получается, если показатель предыдущего рейтинга разделить на цены соответствующих ускорителей. Для расчета рейтинга полезности использованы розничные цены на начало февраля 2025 года.
- Вариант рейтинга полезности без включения RT
Рейтинг приведен для разрешения 4K.
| № | Модель ускорителя | Рейтинг полезности | Рейтинг iXBT.com | Цена, руб. |
|---|---|---|---|---|
| 06 | RX 7900 XTX 24 ГБ, 2500—2990/20000 | 398 | 4412 | 111 000 |
| 18 | RTX 4080 Super 16 ГБ, 2550—2705/23000 | 356 | 4484 | 126 000 |
| 20 | RTX 4080 16 ГБ, 2505—2625/22400 | 338 | 4152 | 123 000 |
| 26 | Palit RTX 5080 GameRock 16 ГБ, 2617—2850/30000 | 272 | 4899 | 180 000 |
| 28 | RTX 4090 24 ГБ, 2520—2640/21000 | 188 | 5365 | 286 000 |
GeForce RTX 5080 является горячей новинкой, цены этих карт логично завышены до предела, и к тому же мало кто из продвинутых пользователей, отдавших огромные деньги за такую видеокарту, ограничится играми без RT и/или технологий динамического масштабирования, так что сейчас обращать внимание на этот рейтинг, наверное, не имеет смысла.
- Вариант рейтинга полезности с включением RT/DLSS/FSR/XeSS
Рейтинг приведен для разрешения 4K.
| № | Модель ускорителя | Рейтинг полезности | Рейтинг iXBT.com | Цена, руб. |
|---|---|---|---|---|
| 05 | RTX 4080 Super 16 ГБ, 2550—2705/23000 | 729 | 9184 | 126 000 |
| 07 | RTX 4080 16 ГБ, 2505—2625/22400 | 694 | 8542 | 123 000 |
| 08 | Palit RTX 5080 GameRock 16 ГБ, 2617—2850/30000 | 674 | 12134 | 180 000 |
| 13 | RX 7900 XTX 24 ГБ, 2500—2990/20000 | 559 | 6208 | 111 000 |
| 21 | RTX 4090 24 ГБ, 2520—2640/21000 | 377 | 10783 | 286 000 |
Относительно цены здесь применимы те же самые соображения, но мы решили воспользоваться этим рейтингом, чтобы пойти от обратного и выявить адекватную стоимость новинки. Все-таки GeForce RTX 5080 позиционируется именно как флагманская игровая карта, поэтому ситуация с GeForce RTX 4090, активно используемой в серверах и дата-центрах для расчетов и для построения нейронных сетей, к ней неприменима. Так вот, мы прикинули, при какой стоимости GeForce RTX 5080 обошел бы соперников GeForce RTX 4080/Super (при сохранении их текущей стоимости) в нашем рейтинге, и получили 150 тысяч рублей.

Выводы и сравнение энергоэффективности
Ускоритель Nvidia GeForce RTX 5080 (16 ГБ) — представитель нового поколения GeForce RTX 50, модель второго сверху уровня (после GeForce RTX 5090), однако флагманский чисто игровой продукт (GeForce RTX 5090 — не чисто игровая видеокарта).
Для начала анализа давайте совершим небольшой экскурс в прошлое. Посмотрим, насколько отличались «предфлагманы» новых поколений от флагманов предыдущих, обратившись к нашим же обзорам и сводным таблицам рейтинга iXBT.com. На цены смотреть не стоит (курс рубля был совершенно другим). Разумеется, мы берем классические игры без трассировки лучей и технологий динамического масштабирования.
GeForce RTX 2080 (второй после GeForce RTX 2080 Ti) против GeForce GTX 1080 Ti (флагман):
Мы видим, что в среднем GeForce RTX 2080 опережал GeForce RTX 1080 Ti на 18%. (Повторим, что это карта второго уровня нового поколения против топового ускорителя предыдущего поколения, сейчас это соответствует сравнению GeForce RTX 5080 и GeForce RTX 4090.)
GeForce RTX 3080 (второй после GeForce RTX 3090) против GeForce GTX 2080 Ti (флагман):
В данном случае GeForce RTX 3080 (второй в линейке GeForce RTX 30 на момент выпуска, потому что GeForce RTX 3090 Ti вышел много позже) опережал GeForce RTX 2080 Ti (первый в линейке GeForce RTX 20) в среднем на 25% — опять же, новая карта оказалась быстрее, причем в данном случае более значительно.
GeForce RTX 4080 (второй после GeForce RTX 4090) против GeForce GTX 3090 Ti (флагман):
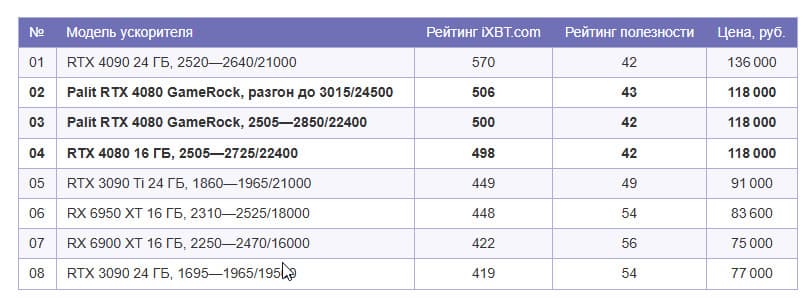
Разница между GeForce RTX 4080 (второй в линейке GeForce RTX 40) и GeForce RTX 3090 Ti (первый в линейке GeForce RTX 30) сократилась до 11%, но всё равно ускоритель второго уровня нового поколения был быстрее ускорителя первого (флагманского) уровня предыдущего поколения.
А что мы видим сейчас? GeForce RTX 5080 не только не обгоняет GeForce RTX 4090, но и отстает от него по «чистой» производительности, и довольно заметно. Не просто так масса обозревателей дает GeForce RTX 5080 названия вроде «GeForce RTX 4080 Super Ti».

Цены — отдельная история. Очевидно, что рекомендованной розничной цены в 999 долларов никто в ближайшей перспективе не увидит, даже если прибавить налоги (может быть, только ближе к выходу следующего поколения). Тут два очень весомых фактора:
- По подобным ценам (999 долларов плюс налоги) могут продаваться только карты самой Nvidia, поскольку они продукт не массовый, выпускаются небольшими партиями (дизайн дорогой и очень сложный), а Nvidia может себе позволить получать минимум прибыли от продажи Founders Edition (в основном такие карты работают на имидж производителя). Партнеры Nvidia не в состоянии продавать свои модели так же дешево, потому что получают чипы по весьма высокой цене (здесь Nvidia должна зарабатывать, и много), плюс проблема с GDDR7, которая очень дорогая (хоть при покупке в комплекте с GPU у Nvidia, хоть при отдельном приобретении памяти у Samsung). Вполне вероятно, что стоимость карты на выходе с конвейера уже превышает эти 999 долларов. А еще надо зарабатывать дистрибьютерам и магазинам. Вот и получается, что это никакая не MSRP (рекомендованная производителем розничная цена).
- В Nvidia не могли не знать, что 29 января 2025 г. начинается китайский Новый год, а это значит, что минимум на 2 недели вся активность в КНР останавливается, и частенько еще за 3-5 дней до наступления праздника. 90% видеокарт производятся именно в Китае, там же начинаются логистические маршруты (и их обслуживанием тоже занимаются китайцы, которые хотят праздновать). То есть что успели накопить до 20-22 января, то и отправили на прилавки, а следующие поставки начнутся не ранее 7 февраля. Вот потому и ажиотаж, на радость спекулянтам. Зачем надо было назначать продажи на такие даты? Почему нельзя было перенести на 7 февраля, как минимум? Ответ очевиден: для Nvidia это шанс создать искусственный дефицит, который, возможно, закроет их собственные промашки с производством чипов (подчеркну: возможно!).
Так и иначе, карты появились в продаже, на момент написания материала мы видели в розничной торговле цены карт на базе GeForce RTX 5080 от 170 до 220 тысяч рублей. И понятно, что за 170 тысяч купить их было практически невозможно. Но мы полагаем, что в скором времени ажиотаж уляжется и цены зафиксируются на уровне плюс-минус 180 тысяч рублей. Поэтому для нашего рейтинга полезности взяли именно такую цену. Разумеется, в обзорах серийно выпускаемых видеокарт мы будем корректировать рейтинг исходя из актуальных цен на тот момент. Выше мы уже писали, что, по нашим подсчетам, исходя из текущих цен на конкурирующие модели, GeForce RTX 5080 будут смотреться привлекательно при стоимости в 150 тысяч. Однако тут имеется ряд «подводных камней».
Здесь мы уже плавно переходим к возможностям самого GeForce RTX 5080 и заложенным в него технологиям. Если посмотреть на спецификации графического ядра и сделать грубую оценку, то в глаза бросается, что само ядро «приросло» совсем чуть-чуть (относительно предшественника AD103), но зато колоссально выросла пропускная способность памяти (ПСП) из-за использования GDDR7 со скоростью 30 Гбит/с (при той же шине обмена с памятью в 256 бит). И весьма возможно, что львиная доля прироста производительности получена именно за счет выросшей ПСП. Проверить мы не можем, так как невозможно ни понизить частоту работы видеопамяти на GeForce RTX 5080 до уровня GeForce RTX 4080, ни поднять частоту работы видеопамяти на GeForce RTX 4080 до уровня GeForce RTX 5080 (нельзя даже «встретиться посередине»). Безусловно, новое ядро — это не просто AD103 с увеличенным количеством тех или иных блоков и снабженное быстрой памятью. Но про нюансы архитектуры Blackwell мы уже подробно всё рассказали, в том числе остановившись на особенностях работы Blackwell с новой технологией мультикадровой генерации (MFG). А теперь посмотрите еще раз на первые тесты GeForce RTX 5080 с использованием технологии DLSS 4, особенно при генерации трех и более кадров на основе разных моделей ИИ, и оцените, как GeForce RTX 5080 обходит предыдущего флагмана GeForce RTX 4090 в таких тестах.
Получается, что GeForce RTX 5080 вполне вписывается в утвержденную временем формулу, когда вторые по производительности ускорители нового поколения обгоняют флагманов предшествующего поколения — но он достигает этого только при использовании MFG. Не случайно буквально на днях Nvidia выпустила новую версию драйвера, в которую вошла не менее новая версия их фирменного приложения Nvidia App, позволяющая ускорителям поколения GeForce RTX 50 принудительно включать MFG в играх, поддерживающих старую технологию генерации промежуточных кадров (DLSS 3), а таких игр уже много. То есть список игр, в которых карты GeForce RTX 50 могут получить колоссальный прирост производительности, автоматически резко вырос.
Да, остался вопрос качества графики при использовании DLSS 4, возможных задержек и лагов. Мы всё это разберем в отдельном материале, который выйдет весьма скоро. Это очень сложный аспект, и его невозможно исследовать в рамках обычного обзора видеокарты или даже текущего базового материала. Пока лишь отметим, что в трех играх (Alan Wake 2, Cyberpunk 2077 и Hogwarts Legacy), в которые уже внедрена (через патчи) поддержка технологии DLSS 4, явных нареканий на качество не было — встречались лишь мелкие артефакты, которые не портили впечатление (при генерации 4 кадров). Мы полагаем, что, как и в случае с первой версией DLSS, оптимизации под те или иные игры будут вестись непрерывно, и DLSS 4 можно будет пользоваться совершенно полноценно.
Если внимательно изучить саму основу MFG, становится понятно, что доля программной работы в видеокарте (как аппаратно-программном комплексе) сильно выросла. И даже если GPU имеет не сильно отличающийся от предшественника традиционный набор аппаратных блоков, но при этом получил ряд средств, позволяющих активно работать с нейронными сетями, включая программные оптимизации, он может претендовать на звание ускорителя нового поколения.
Да, нравится это нам или нет, а программная часть работы ускорителей становится всё более весомой, всё активнее использует имеющиеся наработки в области ИИ (нейронных сетей), а аппаратная часть GPU должна иметь нужные для быстрых вычислений блоки. Собственно, об этом говорил и глава Nvidia во всех последних публичных выступлениях. Следует ли отсюда вывод, что игровая индустрия будет мигрировать в сторону «выдумывания» кадров или даже целых сцен по ходу действия игр? Время покажет, но нам видится, что эти страхи преувеличены. Полагаем, что дальше генерации нескольких кадров дело не пойдет, ибо непредсказуемо, как поведет себя ИИ, дай ему волю что-то «генерить» внутри игры. К тому же, во многих странах есть цензоры игровых решений, которые могут запретить игру, что крайне невыгодно издателям. Поживем увидим. Но мы уже живем в интересное время, когда видеокарта может «перепрыгивать» флагманские решения исключительно за счет Gen AI.
Возвращаемся с небес на землю.
В классических играх без RT и прочих программных улучшений, а также в играх с RT и/или с технологиями динамического масштабирования DLSS(1/2/3)/FSR/XeSS новый ускоритель GeForce RTX 5080 находится между GeForce RTX 4080 Super и GeForce RTX 4090 (ближе к первому). В играх, где имеется возможность задействовать DLSS 4 (Multi Frame Generation, MFG), его производительность резко возрастает, и новинка легко обгоняет GeForce RTX 4090.
Если посмотреть на энергоэффективность, то GeForce RTX 5080 по этому показателю лидирует, и остается только похвалить Nvidia за то, что она смогла создать ядро с самым лучшим соотношением производительности и энергопотребления.
| FPS/кВт | |
|---|---|
| GeForce RTX 5080 | 334 |
| GeForce RTX 4070 | 334 |
| GeForce RTX 4080 | 325 |
| GeForce RTX 4070 Ti Super | 323 |
| GeForce RTX 4080 Super | 317 |
| GeForce RTX 4060 Ti | 308 |
| GeForce RTX 4070 Super | 308 |
| GeForce RTX 4060 | 308 |
| Radeon RX 7900 XT | 308 |
| GeForce RTX 4070 Ti | 301 |
| Radeon RX 7900 XTX | 297 |
| Radeon RX 7900 GRE | 292 |
| GeForce RTX 4090 | 285 |
| Radeon RX 7800 XT | 282 |
| Arc B580 | 264 |
| Radeon RX 7700 XT | 257 |
| Radeon RX 6800 XT | 250 |
| Arc A380 | 240 |
| Arc A580 | 217 |
| Radeon RX 7600 XT | 215 |
| Radeon RX 6600 | 210 |
| GeForce RTX 3050 (6 ГБ) | 209 |
| Radeon RX 7600 | 208 |
| Radeon RX 6650 XT | 207 |
| Radeon RX 6750 XT | 198 |
| GeForce RTX 3060 (12 ГБ) | 195 |
| Arc A770 | 193 |
| Arc A750 | 174 |
| Arc A310 | 146 |
| Radeon RX 6500 XT | 80 |
| FPS/кВт | |
|---|---|
| GeForce RTX 5080 | 450 |
| GeForce RTX 4070 | 445 |
| GeForce RTX 4070 Ti Super | 428 |
| GeForce RTX 4080 | 418 |
| GeForce RTX 4070 Super | 409 |
| GeForce RTX 4080 Super | 402 |
| GeForce RTX 4070 Ti | 395 |
| GeForce RTX 4060 Ti | 374 |
| GeForce RTX 4090 | 353 |
| GeForce RTX 4060 | 352 |
| Radeon RX 7900 XT | 286 |
| Radeon RX 7900 XTX | 279 |
| Radeon RX 7900 GRE | 267 |
| Arc B580 | 264 |
| Radeon RX 7800 XT | 248 |
| Radeon RX 7700 XT | 229 |
| Radeon RX 6800 XT | 205 |
| Arc A770 | 186 |
| Radeon RX 7600 XT | 180 |
| Arc A380 | 176 |
| Arc A580 | 175 |
| GeForce RTX 3060 (12 ГБ) | 166 |
| Radeon RX 6750 XT | 155 |
| Arc A750 | 146 |
| Radeon RX 7600 | 143 |
| Radeon RX 6650 XT | 134 |
| GeForce RTX 3050 (6 ГБ) | 131 |
| Radeon RX 6600 | 120 |
| Arc A310 | 80 |
| Radeon RX 6500 XT | 43 |
GeForce RTX 5080 вышла через неделю после GeForce RTX 5090, и это несколько подпортило впечатление: она получилась не настолько яркой, как флагман. Да, архитектура Blackwell никуда не делась, и второе решение в линейке предлагает те же улучшения, но практически все они не скажутся на вашем пользовательском опыте прямо сегодня или даже в ближайшее время. Улучшенную технологию DLSS 4 точно можно считать достоинством Blackwell, и не только многокадровую генерацию (которая работает неплохо при достаточно высоком уровне «честной» производительности), но и новую модель ИИ с лучшим качеством, хотя она работает и на GPU предыдущих поколений тоже. Улучшения и нововведения вроде нейрорендеринга и мегагеометрии интересны и перспективны, но их на GeForce RTX 5080 мы вряд ли увидим достаточно скоро, а заплатить-то придется сразу. Ждем, пока эти возможности появятся в DirectX и будут поддержаны остальными участниками рынка и, что даже еще важнее, игровыми консолями. Впрочем, отдельные разработчики игр могут внедрить некоторые из предложенных Nvidia технологий раньше этого, и мы очень на это надеемся.
Нейронный рендеринг уже сейчас помогает улучшать качество изображения или увеличивать производительность при некотором застое в полупроводниковых производствах. Технологии масштабирования и генерации кадров DLSS увеличили частоту кадров, обеспечивая высокое качество изображения при генерации большинства пикселей не традиционным рендерингом, а при помощи искусственного интеллекта. Технология реконструкции лучей Ray Reconstruction сокращает количество лучей, требуемое для создания высококачественных изображений с трассировкой лучей, используя продвинутые шумоподавление и реконструкцию недостающих деталей. Технологии ИИ продолжают улучшаться и дальше, качество рендеринга растет при снижении вычислительных затрат и требуемого объема памяти, по сравнению с обычными методами. Технологии нейронного рендеринга в Blackwell способны ускорить использование возможностей ИИ разработчиками, включая использование рендеринга и моделирования на основе генеративного ИИ в реальном времени. Генеративный ИИ поможет в создании ландшафтов и сложных сцен, реализации более реалистичных физических симуляций, имитации более сложного поведения игровых персонажей. Для рендеринга человеческих лиц целиком можно использовать полноценный генеративный искусственный интеллект, да и профессиональные приложения для 3D-дизайна могут использовать возможности генеративного ИИ в Blackwell для того, чтобы ускорить рабочие процессы при создании разнообразного контента. Но всё это лишь в перспективе.
Конкретная протестированная карта Palit GeForce RTX 5080 GameRock (16 ГБ) имеет ожидаемо крупные размеры 33×15 см, занимая 4 слота в системном блоке. Использованная СО умеренно тихая, карта может потреблять до 350 Вт (официальный лимит Nvidia — 360 Вт) и имеет один 16-контактный разъем питания 12VHPWR (PCIe 5.0). У карты 4 видеовыхода: 1 HDMI 2.1b и 3 DisplayPort 2.1b — последний обеспечивает пропускную способность до 80 Гбит/с в режиме передачи UHBR 20 и позволяет подключить 8K-дисплей с частотой обновления 60 Гц по одному кабелю. Карта снабжена роскошным кожухом СО, названным производителем «хамелеоном», который впечатляет даже без подсветки, а с последней — вообще очень красив, причем без «цыганщины», в которой обвиняли предыдущий вариант СО серии GameRock с кристаллами на кожухе. У визуальной стороны этого решения есть лишь один минус — сильно контрастирующие черные круги вентиляторов: как минимум лопасти надо было сделать полупрозрачными, чтобы часть свечения подсветки попадала на них.
Можно также похвалить компанию Palit за комплект поставки, где кроме видеокарты имеются переходник питания, адаптер для синхронизации подсветки, прикручиваемая к карте раздвижная подставка, бонусные стикеры и коврик для мыши.
Отметим еще раз, что GeForce RTX 5080 будет обеспечивать отменный комфорт во всех играх на максимальных настройках качества при отключенных и включенных трассировке лучей и технологиях масштабирования в разрешениях до 2160p (4K) включительно. В ряде игр при использовании тех же технологий DLSS/FSR/XeSS можно получить приличный комфорт и в разрешении 8K.

В номинации «Оригинальный дизайн» карта Palit GeForce RTX 5080 GameRock (16 ГБ) получила награду:



